


Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
.png?auto=compress%2Cformat&w=48&h=48&fit=fill&bg=ffffff) |
| |||||
Issue: The fire fighting squad faces many challenge with regards to lack of manpower and reduction in the effective fighting power of the squad. In recent times, challenges include increasing city population, more complex densely populated buildings and pandemic-related measures. Therefore, to augment the firefighting crew to quickly respond to fire incidents, it is proposed that a video analytics system is put in place to provide for early detection of fire outbreaks.
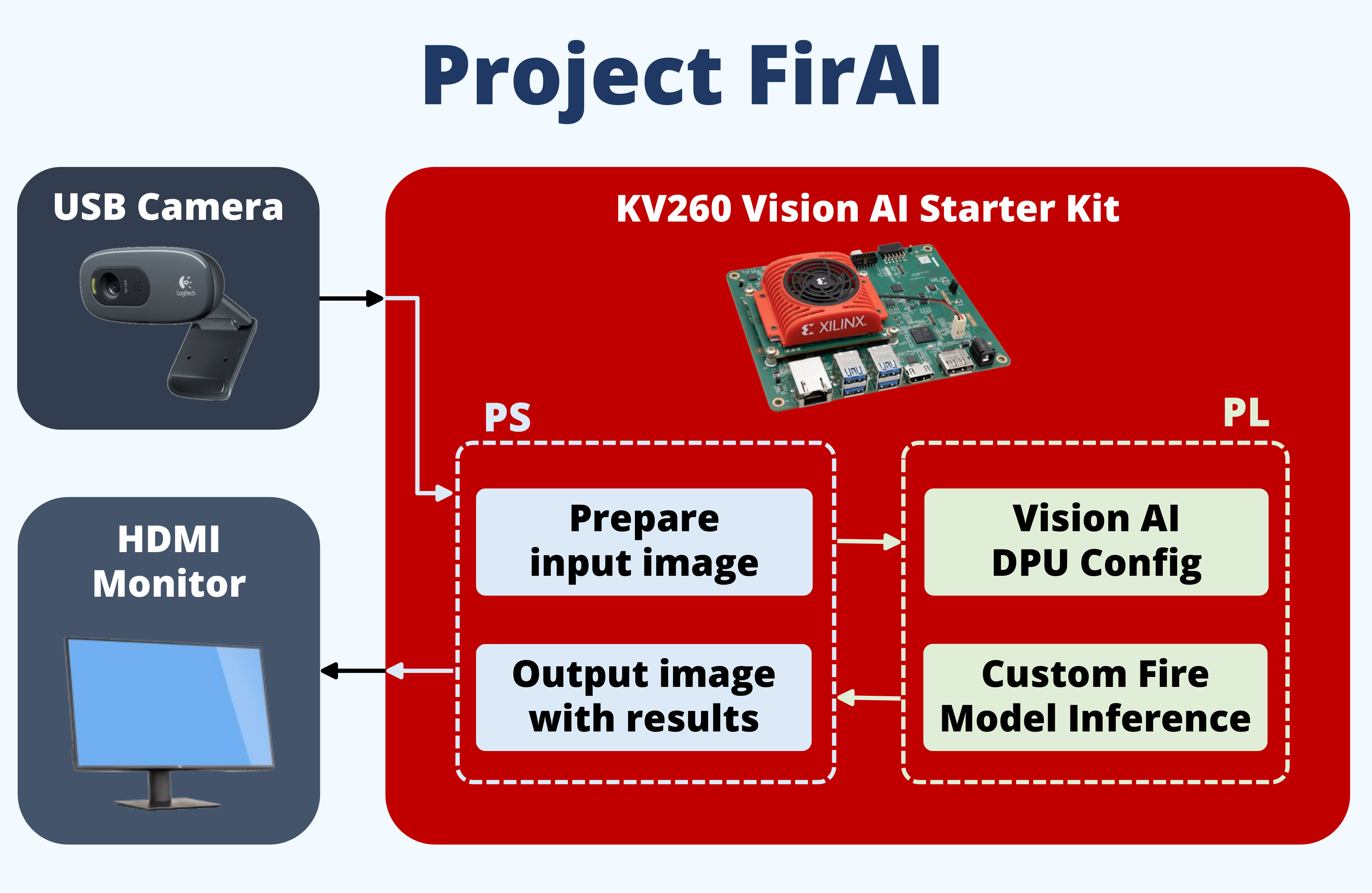
Goal: My solution consists of setting up a distributed computer vision system to provide early detection of fires from buildings. The distributed and modular nature of the system allows for easy deployment without needing to setting up more infrastructure. It is useful to enhance the firefighting power of the crew without the need to increase the manpower size. This is made possible using the Xilinx Kria KV260 for edge AI accelerated image processing capabilities. When deploying, the state council authorities can tap on existing surveillance cameras in neighborhoods for the video feed. This modular approach is the key technique to provide for quick deployment as the cameras are already put in place.
