



Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
The aim of this project it to create a simple GUI (Graphical User Interface) for Amazon’s voice assistant Alexa.
This project was initially published in my blog: http://youness.net/alexa/amazon-alexa-gui
Why Alexa GUI? In my opinion, GUI remains an essential part of any interaction between humans and machines, especially for systems with voice input, and this can be observed for example when people look at Echo device while talking to Alexa. So headless voice assistants are just like talking in the dark, uncomfortable without feedback of what the system is doing.
I did two choices:
- To do it in Python: Since I’m using the python client AlexaPi done for Raspberry Pi.
- To do it with external LCD display, instead of internal python libraries (e.g. PyQt, …)
If you want to build AlexaPi, please use its tutorial.
BOM (doesn't include parts for AlexaPi) :
- Raspberry Pi 3
- 128×64 OLED LCD LED SSD1306
- Breadboard + wires (male/female)
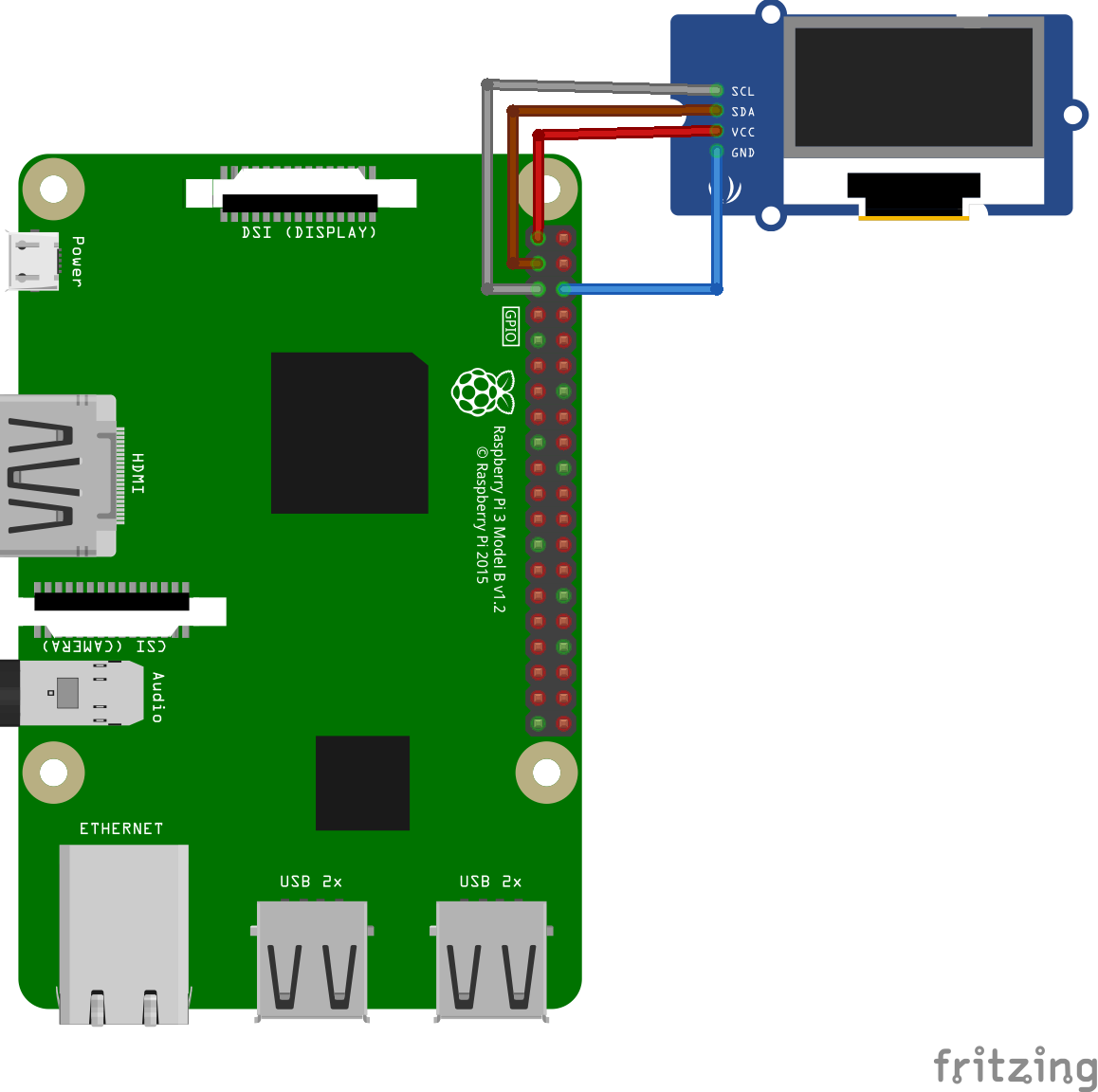
Hardware part: It uses I2C bus of Raspberry Pi, meaning two wires (SDA, SCL) + power supply:
- VCC (3V3) -> GPIO 1
- GND (0V) -> GPIO 6
- SDA -> GPIO 3
- SCL -> GPIO 5
Software part: I’m using Adafruit library, it works like a charm. I’m also following their instructions here : SSD1306 OLED Displays with Raspberry Pi.
