


Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
| ||||||
 |
| |||||
This project presents our investigation on the hardware inference accelerator design and optimization based on a new class of deep learning model termed as AdderNet. By replacing the computationally intensive convolution (CONV) operations with a sum-of-absolute (SAD) kernel, the massive number of multipliers can be eliminated by cost-effective adder/subtractor circuits, which can result in improved computational throughput given the iso-hardware constraints. We demonstrate a comparative study between a baseline ResNet-20 implementation (CNN-ResNet-20) and two AdderNet design variants (ADD-ResNet-20) over an FPGA device. We have exploited both automatic HLS (High-Level Synthesis) and manual conversion to map the SAD operations onto the FPGA DSP blocks (DSP48E2) of Xilinx Zynq MPSoC. In particular, when the DSP48 block is configured to SIMD (Single Instruction Multiple Data) modes, we can support at least two SAD operations with one DSP block and a minimal amount of LUT logic resources. At this stage of research, we have chosen to use one DSP to support 2 SAD operations, a total of 45.43% DSP utilization reduction can be achieved at the cost of 10% LUT increase and 5% inference time overhead. These results encourage us to explore new deep learning accelerator design strategies towards higher inference throughput with the emerging SAD-kernel-based AdderNet models, as well as aggressive SIMD configurations with ≥4 SADs per DSP.
Convolution neural networks (CNNs) have been widely applied in the fields of computer vision tasks. Such as industrial inspection, autonomous vision, and robotic detection. However, it is hard to deploy those standard neural networks into embedded devices with efficiency throughput and power consumption because of their large number of multiplication operations and parameters. As a solution, AdderNettrades these massive multiplications in deep neural networks, especially convolutional neural networks (CNN), for much cheaper additions to reduce computation costs.
Function.1 CNN
Function.2 ANN
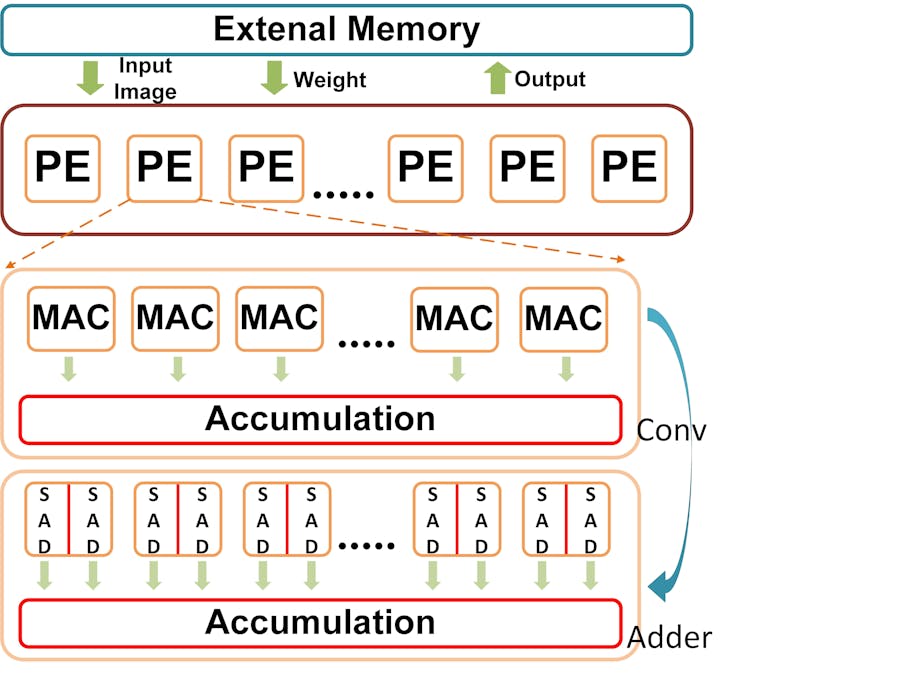
As a case study, we choose ResNet-20-CIFAR10 as a baseline design. The Processing Engine of ResNet-20-CIFAR10 as shown in the Fig.1. To best of our acknowledge, there are two general methods of CNN accelerator: single PE and multiple PEs. In this work, we used multiple PEs in our application for better throughput.
Automatic HLS and manual conversion
Automatic synthesis on Xilinx Vitis HLS:
The Xilinx Vitis HLS can automatically generate FPGA projects from C++ code.
For CNN-ResNet-20, the synthesis report shows that the hardware of this project is as our purposed.
For ADD-ResNet-20, the synthesis report does not follow our previous purpose, because the C synthesis in Vitis HLS does not support configuring DSP48 to SIMD mode.
Our solution:
Design the SAD operation as an independent function in C++.
Replace SAD code in the Verilog source file generated by Xilinx Vitis HLS.
Resynthesis the project in Xilinx Vivado.
Furthermore, by edit the SAD code we can configure DSP48E2 with more options.
Batch Normalization fusion could reduce the computation number and provide a more concise structure for model quantization.
As shown in Function.3 and 4, the refined weight is applied to the convolution layer as the original inference. But consider the function of the Adder layer shows on the left, the refined weight added into the function as convolution is not working as a convolution layer.
This function can not provide the hardware advantage of AdderNet because of the overhead of multiplication and addition.
To avoid this overhead, we use an extra for loop to deal with the overhead of multiplication and addition, which will cost more clock cycles and hardware.
DSP configuration method
In this section, two of the DSP48E2 configuration methods will be presented:
Method a: Leverage the same amount of DSP as CONV, but fewer LUTs compared to Method b.
Method b: Leverage half amount of DSP as CONV, but more LUTs compared to Method a.
This report shows that our method can lead to approximately 45% DSP utilization reduction at the cost of 10% LUT increase and 5% inference time overhead in total by comparing the result of solution a, solution b, and ResNet-20 baseline.




{kind=link}
Comments
Please log in or sign up to comment.