
Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
The goal of this project is to run GPT-2 models for text generation on Raspberry Pi 4, with a nice GUI so text can easily be generated. As well as integration with other projects for enhancing a chatbot etc.
The project was started in May 2022, and I have been working on it since then. I am currently working with the Raspberry PI 4 Model B, but I will be working to get the Pi Zero 2 working as well. The project has been tested on Raspberry Pi OS Bullseye 64 bit.
The ModelsSo what is GPT-2?
It is an open source artificial intelligence made by OpenAi, it takes text inputs and transforms them to generate text outputs. It is the successor to GPT-1. You can find more information on GPT-1 here.
It comes in 4 main sizes that I know of; small, medium, large and extra-large - with 124M, 355M, 774M, and 1.5B parameters, respectively. There are also some more specifically trained ones, but I am not using them here.
I have allowed for a selection to be made within this program to choose which one to run and download. This is because they can consume quite a lot of RAM, so it is handy to be able to choose smaller models for smaller devices.
The other thing to consider is that the RAM is not always available. If you are using a device with a low-end processor, you may not be getting the best performance. So, it's a good idea to have a larger RAM size.
Of course the larger the model, the more outputs can be generated.
You can find out more at here and here.
Why not GPT-3?
GPT-3 is an even me advanced model with 175B parameters.
I believe GPT-3 is currently only available via API; I basically wanted something that would run locally, in future I may add an option to use GPT-3 if Text Machina is connected to the internet. Also I believe GPT-3, while now open to everyone; still requires some sign up to gain access to.
You can read more information here.
And more information on all the GPT models journey here.
So this is just a a nice little easy to setup and run text generator that could integrate into a robot or some other text-based software.
The CodeThe 3 main bits of code that do the work are:
download_model.pyThis is where the models and tokenizers are set and then saved to models/gpt folder.
run_text_generation.pyThe pipeline is setup here to load the model and run text generation from the input text provided to the function. This is mainly handled with code from huggingface libraries that abstracts out the downloading and running of the models, so instead of lots of code it's nice and tidy like so:
text_generation = pipeline(task="text-generation", model=f"{models_dir}/{gpt2_size.x}",
tokenizer=f"{models_dir}/{gpt2_size.x}")
generated_text = text_generation(prefix_text,
max_length=output_length.x,
do_sample=sampling_enable,
top_k=top_k_setting,
top_p=top_p_setting,
random_seed=random_seed_setting,
temperature=temperature_setting,
no_repeat_ngram_size=no_repeat_ngram_size_setting,
num_return_sequences=num_return_sequences_setting)[0]Then finally code for the GUI:
gui_runner.pyI am using tkinter to create a nice GUI for this, this is where all the code for that resides; it allows for downloading of the models, typing of input text and of course, the output text.
It should prevent any un-wanted clicks during processing by disabling the buttons/text inputs. If you find any bugs with this let me know.
There is also code under utils that can be used to get and set variables, this is used for setting the model version while the program is running.
Under utils there is also:
load_bar_non_iterable.pyand
print_colors.pyWhich are used to create nice loading bars when downloading/saving models, these are both borrowed from my latest Chatbot Project.
The UsageBefore using this please be aware of the biases and limitations of GPT-2, straight from the repos README.md:
Using GPT-2 to generate text may result in some offensive language or some strange things, so please be aware of that.
Go here to read more:
https://huggingface.co/gpt2#limitations-and-bias
So I can't be responsible for any strange things generated by these pre-trained models.
You should also not use this to do anything other than generate text for fun/robots, don't use it for serious things!GPT-2 Limitations and Bias. < Read this.
In terms of installation you should ensure you have either a decent modern Windows based machine 8gb+ RAM or a Raspberry Pi 4 64 bit OS 4gb RAM or above (I haven't tried on a Pi Zero 2 yet) and also ensure you have Python 3.9 installed. As well as having git and virtualenv installed.
You can see more details of general system requirements here.
It can also take up to a few minutes to process a sentence running even on medium GPT2 size on a Raspberry Pi. But on my Ryzen 5 laptop it is of course considerably faster.
For Raspberry Pi 4's with <8GB RAM you may want to increase swap, with the instructions here. Although the extra large model will most likely require swap on a Pi 4 8GB.
Then clone out the code:
git clone https://github.com/LordofBone/text-machina.gitSetup a virtual environment for python or just install the required libraries to the root python instance:
pip install -r requirements.txtThe GPT2 files are found in the models/gpt/ folder, once they have been downloaded.