Install needed tools and libraries: sudo apt-get update sudo apt-get install build-essential python-dev python-pip sudo apt-get install python-imaging python-smbus sudo apt-get install i2c-tools sudo pip install Adafruit_BBIO
Install SSD1306 library: git clone https://github.com/adafruit/Adafruit_Python_SSD1306.git cd Adafruit_Python_SSD1306 sudo python setup.py install
Check if I2C is enabled: sudo i2cdetect -y 1
If not, enable it in Raspi-config.
Also turn on I2C in boot configuration: sudo nano /boot/config.txt
, and add (or uncomment):
dtparam=i2c1=on
dtparam=i2c_arm=on
Reboot.
Run image example: python image.py
You should see image on the OLED display.
Step 2: Define Alexa states + imagesI define the main states of Alexa as follow:
- Alexa Not Started (Raspberry Pi logo)
- Alexa Started (Alexa logo)
- Alexa Listening (Microphone)
- Alexa Talking (Speaker)
- Alexa Busy (Sand watch)
- Alexa Not Connected (Cloud NOK)
For each state, I create a 128×64 black and white .png image. I make in white (or grey) the parts that I want to be in blue (Good coincidence since it is Alexa color)
Here is an example of the displayed state.
Duplicate original main.py cp main.py gui.py
Make it executable: chmod +x gui.py
After import part, we add AlexaGUI setup: sudo nano gui.py
I add these lines: #AlexaGUI setup import Adafruit_SSD1306 from PIL import Image RST = 24 disp = Adafruit_SSD1306.SSD1306_128_64(rst=RST) global img
At the end (before the main), I define new function: def AlexaGUI(img): image = Image.open(img).convert(‘1’) disp.image(image) disp.display()
So, anytime I want to show something, I add just the line: AlexaGUI(image.png)
image.png to be changed with the real names.
In the setup(), I initiate the display: #AlexaGUI init disp.begin() disp.clear()
And just after I display Alexa logo: AlexaGUI(‘Alexa.png’)
You can download the gui.py file here: gui.txt
Here is a demo of the code showing 3 states of Alexa (Listening, processing and answering)
This is a difficult part for me, since I’m not a designer, and I’m using only MS Paint to edit the pictures.
So I do the animation of the speaker, by just playing with the bar levels and making 4 different .png that I show successively with a small delay (10ms):
Here is the demo:
Compared to the first demo, the improvement is noticeable, but still mechanical.So later I added other animations for microphone, Alexa thinking and speaking.
The best to do for the speaker is to mimic Alexa voice (like Hi-Fi displays), but it is an advanced feature…
For the moment I’m not doing the animation for all states. I want now to customize Alexa depending on the intent, for example when she’s saying a joke.
To be continued…
#! /usr/bin/env python
import os
import random
import time
import RPi.GPIO as GPIO
import alsaaudio
import wave
import random
from creds import *
import requests
import json
import re
from memcache import Client
import vlc
import threading
import cgi
import email
#AlexaGUI setup
import Adafruit_SSD1306
from PIL import Image
RST = 24
disp = Adafruit_SSD1306.SSD1306_128_64(rst=RST)
global img
#Settings
button = 18 # GPIO Pin with button connected
plb_light = 24 # GPIO Pin for the playback/activity light
rec_light = 25 # GPIO Pin for the recording light
lights = [plb_light, rec_light] # GPIO Pins with LED's connected
device = "plughw:1" # Name of your microphone/sound card in arecord -L
#Setup
recorded = False
servers = ["127.0.0.1:11211"]
mc = Client(servers, debug=1)
path = os.path.realpath(__file__).rstrip(os.path.basename(__file__))
#Variables
p = ""
nav_token = ""
streamurl = ""
streamid = ""
position = 0
audioplaying = False
#Debug
debug = 1
class bcolors:
HEADER = '\033[95m'
OKBLUE = '\033[94m'
OKGREEN = '\033[92m'
WARNING = '\033[93m'
FAIL = '\033[91m'
ENDC = '\033[0m'
BOLD = '\033[1m'
UNDERLINE = '\033[4m'
def internet_on():
print("Checking Internet Connection...")