The hardware used is the Xilinx Kria KV260, the camera kit for accelerated computer vision processing, and Ethernet connectivity. The embedded software shall use Vitis AI. On my PC, a custom Yolo-V4 model will be trained with an existing dataset for fire detection. After which, the Xilinx YoloV4 flow is used to quantize, prune and compile the model for the DPU instance. Finally, it is deployed on the Kria KV260.
First we need to prepare the SD card for the Kria KV260 Vision AI Starter Kit.
In the box, a 16GB SD card is provided, but I recommend using at least 32GB instead, since the setup may exceed 16GB of space.
We will download using Ubuntu 20.04.3 LTS. Download the image from the website and save it on your computer.
On your PC, download the Balena Etcher to write it to your SD card.
Alternatively, you can use the command line (warning: ensure you write to the correct drive, /dev/sdb must be your SD card)
xzcat ~/Downloads/iot-kria-classic-desktop-2004-x03-20211110-98.img.xz | sudo dd of=/dev/sdb bs=32M
Once done, your SD card is ready and you can insert it into your Kria.
Kria: Setup Xilinx UbuntuConnect a USB Keyboard, USB Mouse, USB Camera, HDMI/DisplayPort and Ethernet to the Kria.
Connect the power supply to turn on the Kria and you will see the Ubuntu login screen.
The default login credentials are:username: ubuntupassword: ubuntu
Upon booting, the interface can be very slow, so I ran these commands to disable animations tweaks to speed things up.
gsettings set org.gnome.desktop.interface enable-animations false
gsettings set org.gnome.shell.extensions.dash-to-dock animate-show-apps falseNext, update the system to the latest by doing system updates and calling this command
sudo apt upgradeNote that it is necessary to update because earlier versions of Vitis-AI do not have Python support, as mentioned in this forum thread.
Install the xlnx-config snap for system management and configure it(More information on the Xilinx wiki):
sudo snap install xlnx-config --classic
xlnx-config.sysinitNow check that the device configuration is working fine.
sudo xlnx-config --xmutil boardid -b somInstall the Smart Vision app and Vitis AI library with examples. (The smart vision app contains the bitstream for the DPU which we will be reusing, and the library samples will be used to test our trained models later on too)
sudo xlnx-config --snap --install xlnx-nlp-smartvision
sudo snap install xlnx-vai-lib-samplesCheck the samples and apps that have been installed
xlnx-vai-lib-samples.info
sudo xlnx-config --xmutil listappsAfter running the above command, you will also notice the DPU fingerprint required the Model Zoo samples.
Let's run one of the samples. Before we do so, connect your USB camera and ensure the video device is detected. I am using the Logitech C170 and it is detected on /dev/video1
v4l2-ctl --list-devicesLoad the smart vision app and launch it. You can play around and see the capabilities of the Kria.
sudo xlnx-config --xmutil loadapp nlp-smartvision
xlnx-nlp-smartvision.nlp-smartvision -uBefore running any accelerator apps, we always need to load the DPU from the bitstream. Next time, we can simply call the smartvision app which will load the bitstream for us. Alternatively, you can create your own packaged app.
