



Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
 |
| |||||
Hand tools and fabrication machines | ||||||
 |
| |||||
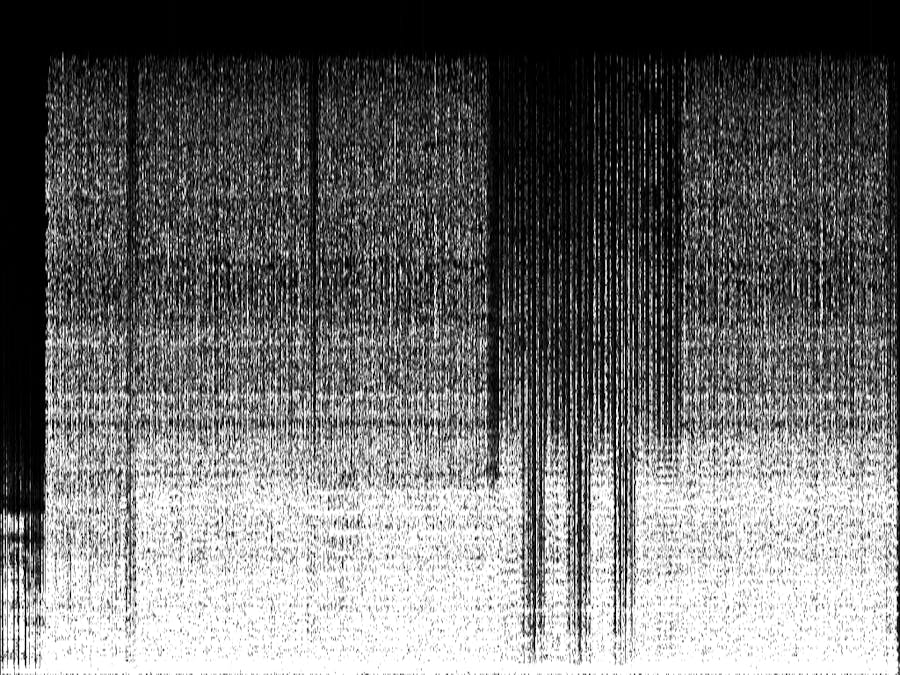
A spectrogram is a visual representation of the spectrum of frequencies for signals over time. It is often used a lot in music, speech processing, sonar, radar, and others. You can use spectrogram for audio analytics, speech recognition and many others.
PreparationWe first need to install Ubuntu and Jackpack onto our Jetson Nano, installation of OS Image and Jetpack can be downloaded at
https://developer.nvidia.com/embedded/jetpack
NVIDIA has already wrote down a pretty detailed guide on Jetson NANO setup, the guide can be seen at
https://courses.nvidia.com/courses/course-v1%3ADLI%2BC-RX-02%2BV1/course/
Tensorflow is needed to generate spectrogram, after Jetpack being installed we can follow instructions via https://docs.nvidia.com/deeplearning/frameworks/install-tf-jetson-platform/index.html
Install system packages required by TensorFlow:
$ sudo apt-get update
$ sudo apt-get install libhdf5-serial-dev hdf5-tools libhdf5-dev zlib1g-dev zip libjpeg8-dev
Install system packages required by TensorFlow:
$ sudo apt-get update
$ sudo apt-get install libhdf5-serial-dev hdf5-tools libhdf5-dev zlib1g-dev zip libjpeg8-devInstall and upgrade pip3.
$ sudo apt-get install python3-pip
$ sudo pip3 install -U pip testresources setuptoolsInstall the Python package dependencies.
$ sudo pip3 install -U numpy==1.16.1 future==0.17.1 mock==3.0.5 h5py==2.9.0 keras_preprocessing==1.0.5 keras_applications==1.0.8 gast==0.2.2 enum34 futures protobufAfter that you can install tensorflow via
$ sudo pip3 install --pre --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v43 'tensorflow==1.15.0'After that you can test the tensorflow installed successfully via
$ python3
>>> import tensorflow as tf
>>> hello = tf.constant('Hello, Tensorflow!')
>>> sess = tf.Session()
>>> print(sess.run(hello))We can select songs from Bensound, change mp3 to wav file, but any mp3 would work
Since tensorflow right now can only do wav file, we can use following code to change it into wave file
from os import path
from pydub import AudioSegment
# files
src = "src.mp3"
dst = "dest.wav"
# convert wav to mp3
sound = AudioSegment.from_mp3(src)
sound.export(dst, format="wav")Next, we can turn our wave file into a spectrogram image file through tensorflow network, this serves as a foundation of image classification and image comparison.
import tensorflow as tf
# FIXME: audio_ops.decode_wav is deprecated, use tensorflow_io.IOTensor.from_audio
from tensorflow.contrib.framework.python.ops import audio_ops
# Enable eager execution for a more interactive frontend.
# If using the default graph mode, you'll probably need to run in a session.
tf.enable_eager_execution()
@tf.function
def audio_to_spectrogram(
audio_contents,
width,
height,
channels=1,
window_size=1024,
stride=64,
brightness=100.):
"""Decode and build a spectrogram using a wav string tensor.
Args:
audio_contents: String tensor of the wav audio contents.
width: Spectrogram width.
height: Spectrogram height.
channels: Audio channel count.
window_size: Size of the spectrogram window.
stride: Size of the spectrogram stride.
brightness: Brightness of the spectrogram.
Returns:
0-D string Tensor with the image contents.
"""
# Decode the wav mono into a 2D tensor with time in dimension 0
# and channel along dimension 1
waveform = audio_ops.decode_wav(audio_contents, desired_channels=channels)
# Compute the spectrogram
# FIXME: Seems like this is deprecated in tensorflow 2.0 and
# the operation only works on CPU. Change this to tf.signal.stft
# and friends to take advantage of GPU kernels.
spectrogram = audio_ops.audio_spectrogram(
waveform.audio,
window_size=window_size,
stride=stride)
# Adjust brightness
brightness = tf.constant(brightness)
# Normalize pixels
mul = tf.multiply(spectrogram, brightness)
min_const = tf.constant(255.)
minimum = tf.minimum(mul, min_const)
# Expand dims so we get the proper shape
expand_dims = tf.expand_dims(minimum, -1)
# Resize the spectrogram to input size of the model
resize = tf.image.resize(expand_dims, [width, height])
# Remove the trailing dimension
squeeze = tf.squeeze(resize, 0)
# Tensorflow spectrogram has time along y axis and frequencies along x axis
# so we fix that
flip_left_right = tf.image.flip_left_right(squeeze)
transposed = tf.image.transpose(flip_left_right)
# Cast to uint8 and encode as png
cast = tf.cast(transposed, tf.uint8)
# Encode tensor as a png image
return tf.image.encode_png(cast)
if __name__ == '__main__':
input_file = tf.constant('record.wav')
output_file = tf.constant('spectrogram.png')
# Generage the spectrogram
audio = tf.io.read_file(input_file)
image = audio_to_spectrogram(audio, 1024, 1024)
# Write the png encoded image to a file
tf.io.write_file(output_file, image)The spectrogram can then be used for image classifications on songs, or audio comparison for similarities.


Comments
Please log in or sign up to comment.