try:
r =requests.get('https://api.amazon.com/auth/o2/token')
print("Connection {}OK{}".format(bcolors.OKGREEN, bcolors.ENDC))
return True
except:
print("Connection {}Failed{}".format(bcolors.WARNING, bcolors.ENDC))
return False
def gettoken():
token = mc.get("access_token")
refresh = refresh_token
if token:
return token
elif refresh:
payload = {"client_id" : Client_ID, "client_secret" : Client_Secret, "refresh_token" : refresh, "grant_type" : "refresh_token", }
url = "https://api.amazon.com/auth/o2/token"
r = requests.post(url, data = payload)
resp = json.loads(r.text)
mc.set("access_token", resp['access_token'], 3570)
return resp['access_token']
else:
return False
def alexa_speech_recognizer():
# https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/rest/speechrecognizer-requests
if debug: print("{}Sending Speech Request...{}".format(bcolors.OKBLUE, bcolors.ENDC))
GPIO.output(plb_light, GPIO.HIGH)
url = 'https://access-alexa-na.amazon.com/v1/avs/speechrecognizer/recognize'
headers = {'Authorization' : 'Bearer %s' % gettoken()}
d = {
"messageHeader": {
"deviceContext": [
{
"name": "playbackState",
"namespace": "AudioPlayer",
"payload": {
"streamId": "",
"offsetInMilliseconds": "0",
"playerActivity": "IDLE"
}
}
]
},
"messageBody": {
"profile": "alexa-close-talk",
"locale": "en-us",
"format": "audio/L16; rate=16000; channels=1"
}
}
with open(path+'recording.wav') as inf:
files = [
('file', ('request', json.dumps(d), 'application/json; charset=UTF-8')),
('file', ('audio', inf, 'audio/L16; rate=16000; channels=1'))
]
r = requests.post(url, headers=headers, files=files)
process_response(r)
def alexa_getnextitem(nav_token):
# https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/rest/audioplayer-getnextitem-request
time.sleep(0.5)
if audioplaying == False:
if debug: print("{}Sending GetNextItem Request...{}".format(bcolors.OKBLUE, bcolors.ENDC))
GPIO.output(plb_light, GPIO.HIGH)
url = 'https://access-alexa-na.amazon.com/v1/avs/audioplayer/getNextItem'
headers = {'Authorization' : 'Bearer %s' % gettoken(), 'content-type' : 'application/json; charset=UTF-8'}
d = {
"messageHeader": {},
"messageBody": {
"navigationToken": nav_token
}
}
r = requests.post(url, headers=headers, data=json.dumps(d))
process_response(r)
def alexa_playback_progress_report_request(requestType, playerActivity, streamid):
# https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/rest/audioplayer-events-requests
# streamId Specifies the identifier for the current stream.
# offsetInMilliseconds Specifies the current position in the track, in milliseconds.
# playerActivity IDLE, PAUSED, or PLAYING
if debug: print("{}Sending Playback Progress Report Request...{}".format(bcolors.OKBLUE, bcolors.ENDC))
headers = {'Authorization' : 'Bearer %s' % gettoken()}
d = {
"messageHeader": {},
"messageBody": {
"playbackState": {
"streamId": streamid,
"offsetInMilliseconds": 0,
"playerActivity": playerActivity.upper()
}
}
}
if requestType.upper() == "ERROR":
# The Playback Error method sends a notification to AVS that the audio player has experienced an issue during playback.
url = "https://access-alexa-na.amazon.com/v1/avs/audioplayer/playbackError"
elif requestType.upper() == "FINISHED":
# The Playback Finished method sends a notification to AVS that the audio player has completed playback.
url = "https://access-alexa-na.amazon.com/v1/avs/audioplayer/playbackFinished"
elif requestType.upper() == "IDLE":
# The Playback Idle method sends a notification to AVS that the audio player has reached the end of the playlist.
url = "https://access-alexa-na.amazon.com/v1/avs/audioplayer/playbackIdle"
elif requestType.upper() == "INTERRUPTED":
# The Playback Interrupted method sends a notification to AVS that the audio player has been interrupted.
# Note: The audio player may have been interrupted by a previous stop Directive.
url = "https://access-alexa-na.amazon.com/v1/avs/audioplayer/playbackInterrupted"
elif requestType.upper() == "PROGRESS_REPORT":
# The Playback Progress Report method sends a notification to AVS with the current state of the audio player.
url = "https://access-alexa-na.amazon.com/v1/avs/audioplayer/playbackProgressReport"
elif requestType.upper() == "STARTED":
# The Playback Started method sends a notification to AVS that the audio player has started playing.
url = "https://access-alexa-na.amazon.com/v1/avs/audioplayer/playbackStarted"
r = requests.post(url, headers=headers, data=json.dumps(d))
if r.status_code != 204:
print("{}(alexa_playback_progress_report_request Response){} {}".format(bcolors.WARNING, bcolors.ENDC, r))
else:
if debug: print("{}Playback Progress Report was {}Successful!{}".format(bcolors.OKBLUE, bcolors.OKGREEN, bcolors.ENDC))
def process_response(r):
global nav_token, streamurl, streamid
if debug: print("{}Processing Request Response...{}".format(bcolors.OKBLUE, bcolors.ENDC))
nav_token = ""
streamurl = ""
streamid = ""
if r.status_code == 200:
data = "Content-Type: " + r.headers['content-type'] +'\r\n\r\n'+ r.content
msg = email.message_from_string(data)
for payload in msg.get_payload():
if payload.get_content_type() == "application/json":
j = json.loads(payload.get_payload())
if debug: print("{}JSON String Returned:{} {}".format(bcolors.OKBLUE, bcolors.ENDC, json.dumps(j)))
elif payload.get_content_type() == "audio/mpeg":
filename = path + "tmpcontent/"+payload.get('Content-ID').strip("<>")+".mp3"
with open(filename, 'wb') as f:
f.write(payload.get_payload())
else:
if debug: print("{}NEW CONTENT TYPE RETURNED: {} {}".format(bcolors.WARNING, bcolors.ENDC, payload.get_content_type()))
# Now process the response
if 'directives' in j['messageBody']:
if len(j['messageBody']['directives']) == 0:
GPIO.output(rec_light, GPIO.LOW)
GPIO.output(plb_light, GPIO.LOW)
for directive in j['messageBody']['directives']:
if directive['namespace'] == 'SpeechSynthesizer':
if directive['name'] == 'speak':
GPIO.output(rec_light, GPIO.LOW)
play_audio(path + "tmpcontent/"+directive['payload']['audioContent'].lstrip("cid:")+".mp3")
elif directive['name'] == 'listen':
#listen for input - need to implement silence detection for this to be used.