Once the models have been downloaded it can be run with no internet connection - perfect for robots/applications that are on the edge.
You can run the GUI using:
python run_text_generator_gui.pyYou can also run the setup of models from a function to download the data from the server, so that I can use it in my GUI. It is also used when I want to change the name of a particular model, or to add a new model to the list. Here is what the function looks like:
def get_and_save_models():
"""
Downloads the GPT2 models if they don't already exist.
:return:
"""
tokenizer = GPT2Tokenizer.from_pretrained(gpt2_size.x)
model = GPT2Model.from_pretrained(gpt2_size.x)
model.save_pretrained(f'{models_dir}/{gpt2_size.x}')
tokenizer.save_pretrained(f'{models_dir}/{gpt2_size.x}')and that is within the file:
python setup_models.pyYou can also run the sentence generation for multiple sentences with:
python run_text_generator_from_file.pyThis loads up the file 'seed_sentences.txt' under data/seeds and goes through ever line in the file, then runs text generation on it; it then outputs the generated text.
This can be integrated into other things and use it to generate text, pull down the repo into the folder of the project you are working on, then append the system path of the text machina folder to the system path of the project.
`text_machina_dir = os.path.join( path_to_text_machina )`
`sys.path.append(text_machina_dir)`
You will also need to install everything in requirements.txt and/or add the requirements to your project's requirements.txt
Then just import everything in
from integrate_text_generation import *and call
use_text_generationwith a text input.Or call
use_text_generation_from_fileto load a text file from the 'data/seeds' directory and generate text from the sentences within the text files there.
There is also the change model function which can be called to use different models for text generation:
change_gpt2_model(model_name='gpt2-medium')The GPT2 model has a default configuration file, which is located in the config/gpt2_config.py file. The file is a text file with the following structure:
from pathlib import Path
from utils.get_and_set import Property
dataset_dir = Path(__file__).parent.parent / f"data/seeds/"
models_dir = Path(__file__).parent.parent / f"models/gpt/"
gpt2_models = ["gpt2", "gpt2-medium", "gpt2-large", "gpt2-xl"]
gpt2_size = Property()
sampling_enable = True
top_k_setting = 50
top_p_setting = 0.92
num_return_sequences_setting = 3
# not sure if this works within the text-generation pipeline but adding anyway, '0' should mean no seed set
random_seed_setting = 0
temperature_setting = 0.7
output_length = Property()
default_gpt2_size = gpt2_models[0]
gpt2_size.x = default_gpt2_size
output_length.x = 200This allows for nice tweaking of the text generation; you can find out more about these settings here.
The gpt2_size variable is a getter/setter that is used to change and reference the model size within the GUI without having to restart the application.
Also extra model names can be added into the gpt2_models list and they will appear under the download/usage options.
The OutputThe text generation by the gpt2 models is quite impressive, although sometimes it does create non-sensical outputs that are hard to parse and sometimes it didn't make sense - the gpt2-large model especially produces good results, but the gpt2 (small) and gpt2-medium models were also passable and ran a lot faster.
So here are some fun examples I've made using the extra large model:
Input text:
it was a fun time at the fair. but it did start raining half way through so we had to leave.
Output:
I was so excited to see the new exhibit at this year's fair, the "Fairy Tale Land of the Future". I was really excited about it. I had never seen anything like it before. It was amazing. The exhibit was all about the future. They had a giant robot that was going to be the first of its kind. There were all kinds of things that were going on in the world. And it was just so cool. But it started raining and we couldn't go inside. So we just had the best time in our little tent. We had some of our favorite things from the exhibit. Like the giant robots. That was the coolest thing.
Input text:
I went to see the newest marvel movie and it was pretty good, not the best but good.
Output:
I was a little disappointed that the movie was not as good as the first one. The new one was better.
I was also disappointed with the new movie. It was just a lot of the same stuff. Same characters, same plot, and same characters. There was nothing new. Nothing new at all. And I don't know why. Maybe it's because I'm a big fan of Marvel movies.
Input text:
I quite like the starbucks festive edition drinks.
Output:
I'm not sure if it's the fact that it is a holiday drink or the festive theme, but I really like this drink. It's a nice mix of sweet and sour, and the coconut milk is really nice. I'm a big fan of coconut, so I was really happy to see it in this. The coconut is not too sweet, which is nice, as it makes it a little more refreshing. This is also a good drink to have on a hot day, because it has a lot of sweetness. If you're looking for a drink that is sweet without being too much, this is the drink for you.
