



Hardware components | ||||||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
| ||||||
| ||||||
| ||||||
 |
| |||||
Creating 3D models from scratch is a time-consuming and complex process that typically requires specialized skills and software. Many users find it challenging to bring their creative visions to life due to the steep learning curve associated with traditional 3D modeling tools. Additionally, the need for rapid prototyping and visualization in various industries underscores the demand for more efficient and accessible 3D modeling solutions.
DreamVision addresses these challenges by simplifying the 3D model creation process. Users can easily generate 3D models by either uploading an image or providing a text description. This eliminates the need for extensive technical knowledge and reduces the time required to produce high-quality 3D models.
DreamVision is a fullstack application that include a client create in react that be either hosted on a cloud platform or run locally. A backend build with FASTAPI that include a conglomerate of open source 3D generator model that been modified and optimize to run on AMD Pro W7900 GPU with ROCM 6.1. Dreamvision come with 3 different mode for user to choose from:
- Text-to-3D : This mode allow user to input text to generate an image. Then the model will use the generated image to generate the equivalent 3D model.
- Image-to-3D: User input an image to generate a equivalent 3D model
User can run DreamVision by building it locally
First clone the repo
git clone https://github.com/vpvypham1994/DreamVisionChange directory into the repo
cd DreamvisionInstall the require react dependencies for react app
npm installInstall python dependencies
pip install -r backend/requirements.txtRun both the frontend and backend
./run.shDreamVision come with a modern stylish user interface that easily allow user to generate 3D model assets at a click of the button. Instead of explaining how to do, below is a demo video of DreamVision.
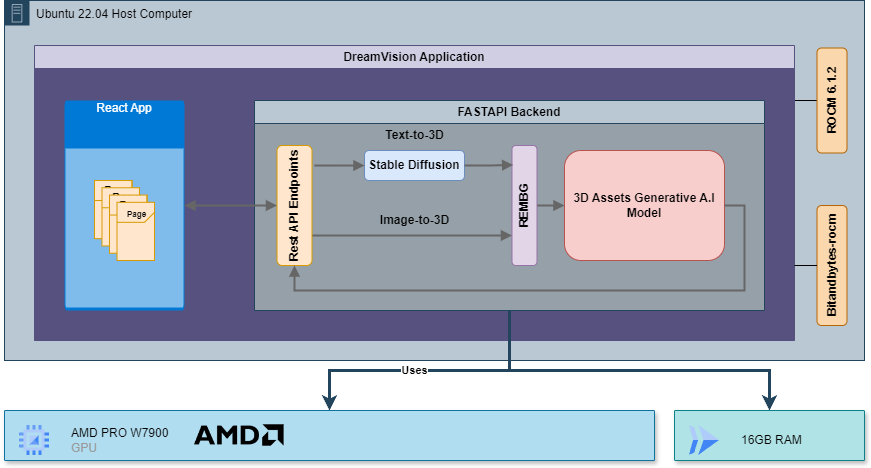
The DreamVision system architecture is based on a client-server model, utilizing a React client and FASTAPI servers. The React client enables users to select various generative modes and upload their data. Based on the user inputs, the client makes API calls to the server endpoints. The server listens for these endpoints and, upon activation, runs one of its multiple 3D model generation routines. This process leverages a generative AI in the background to create the 3D models, which are then sent back to the client for user access.
This architecture ensures a seamless user experience by efficiently handling requests and generating high-quality 3D models in response to user inputs.
The client architecture sets up a React application with a sidebar for navigation, routing to different pages, and Axios for making API calls. Each component is modular and can be expanded upon as needed. This structure provides a scalable and maintainable foundation for developing complex web applications.
The backend-server architecture involves a client-server setup where the FastAPI framework handles HTTP requests. The server is configured with middleware for CORS and uses several libraries for file handling, asynchronous operations, and AI model integration. The architecture includes endpoints for image-to-3D and text-to-3D
- Image-to-3D : This endpoint work by receiving an png or jpeg file and feed it into a background remover (REMBG). The new image without background is then use by Dreamvision 3D Asset Generative A.I Model to convert the image to 3D object in.glb format and send it back to the client interface.