if debug: print("{}Further Input Expected, timeout in: {} {}ms".format(bcolors.OKBLUE, bcolors.ENDC, directive['payload']['timeoutIntervalInMillis']))
elif directive['namespace'] == 'AudioPlayer':
#do audio stuff - still need to honor the playBehavior
if directive['name'] == 'play':
nav_token = directive['payload']['navigationToken']
for stream in directive['payload']['audioItem']['streams']:
if stream['progressReportRequired']:
streamid = stream['streamId']
playBehavior = directive['payload']['playBehavior']
if stream['streamUrl'].startswith("cid:"):
content = path + "tmpcontent/"+stream['streamUrl'].lstrip("cid:")+".mp3"
else:
content = stream['streamUrl']
pThread = threading.Thread(target=play_audio, args=(content, stream['offsetInMilliseconds']))
pThread.start()
elif 'audioItem' in j['messageBody']: #Additional Audio Iten
nav_token = j['messageBody']['navigationToken']
for stream in j['messageBody']['audioItem']['streams']:
if stream['progressReportRequired']:
streamid = stream['streamId']
if stream['streamUrl'].startswith("cid:"):
content = path + "tmpcontent/"+stream['streamUrl'].lstrip("cid:")+".mp3"
else:
content = stream['streamUrl']
pThread = threading.Thread(target=play_audio, args=(content, stream['offsetInMilliseconds']))
pThread.start()
return
elif r.status_code == 204:
GPIO.output(rec_light, GPIO.LOW)
for x in range(0, 3):
time.sleep(.2)
GPIO.output(plb_light, GPIO.HIGH)
time.sleep(.2)
GPIO.output(plb_light, GPIO.LOW)
if debug: print("{}Request Response is null {}(This is OKAY!){}".format(bcolors.OKBLUE, bcolors.OKGREEN, bcolors.ENDC))
else:
print("{}(process_response Error){} Status Code: {}".format(bcolors.WARNING, bcolors.ENDC, r.status_code))
r.connection.close()
GPIO.output(lights, GPIO.LOW)
for x in range(0, 3):
time.sleep(.2)
GPIO.output(rec_light, GPIO.HIGH)
time.sleep(.2)
GPIO.output(lights, GPIO.LOW)
def tuneinplaylist(url):
req = requests.get(url)
r = requests.get(req.content)
for line in r.content.split('\n'):
if line.startswith('File'):
list = line.split("=")[1:]
nurl = "=".join(list)
return nurl
def play_audio(file, offset=0):
if file.startswith('http://opml.radiotime.com'):
file = tuneinplaylist(file)
global nav_token, p, audioplaying
if debug: print("{}Play_Audio Request for:{} {}".format(bcolors.OKBLUE, bcolors.ENDC, file))
GPIO.output(plb_light, GPIO.HIGH)
i = vlc.Instance('--aout=alsa')
m = i.media_new(file)
p = i.media_player_new()
p.set_media(m)
mm = m.event_manager()
mm.event_attach(vlc.EventType.MediaStateChanged, state_callback, p)
audioplaying = True
p.audio_set_volume(100)
p.play()
AlexaGUI('Speaking.png')
while audioplaying:
continue
GPIO.output(plb_light, GPIO.LOW)
AlexaGUI('Talking.png')
def state_callback(event, player):
global nav_token, audioplaying, streamurl, streamid
state = player.get_state()
#0: 'NothingSpecial'
#1: 'Opening'
#2: 'Buffering'
#3: 'Playing'
#4: 'Paused'
#5: 'Stopped'
#6: 'Ended'
#7: 'Error'
if debug: print("{}Player State:{} {}".format(bcolors.OKGREEN, bcolors.ENDC, state))
if state == 3: #Playing
if streamid != "":
rThread = threading.Thread(target=alexa_playback_progress_report_request, args=("STARTED", "PLAYING", streamid))
rThread.start()
elif state == 5: #Stopped
audioplaying = False
if streamid != "":
rThread = threading.Thread(target=alexa_playback_progress_report_request, args=("INTERRUPTED", "IDLE", streamid))
rThread.start()
streamurl = ""
streamid = ""
nav_token = ""
elif state == 6: #Ended
audioplaying = False
if streamid != "":
rThread = threading.Thread(target=alexa_playback_progress_report_request, args=("FINISHED", "IDLE", streamid))
rThread.start()
streamid = ""
if streamurl != "":
pThread = threading.Thread(target=play_audio, args=(streamurl,))
streamurl = ""
pThread.start()
elif nav_token != "":
gThread = threading.Thread(target=alexa_getnextitem, args=(nav_token,))
gThread.start()
elif state == 7:
audioplaying = False
if streamid != "":
rThread = threading.Thread(target=alexa_playback_progress_report_request, args=("ERROR", "IDLE", streamid))
