In this project, we mainly use VCK5000 to perform AI accelerated inference on the YOLOX model. At the same time, the quantized xmodel model can quickly and effectively recognize fuzzy objects in real time.
- In the field of autonomous driving and pattern recognition, the processing and extraction of effective image information is an extremely important step. However, in real life, images are often affected by hardware performance or external disturbances, resulting in image blur and noise enhancement, making it extremely difficult to extract the information we want. In addition, when effective information can be extracted, we sometimes need to identify multiple objects and track the positions of multiple objects to further obtain more effective information (such as semantic segmentation, image segmentation, etc.), which will greatly increase the hardware. Therefore, the program cannot perform object recognition and tracking in real time. Therefore, in our project, we will optimize the performance of these two types of problems, and the steps are as follows.
Step 1:
- 80 recognition object classes are set, and the neural framework written by YOLOX-Pytorch is used to train the COCO dataset, and the ideal training model file is obtained. In the training process, we use NIVDIA-RTX2060-GPU and Intel i5 10th-generation-CPU to load and process the dataset, and accelerate the training of the written train.py file and network-Pytorch' framework.py file to get effective training. Model file - yolox.pth, which optimizes the performance of distant blurred image recognition.
Step 2:
- Based on the vitis-ai-cpu: 1.4.1.978 version in the docker environment, the deployed VCK5000 board is quantified and compiled to obtain the YOLOX.xmodel file. In this process, we put the trained model files, COCO dataset files and related verification codes in the YOLOX folder (note: the data files on the GitHub website are subdirectories under the project YOLOX folder), Then run the quantization-related code under the Ubuntu Linux system to get YOLOX.xmodel and the YOLOX.xmodel obtained by compiling and quantizing to get the result.json file, and the data is saved on the Github URL I provided.
Step 3:
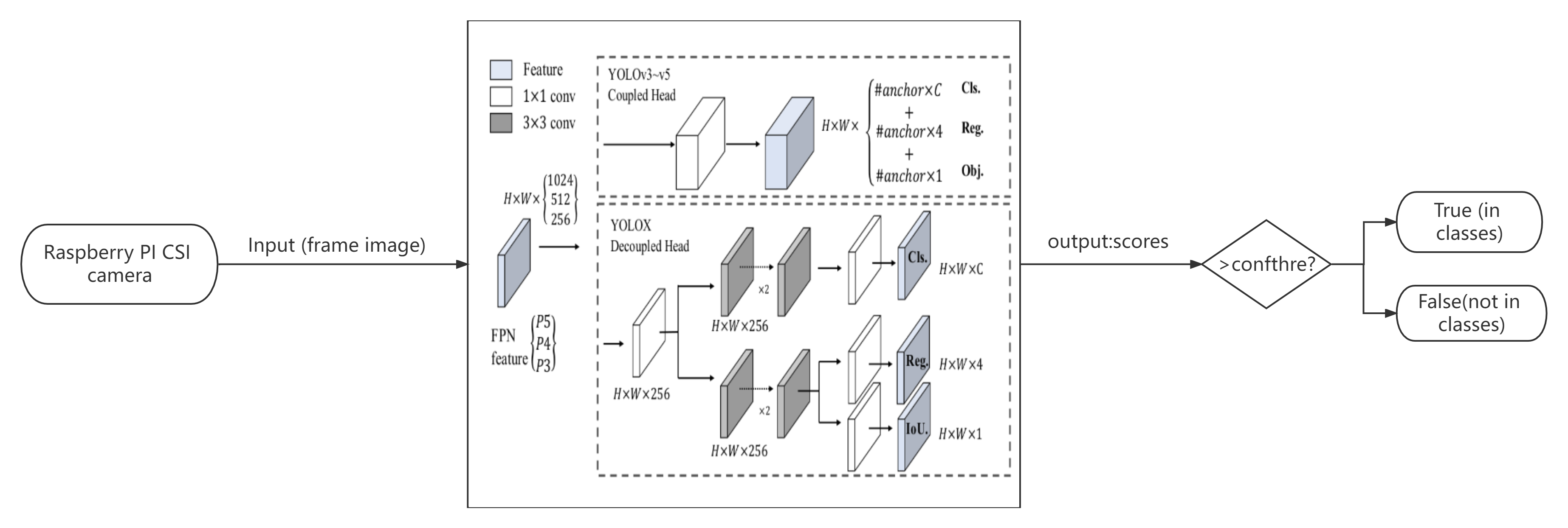
- By establishing xir::runner, run each subgraph of xir::graph in YOLOX.xmodel, and perform real-time identification and detection on the captured video. In the identification process, we use the Intel i7 11th generation-CPU and VCK5000AI reasoning board to detect each frame of the video obtained in real time. The identification result is still the same as the effect of verifying the yolox.pth model. 80 object classes. In addition, when each image runs end-to-end in the network, the duration of this process is calculated and recorded in a list.
Step 4:
- Finally, compare the duration of running the yolox.pth model on NIVDIA-RTX2060-GPU versus running the YOLOX.xmodel model on VCK5000. We calculated that on the VCK5000, the calculation time of each frame of the video in the video is only about 1.54s, but on the NIVDI-RTX2060-GPU, it takes about 2.13s. The calculation shows that the VCK5000 improves the recognition of the YOLOX model by nearly 100%. The performance of 27.8, so that it can more efficiently and quickly identify distant blurred objects in the video. Therefore, by using VCK5000, in the field of automatic driving and pattern recognition, this project has improved the performance of recognition and detection of distant blurred moving objects in video and fast recognition and detection of multi-moving objects.
You can watch a video of the effect of identifying blurred objects by following the website link below. (Just to clarify: we are looking for a video clip online as input data.)
https://567256.ma3you.cn/articles/ABpGK8O/







.png?auto=compress%2Cformat&w=48&h=48&fit=fill&bg=ffffff)

{kind=link}


Comments