Note: Accelerator bitstream is located at /lib/firmware/xilinx/nlp-smartvision/.Since my plan is to use the YOLOv4 framework, let's test an example from the model zoo. There is the "yolov4_leaky_spp_m" pre-trained model.
sudo xlnx-config --xmutil loadapp nlp-smartvision
# the number 1 is because my webcam is on video1
xlnx-vai-lib-samples.test-video yolov4 yolov4_leaky_spp_m 1The above commands will download models the first time you run it. The models are installed into ~/snap/xlnx-vai-lib-samples/current/models directory
With this, the Kria is working fine and let's train our own model
PC: Run YOLOv4 Model trainingTo train the model, follow the 07-yolov4-tutorial documentations provided by Xilinx. It was written for Vitis v1.3, but the steps are exactly the same for currently Vitis v2.0 as well.
The application is to detect fire incidents, hence download the fire image open-source dataset here:
fire-smoke (2059's images, include labels)-GoogleDrive
https://drive.google.com/file/d/1ydVpGphAJzVPCkUTcJxJhsnp_baGrZa7/view?usp=sharing
For training, take reference for the fire dataset .cfg file here.
And we will have to modify this .cfg configuration file to be compatible with Xilinx Zynq Ultrascale+ DPU:
[#1] Xilinx recommends the file input size to be 512x512 (or 416x416 for faster inference)
[#2] The DPU does not support MISH activation layers, hence replace all of them with Leaky activation layers
[#3] The DPU only supports a maximum SPP maxpool kernel size of 8. By default it is set to 5, 9, 13. But I decided to change it to 5, 6, 8.
I trained it on Google Colab. I followed the standard training process for YOLOv4 without much modifications.
Find my Jupyter notebook with step-by-step instructions in my github page.
This is the plot of the progression for the losses. I ran it for about 1000 iterations because I did not have much bandwidth resources to continue. I felt that the accuracy was good enough for this prototype but I would recommend training until a few more thousand iterations if you can.
Download the best weights file (yolov4-fire-xilinx_1000.weights). I ran the yolov4 inference locally on my CPU and it took about 20 seconds for 1 image! We shall see later that it can be accelerated to near real-time speeds using the FPGA.
./darknet detector test ../cfg/fire.data ../yolov4-fire.cfg ../yolov4-fire_1000.weights image.jpg -thresh 0.1We now have the trained model and ready to convert it to deploy on the Kria.
PC: Convert TF modelThe next step is to convert the darknet model to a frozen tensorflow graph. The keras-YOLOv3-model-set repository provides some helpful scripts for this. We will run some scripts in the Vitis AI repository.
First install docker, use this command:
sudo apt install docker.io
sudo service docker start
sudo chmod 666 /var/run/docker.sock # Update your group membershipPull the docker image. This will download the latest Vitis AI Docker with the following command. Note that this container is the CPU version.(Ensure at least 100GB of disk space for the disk partition running Docker)
$ docker pull xilinx/vitis-ai-cpu:latestClone the Vitis-AI folder
git clone --recurse-submodules https://github.com/Xilinx/Vitis-AI
cd Vitis-AILaunch the Docker instance
bash -x ./docker_run.sh xilinx/vitis-ai-cpu:latestOnce inside the docker shell, clone the tutorial files. As of writing, the tutorial files have been removed for Vitis v1.4/v2.0, which I assume are in the process of upgrading. The tutorial works fine in newer versions anyway so revert back to the latest v1.3 commit.
> git clone https://github.com/Xilinx/Vitis-AI-Tutorials.git
> cd ./Vitis-AI-Tutorials/
> git reset --hard e53cd4e6565cb56fdce2f88ed38942a569849fbd # Tutorial v1.3Now we can access the YOLOv4 tutorial from these directories:
- From the host directory:
~/Documents/Vitis-AI/Vitis-AI-Tutorials/Design_Tutorials/07-yolov4-tutorial - From within the docker instance:
/workspace/Vitis-AI-Tutorials/07-yolov4-tutorial
Go into the tutorial folder, create a new folder called “my_models” and copy these files:
- The trained model weights: yolov4-fire-xilinx_last.weights
- The training config file: yolov4-fire-xilinx.cfg
Under the scripts folder, you will find convert_yolov4 script. Edit the file to point to our own model (the cfg and weights file):
../my_models/yolov4-fire-xilinx.cfg \../my_models/yolov4-fire-xilinx_last.weights \
Now go back to the Terminal and enter the docker instance. Activate the tensorflow environment. We will start the process to convert the yolo model
> conda activate vitis-ai-tensorflow
> cd /workspace/Vitis-AI-Tutorials/Design_Tutorials/07-yolov4-tutorial/scripts/
> bash convert_yolov4.shAfter conversion, you can now see the the Keras model (.h5) inside the “keras_model” folder.And the frozen model (.pb) under the “tf_model” folder.