rThread.start()
streamurl = ""
streamid = ""
nav_token = ""
def meta_callback(event, media):
title = media.get_meta(vlc.Meta.Title)
artist = media.get_meta(vlc.Meta.Artist)
album = media.get_meta(vlc.Meta.Album)
tracknumber = media.get_meta(vlc.Meta.TrackNumber)
url = media.get_meta(vlc.Meta.URL)
nowplaying = media.get_meta(vlc.Meta.NowPlaying)
print('{}Title:{} {}'.format(bcolors.OKBLUE, bcolors.ENDC, title))
print('{}Artist:{} {}'.format(bcolors.OKBLUE, bcolors.ENDC, artist))
print('{}Album:{} {}'.format(bcolors.OKBLUE, bcolors.ENDC, album))
print('{}Track:{} {}'.format(bcolors.OKBLUE, bcolors.ENDC, tracknumber))
print('{}Url:{} {}'.format(bcolors.OKBLUE, bcolors.ENDC, url))
print('{}Now Playing:{} {}'.format(bcolors.OKBLUE, bcolors.ENDC, nowplaying))
def pos_callback(event):
global position
position = event.u.new_time
if debug: print("{}Player Position:{} {}".format(bcolors.OKBLUE, bcolors.ENDC, format_time(position)))
def format_time(self, milliseconds):
"""formats milliseconds to h:mm:ss
"""
self.position = milliseconds / 1000
m, s = divmod(self.position, 60)
h, m = divmod(m, 60)
return "%d:%02d:%02d" % (h, m, s)
def start():
global audioplaying, p
while True:
print("{}Ready to Record.{}".format(bcolors.OKBLUE, bcolors.ENDC))
GPIO.wait_for_edge(button, GPIO.FALLING) # we wait for the button to be pressed
if audioplaying: p.stop()
print("{}Recording...{}".format(bcolors.OKBLUE, bcolors.ENDC))
GPIO.output(rec_light, GPIO.HIGH)
inp = alsaaudio.PCM(alsaaudio.PCM_CAPTURE, alsaaudio.PCM_NORMAL, device)
inp.setchannels(1)
inp.setrate(16000)
inp.setformat(alsaaudio.PCM_FORMAT_S16_LE)
inp.setperiodsize(500)
audio = ""
while(GPIO.input(button)==0): # we keep recording while the button is pressed
l, data = inp.read()
if l:
audio += data
print("{}Recording Finished.{}".format(bcolors.OKBLUE, bcolors.ENDC))
rf = open(path+'recording.wav', 'w')
rf.write(audio)
rf.close()
inp = None
AlexaGUI('Waiting.png')
alexa_speech_recognizer()
def setup():
GPIO.setwarnings(False)
GPIO.cleanup()
GPIO.setmode(GPIO.BCM)
GPIO.setup(button, GPIO.IN, pull_up_down=GPIO.PUD_UP)
GPIO.setup(lights, GPIO.OUT)
GPIO.output(lights, GPIO.LOW)
#AlexaGUI init
disp.begin()
disp.clear()
AlexaGUI('Alexa.png')
while internet_on() == False:
AlexaGUI('ConnectionKO.png')
print(".")
token = gettoken()
if token == False:
while True:
for x in range(0, 5):
time.sleep(.1)
GPIO.output(rec_light, GPIO.HIGH)
time.sleep(.1)
GPIO.output(rec_light, GPIO.LOW)
for x in range(0, 5):
time.sleep(.1)
GPIO.output(plb_light, GPIO.HIGH)
time.sleep(.1)
GPIO.output(plb_light, GPIO.LOW)
play_audio(path+"hello.mp3")
def AlexaGUI(img):
image = Image.open(img).convert('1')
disp.image(image)
disp.display()
if __name__ == "__main__":
setup()
start()
#! /usr/bin/env python
import os
import random
import time
import RPi.GPIO as GPIO
import alsaaudio
import wave
import random
from creds import *
import requests
import json
import re
from memcache import Client
import vlc
import threading
import cgi
import email
#AlexaGUI setup
import Adafruit_SSD1306
from PIL import Image
RST = 24
disp = Adafruit_SSD1306.SSD1306_128_64(rst=RST)
global img
#Settings
button = 18 # GPIO Pin with button connected
plb_light = 24 # GPIO Pin for the playback/activity light
rec_light = 25 # GPIO Pin for the recording light
lights = [plb_light, rec_light] # GPIO Pins with LED's connected
device = "plughw:1" # Name of your microphone/sound card in arecord -L
#Setup
recorded = False
servers = ["127.0.0.1:11211"]
mc = Client(servers, debug=1)
path = os.path.realpath(__file__).rstrip(os.path.basename(__file__))
#Variables
p = ""
nav_token = ""
streamurl = ""
streamid = ""
position = 0
audioplaying = False
#Debug
debug = 1
class bcolors:
HEADER = '\033[95m'
OKBLUE = '\033[94m'
OKGREEN = '\033[92m'
WARNING = '\033[93m'
FAIL = '\033[91m'
ENDC = '\033[0m'
BOLD = '\033[1m'
UNDERLINE = '\033[4m'
def internet_on():
print("Checking Internet Connection...")