- Text-to-3D: In Text-to-3D endpoint, the backend receive a prompt to generate an image with Stable Diffusion. The image is send back to the client interface for to let the user to either regenerate the image or create a 3D model out of it. Once the user happy with the image they have, the user will click the generate model button to generate a 3D model. This process is the same as the Image-to-3D endpoint.
Additionally, the system uses a ThreadPoolExecutor for handling background tasks and serves static files from a specified directory. This setup ensures efficient and scalable processing of user inputs to generate 3D models and images.
Dreamvision 3D Assets generator use a combination of well know techniques and architecture from previous 3D Model generator. Each stages of the model is describe below:
- Multiview Diffusion Model : First, the model take an input image and generate multiple images that represent different view of the source images:
- VIT Encoder: The VIT (Vision Transformer) takes the multiview-images and converts them into a series of image tokens that can be used for further processing in the transformer-based architecture.
- Image Tokens: Image tokens are the output of the VIT encoder and represent different parts or aspects of the input image in a form that the transformer model can process.
- Triplane Decoder: The triplane decoder uses these tokens to reconstruct the 3D mesh, making it possible to generate detailed and accurate 3D models from the input images.
- Triplane Upsampler: This component take the triplane result from the Triplane Decoder and enhances the resolution and quality of the triplane representation used in the model.
- Triplane: These are the result after the Triplane Upsampler step. A triplane, in the context of 3D reconstruction and generative models, is a type of 3D representation used to encode the geometry and appearance of an object.
- Flexicubes : FlexiCubes help the model create detailed 3D shapes by extracting the surface of the object efficiently and allowing for high-quality training with detailed geometric information like depth and surface texture.
- Render:The final step the convert the 3D shapes and triplane representation into solid 3D mesh in.glb format
To optimize a 3D model generator using the AMD GPU Pro W7900, consider the following strategies:
1.Leverage AMD ROCm (Radeon Open Compute)
- Utilize ROCm for a flexible platform that supports high-performance computing and AI workloads.
- Ensure your software is compatible with ROCm to fully exploit the capabilities of AMD hardware.
- Optimize memory usage by carefully managing the VRAM footprint.
- Implement techniques like triplane channel optimization and efficient data structures to better manage memory.
- Enhance the speed of 3D model generation by using multi-threading and parallel processing.
- Utilize tools such as ThreadPoolExecutor to manage parallel tasks effectively in the backend.
- Implement algorithmic improvements to boost performance on AMD GPUs.
- Consider techniques like mask supervision and efficient crop rendering strategies, similar to those used in DreamVision, to enhance the model's efficiency and output quality.
The DreamVision model incorporates several training process improvements to enhance both efficiency and performance. It optimizes the triplane channel configuration to balance computational cost and reconstruction quality, incorporates a mask loss function to reduce artifacts and improve fidelity, and uses a local rendering supervision strategy that emphasizes foreground regions, allowing for high-resolution learning while managing GPU memory load. These enhancements collectively lead to more detailed and accurate 3D reconstructions.
In addition, Dreamvision training data is a high-quality curated subset from the Objaverse dataset, ensuring better quality and more diverse training samples. Additionally, the model employs advanced data rendering techniques that mimic real-world image distributions, which significantly improves the model's generalization capabilities.
I am looking to enhance the capabilities of DreamVision 3D model generation with the following features:
- Texture Generation: Enable the generation of various textures based on user descriptions.
- 3D Model Enhancement: Improve user-provided 3D meshes by adding more details and repairing missing parts.
- Detailed Mesh Generation: Produce high-quality meshes derived from images or textual descriptions.
- 3D Inpainting: Allow users to modify specific parts of a model based on textual input.
These enhancements will significantly improve the versatility and quality of DreamVision's 3D model generation capabilities.
1. InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models. Link
2.High-Resolution Image Synthesis with Latent Diffusion Models. Link
3.High-Quality and Efficient 3D Mesh Generation from a Single Image. Link



{kind=link}
Comments
Please log in or sign up to comment.