We need to copy part of the training images to the folder "yolov4_images". These images will be used for calibration during quantization.
Create a folder called “my_calibration_images” and paste some random files of your training images there. Then we can list out the names of all the images into the txt file.
> ls ./my_calibration_images/ > tf_calib.txtThen edit yolov4_graph_input_keras_fn.py, to point to these file locations.
Run ./quantize_yolov4.sh. This will produce a quantized graph in the yolov4_quantized directory.
Now you will see the quantized frozen model inside the “yolov4_quantized” folder.
Create the arch.json which is used to compile the xmodel, and save it to the same “my_models” folder.
Take note to use the same DPU fingerprint we saw earlier on the Kria. In this case the following is for the Kria B3136 configuration (Vitis AI 1.3/1.4/2.0)
{
"fingerprint":"0x1000020F6014406"
}Modify compile_yolov4.sh to point the our own files
NET_NAME=dpu_yolov4
ARCH=/workspace/Vitis-AI-Tutorials/Design_Tutorials/07-yolov4-tutorial/my_models/arch.json
vai_c_tensorflow --frozen_pb ../yolov4_quantized/quantize_eval_model.pb \
--arch ${ARCH} \
--output_dir ../yolov4_compiled/ \
--net_name ${NET_NAME} \
--options "{'mode':'normal','save_kernel':'', 'input_shape':'1,512,512,3'}"Run the compilation
> bash -x compile_yolov4.shInside the “yolov4_compiled” folder, you will see meta.json and dpu_yolov4.xmodel. This constitutes the deployable model. You can copy these files to the Kria as we will be using it next.
Take note if you follow older guides, you may see *.elf files being used. This is replaced by the *.xmodel files
From Vitis-AI v1.3 the *.elf file is not generated anymore by the tool. Instead of that *.xmodel will be used even for deploying models on edge devices.
For some applications, a *.prototxt file is needed together with the *.xmodel file. To create the prototxt, first we can copy the example and modify.
Note the things to be followed according to your YOLO configuration:
- “biases”: must be the same as “anchors” in the yolo.cfg file
- “num_classes”: must be the same as “classes” in the yolo.cfg file
- “layer_name”: must be the same as the outputs in the xmodel file
For layer_name, you can go Netron (https://netron.app/) and open your.xmodel file. As YOLO models have 3 outputs, you will also see 3 ending nodes.
For each of these nodes (fix2float), you can find the number from the name.
If you may encounter a segmentation fault when running the model, it is most likely due to a misconfigured .prototxt file. If so, come back here and verify everything is correct.
Kria: Test deploy on Kria UbuntuThese are the necessary files which you should copy to the Kria.
Create a folder called “dpu_yolov4” and copy all the model files. I chose to create it in my Documents folder. The app requires these 3 files:
- meta.json
- dpu_yolov4.xmodel
- dpu_yolov4.prototxt
We can test the model by invoking the test_video_yolov4 executable directly from the snap bin folder.
> sudo xlnx-config --xmutil loadapp nlp-smartvision # Load the DPU bitstream
> cd ~/Documents/
> /snap/xlnx-vai-lib-samples/current/bin/test_video_yolov4 dpu_yolov4 0You will see it detect all fire. In this case there's multiple overlapping boxes. We will take this into account when we create the python app.
In my Github page you will find my full app implementation. It takes into account overlapping boxes and does an Non-maximum Suppression (NMS) bounding box algorithm. It also prints the confidence level of the bounding box. Additionally, the coordinates are recorded in the frame. In a real life system, these information will be sent to the transponder instead and alert the personnel in-charge.
Using Xilinx tools to accelerate, we can see how the inference improved from 1 frame in 20 seconds on my PC CPU to at least 5 frames per second on the Xilinx DPU accelerator. This amounts to 100 times improvement in speed of inference! As the Kria is also a small and lightweight device, it makes for high performance, easy deployment and a low power consumption.





{kind=link}
Comments
Please log in or sign up to comment.