try:
r =requests.get('https://api.amazon.com/auth/o2/token')
print("Connection {}OK{}".format(bcolors.OKGREEN, bcolors.ENDC))
return True
except:
print("Connection {}Failed{}".format(bcolors.WARNING, bcolors.ENDC))
return False
def gettoken():
token = mc.get("access_token")
refresh = refresh_token
if token:
return token
elif refresh:
payload = {"client_id" : Client_ID, "client_secret" : Client_Secret, "refresh_token" : refresh, "grant_type" : "refresh_token", }
url = "https://api.amazon.com/auth/o2/token"
r = requests.post(url, data = payload)
resp = json.loads(r.text)
mc.set("access_token", resp['access_token'], 3570)
return resp['access_token']
else:
return False
def alexa_speech_recognizer():
# https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/rest/speechrecognizer-requests
if debug: print("{}Sending Speech Request...{}".format(bcolors.OKBLUE, bcolors.ENDC))
GPIO.output(plb_light, GPIO.HIGH)
url = 'https://access-alexa-na.amazon.com/v1/avs/speechrecognizer/recognize'
headers = {'Authorization' : 'Bearer %s' % gettoken()}
d = {
"messageHeader": {
"deviceContext": [
{
"name": "playbackState",
"namespace": "AudioPlayer",
"payload": {
"streamId": "",
"offsetInMilliseconds": "0",
"playerActivity": "IDLE"
}
}
]
},
"messageBody": {
"profile": "alexa-close-talk",
"locale": "en-us",
"format": "audio/L16; rate=16000; channels=1"
}
}
with open(path+'recording.wav') as inf:
files = [
('file', ('request', json.dumps(d), 'application/json; charset=UTF-8')),
('file', ('audio', inf, 'audio/L16; rate=16000; channels=1'))
]
r = requests.post(url, headers=headers, files=files)
process_response(r)
def alexa_getnextitem(nav_token):
# https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/rest/audioplayer-getnextitem-request
time.sleep(0.5)
if audioplaying == False:
if debug: print("{}Sending GetNextItem Request...{}".format(bcolors.OKBLUE, bcolors.ENDC))
GPIO.output(plb_light, GPIO.HIGH)
url = 'https://access-alexa-na.amazon.com/v1/avs/audioplayer/getNextItem'
headers = {'Authorization' : 'Bearer %s' % gettoken(), 'content-type' : 'application/json; charset=UTF-8'}
d = {
"messageHeader": {},
"messageBody": {
"navigationToken": nav_token
}
}
r = requests.post(url, headers=headers, data=json.dumps(d))
process_response(r)
def alexa_playback_progress_report_request(requestType, playerActivity, streamid):
# https://developer.amazon.com/public/solutions/alexa/alexa-voice-service/rest/audioplayer-events-requests
# streamId Specifies the identifier for the current stream.
# offsetInMilliseconds Specifies the current position in the track, in milliseconds.
# playerActivity IDLE, PAUSED, or PLAYING
if debug: print("{}Sending Playback Progress Report Request...{}".format(bcolors.OKBLUE, bcolors.ENDC))
headers = {'Authorization' : 'Bearer %s' % gettoken()}
d = {
"messageHeader": {},
"messageBody": {
"playbackState": {
"streamId": streamid,
"offsetInMilliseconds": 0,
"playerActivity": playerActivity.upper()
}
}
}
if requestType.upper() == "ERROR":
# The Playback Error method sends a notification to AVS that the audio player has experienced an issue during playback.
url = "https://access-alexa-na.amazon.com/v1/avs/audioplayer/playbackError"
elif requestType.upper() == "FINISHED":
# The Playback Finished method sends a notification to AVS that the audio player has completed playback.
url = "https://access-alexa-na.amazon.com/v1/avs/audioplayer/playbackFinished"
elif requestType.upper() == "IDLE":
# The Playback Idle method sends a notification to AVS that the audio player has reached the end of the playlist.
url = "https://access-alexa-na.amazon.com/v1/avs/audioplayer/playbackIdle"
elif requestType.upper() == "INTERRUPTED":
# The Playback Interrupted method sends a notification to AVS that the audio player has been interrupted.
# Note: The audio player may have been interrupted by a previous stop Directive.
url = "https://access-alexa-na.amazon.com/v1/avs/audioplayer/playbackInterrupted"
elif requestType.upper() == "PROGRESS_REPORT":
# The Playback Progress Report method sends a notification to AVS with the current state of the audio player.
url = "https://access-alexa-na.amazon.com/v1/avs/audioplayer/playbackProgressReport"
elif requestType.upper() == "STARTED":