Input text:
we went into the chip shop and got some cheesy chips. they were really nice and the weather outside was cooling down
Output:
I've been here a few times and it's always a good time. The food is always good and they have a great selection of beer. I've never had the food here that I didn't like. They have some good burgers and wings. My favorite is the buffalo chicken wings, they are so good. It's a small place but it gets packed. If you're looking for a place to grab a bite to eat, this is a solid place.
Input:
I watched a lot of tv over the weekend
Output:
and I was watching the new season of the show "The Walking Dead" and it was really good. I really liked the character of Rick Grimes and the way he was portrayed. He was a good guy and he had a great story.
I was also watching a movie called "Dawn of The Dead". I think it's a really great movie. It's about a zombie apocalypse and a group of people who are trying to survive. They are all trying their best to stay alive. The movie was very good and very scary. And I thought it would be a cool idea to make a shirt that says "I'm a Zombie" on it. So I did.
So it can generate some generally good and nearly passably real outputs - especially when it takes multiple elements of the input text and has it in the output text, like the fair example and the fact it mentions the fair and the weather from the input sentence.
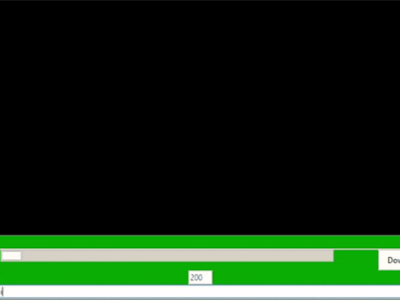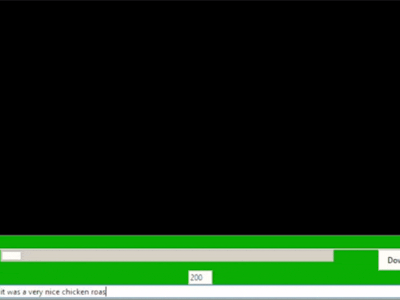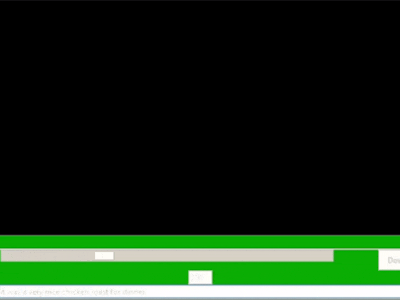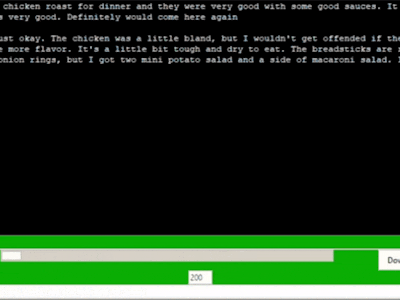
Or indeed from the gif that is the thumbnail for the project:
As you may have noticed sometimes it can really seem obvious it has been generated:
I was a little disappointed that the movie was not as good as the first one. The new one was better.
Which seems to contradict itself and seems stilted. Also the roast chicken example from the gif above contradicts itself a bit by saying the food was good, but then just ok... but then back to good again by the end. I've laughed a few times when I've seen text generation that seems to resemble someone really indecisive.
I have even noticed this generating text that contains code - which is really interesting. If you put in something like "creating s3 buckets with terraform", it will sometimes generate text containing terraform that relates. Interesting, but also; a bit worrying, if it is code that was accidently set to public at the time the model was trained.
The EndI do want to integrate this into future projects at some point, however; the RAM and processing requirements make it quite difficult to work alongside other code, so I may have to wait until the RPi 5 or use a Pi alternative that has more horse power/memory.
I hope you all enjoyed this latest raspberry pi project. I hope this project can inspire you and give you some ideas for what to do with your Raspberry Pi. If you enjoyed the article and would like to be notified when I post new projects then please subscribe to my blog.
Do you think I typed that last paragraph?
I also have a new Terminator head project on the way - and this would be a great example of where integrating something like this into the chatbot side of it would be awesome for expanding out responses; however as mentioned I think at the moment the CPU/RAM requirements of running everything else as well as this would be too much on a Pi4.
But do keep an eye out for the aforementioned project and see you next time.




Comments