# The Playback Started method sends a notification to AVS that the audio player has started playing.
url = "https://access-alexa-na.amazon.com/v1/avs/audioplayer/playbackStarted"
r = requests.post(url, headers=headers, data=json.dumps(d))
if r.status_code != 204:
print("{}(alexa_playback_progress_report_request Response){} {}".format(bcolors.WARNING, bcolors.ENDC, r))
else:
if debug: print("{}Playback Progress Report was {}Successful!{}".format(bcolors.OKBLUE, bcolors.OKGREEN, bcolors.ENDC))
def process_response(r):
global nav_token, streamurl, streamid
if debug: print("{}Processing Request Response...{}".format(bcolors.OKBLUE, bcolors.ENDC))
nav_token = ""
streamurl = ""
streamid = ""
if r.status_code == 200:
data = "Content-Type: " + r.headers['content-type'] +'\r\n\r\n'+ r.content
msg = email.message_from_string(data)
for payload in msg.get_payload():
if payload.get_content_type() == "application/json":
j = json.loads(payload.get_payload())
if debug: print("{}JSON String Returned:{} {}".format(bcolors.OKBLUE, bcolors.ENDC, json.dumps(j)))
elif payload.get_content_type() == "audio/mpeg":
filename = path + "tmpcontent/"+payload.get('Content-ID').strip("<>")+".mp3"
with open(filename, 'wb') as f:
f.write(payload.get_payload())
else:
if debug: print("{}NEW CONTENT TYPE RETURNED: {} {}".format(bcolors.WARNING, bcolors.ENDC, payload.get_content_type()))
# Now process the response
if 'directives' in j['messageBody']:
if len(j['messageBody']['directives']) == 0:
GPIO.output(rec_light, GPIO.LOW)
GPIO.output(plb_light, GPIO.LOW)
for directive in j['messageBody']['directives']:
if directive['namespace'] == 'SpeechSynthesizer':
if directive['name'] == 'speak':
GPIO.output(rec_light, GPIO.LOW)
play_audio(path + "tmpcontent/"+directive['payload']['audioContent'].lstrip("cid:")+".mp3")
elif directive['name'] == 'listen':
#listen for input - need to implement silence detection for this to be used.
if debug: print("{}Further Input Expected, timeout in: {} {}ms".format(bcolors.OKBLUE, bcolors.ENDC, directive['payload']['timeoutIntervalInMillis']))
elif directive['namespace'] == 'AudioPlayer':
#do audio stuff - still need to honor the playBehavior
if directive['name'] == 'play':
nav_token = directive['payload']['navigationToken']
for stream in directive['payload']['audioItem']['streams']:
if stream['progressReportRequired']:
streamid = stream['streamId']
playBehavior = directive['payload']['playBehavior']
if stream['streamUrl'].startswith("cid:"):
content = path + "tmpcontent/"+stream['streamUrl'].lstrip("cid:")+".mp3"
else:
content = stream['streamUrl']
pThread = threading.Thread(target=play_audio, args=(content, stream['offsetInMilliseconds']))
pThread.start()
elif 'audioItem' in j['messageBody']: #Additional Audio Iten
nav_token = j['messageBody']['navigationToken']
for stream in j['messageBody']['audioItem']['streams']:
if stream['progressReportRequired']:
streamid = stream['streamId']
if stream['streamUrl'].startswith("cid:"):
content = path + "tmpcontent/"+stream['streamUrl'].lstrip("cid:")+".mp3"
else:
content = stream['streamUrl']
pThread = threading.Thread(target=play_audio, args=(content, stream['offsetInMilliseconds']))
pThread.start()
return
elif r.status_code == 204:
GPIO.output(rec_light, GPIO.LOW)
for x in range(0, 3):
time.sleep(.2)
GPIO.output(plb_light, GPIO.HIGH)
time.sleep(.2)
GPIO.output(plb_light, GPIO.LOW)
if debug: print("{}Request Response is null {}(This is OKAY!){}".format(bcolors.OKBLUE, bcolors.OKGREEN, bcolors.ENDC))
else:
print("{}(process_response Error){} Status Code: {}".format(bcolors.WARNING, bcolors.ENDC, r.status_code))
r.connection.close()
GPIO.output(lights, GPIO.LOW)
for x in range(0, 3):
time.sleep(.2)
GPIO.output(rec_light, GPIO.HIGH)
time.sleep(.2)
GPIO.output(lights, GPIO.LOW)
def tuneinplaylist(url):
req = requests.get(url)
r = requests.get(req.content)
for line in r.content.split('\n'):
if line.startswith('File'):
list = line.split("=")[1:]
nurl = "=".join(list)
return nurl
def play_audio(file, offset=0):
if file.startswith('http://opml.radiotime.com'):
file = tuneinplaylist(file)
global nav_token, p, audioplaying
if debug: print("{}Play_Audio Request for:{} {}".format(bcolors.OKBLUE, bcolors.ENDC, file))
GPIO.output(plb_light, GPIO.HIGH)
i = vlc.Instance('--aout=alsa')
m = i.media_new(file)
p = i.media_player_new()
p.set_media(m)
mm = m.event_manager()
mm.event_attach(vlc.EventType.MediaStateChanged, state_callback, p)
audioplaying = True
p.audio_set_volume(100)
p.play()
#AlexaGUI('Speaking.png')
while audioplaying:
AlexaGUI('Speaking1.png')
time.sleep(0.05)
AlexaGUI('Speaking2.png')
time.sleep(0.05)
AlexaGUI('Speaking3.png')
time.sleep(0.05)
AlexaGUI('Speaking4.png')
time.sleep(0.05)
continue
GPIO.output(plb_light, GPIO.LOW)
AlexaGUI('Talking.png')
def state_callback(event, player):
global nav_token, audioplaying, streamurl, streamid
state = player.get_state()
#0: 'NothingSpecial'
#1: 'Opening'
#2: 'Buffering'
#3: 'Playing'
#4: 'Paused'
#5: 'Stopped'
#6: 'Ended'
#7: 'Error'
if debug: print("{}Player State:{} {}".format(bcolors.OKGREEN, bcolors.ENDC, state))
if state == 3: #Playing
if streamid != "":
rThread = threading.Thread(target=alexa_playback_progress_report_request, args=("STARTED", "PLAYING", streamid))
rThread.start()
elif state == 5: #Stopped
audioplaying = False
if streamid != "":
rThread = threading.Thread(target=alexa_playback_progress_report_request, args=("INTERRUPTED", "IDLE", streamid))
rThread.start()
streamurl = ""
streamid = ""
nav_token = ""
elif state == 6: #Ended
audioplaying = False
if streamid != "":
rThread = threading.Thread(target=alexa_playback_progress_report_request, args=("FINISHED", "IDLE", streamid))
rThread.start()
streamid = ""
if streamurl != "":
pThread = threading.Thread(target=play_audio, args=(streamurl,))
streamurl = ""
pThread.start()
elif nav_token != "":
gThread = threading.Thread(target=alexa_getnextitem, args=(nav_token,))
gThread.start()
elif state == 7:
audioplaying = False
if streamid != "":
rThread = threading.Thread(target=alexa_playback_progress_report_request, args=("ERROR", "IDLE", streamid))
rThread.start()
streamurl = ""
streamid = ""
nav_token = ""
def meta_callback(event, media):
title = media.get_meta(vlc.Meta.Title)
artist = media.get_meta(vlc.Meta.Artist)
album = media.get_meta(vlc.Meta.Album)
tracknumber = media.get_meta(vlc.Meta.TrackNumber)
url = media.get_meta(vlc.Meta.URL)
nowplaying = media.get_meta(vlc.Meta.NowPlaying)
print('{}Title:{} {}'.format(bcolors.OKBLUE, bcolors.ENDC, title))
print('{}Artist:{} {}'.format(bcolors.OKBLUE, bcolors.ENDC, artist))
print('{}Album:{} {}'.format(bcolors.OKBLUE, bcolors.ENDC, album))
print('{}Track:{} {}'.format(bcolors.OKBLUE, bcolors.ENDC, tracknumber))
print('{}Url:{} {}'.format(bcolors.OKBLUE, bcolors.ENDC, url))
print('{}Now Playing:{} {}'.format(bcolors.OKBLUE, bcolors.ENDC, nowplaying))
def pos_callback(event):
global position
position = event.u.new_time
if debug: print("{}Player Position:{} {}".format(bcolors.OKBLUE, bcolors.ENDC, format_time(position)))
def format_time(self, milliseconds):
"""formats milliseconds to h:mm:ss
"""
self.position = milliseconds / 1000
m, s = divmod(self.position, 60)
h, m = divmod(m, 60)
return "%d:%02d:%02d" % (h, m, s)
def start():
global audioplaying, p
while True:
print("{}Ready to Record.{}".format(bcolors.OKBLUE, bcolors.ENDC))
GPIO.wait_for_edge(button, GPIO.FALLING) # we wait for the button to be pressed
if audioplaying: p.stop()
print("{}Recording...{}".format(bcolors.OKBLUE, bcolors.ENDC))
GPIO.output(rec_light, GPIO.HIGH)
inp = alsaaudio.PCM(alsaaudio.PCM_CAPTURE, alsaaudio.PCM_NORMAL, device)
inp.setchannels(1)
inp.setrate(16000)
inp.setformat(alsaaudio.PCM_FORMAT_S16_LE)
inp.setperiodsize(500)
audio = ""
while(GPIO.input(button)==0): # we keep recording while the button is pressed
l, data = inp.read()
if l:
audio += data
print("{}Recording Finished.{}".format(bcolors.OKBLUE, bcolors.ENDC))
rf = open(path+'recording.wav', 'w')
rf.write(audio)
rf.close()
inp = None
AlexaGUI('Waiting.png')
alexa_speech_recognizer()
def setup():
GPIO.setwarnings(False)
GPIO.cleanup()
GPIO.setmode(GPIO.BCM)
GPIO.setup(button, GPIO.IN, pull_up_down=GPIO.PUD_UP)
GPIO.setup(lights, GPIO.OUT)
GPIO.output(lights, GPIO.LOW)
#AlexaGUI init
disp.begin()
disp.clear()
AlexaGUI('Alexa.png')
while internet_on() == False:
AlexaGUI('ConnectionKO.png')
print(".")
token = gettoken()
if token == False:
while True:
for x in range(0, 5):
time.sleep(.1)
GPIO.output(rec_light, GPIO.HIGH)
time.sleep(.1)
GPIO.output(rec_light, GPIO.LOW)
for x in range(0, 5):
time.sleep(.1)
GPIO.output(plb_light, GPIO.HIGH)
time.sleep(.1)
GPIO.output(plb_light, GPIO.LOW)
play_audio(path+"hello.mp3")
def AlexaGUI(img):
image = Image.open(img).convert('1')
disp.image(image)
disp.display()
if __name__ == "__main__":
setup()
start()




{kind=link}
Comments
Please log in or sign up to comment.