





Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
 |
| |||||
| ||||||
| ||||||
| ||||||
| ||||||
| ||||||
| ||||||
 |
| |||||
| ||||||
| ||||||
Hand tools and fabrication machines | ||||||
 |
| |||||
 |
| |||||
 |
| |||||
Bring Computer Vision and elaborate AI models into the common automobile, where the price range does not include these technologies, at an affordable price. Also innovate on how to deliver important surrounding information to the driver.
Fast Links:Video Demo:Test Notebooks:- Emotions: CLICK HERE
- Drowsiness: CLICK HERE
- YoloV3: CLICK HERE
- Open Driving Navigator: CLICK HERE
- Open Driving Emulator: CLICK HERE
Driving has evolved into a daily routine for humans, comparable to eating, brushing our teeth, or sleeping. However, it has transformed into a time-consuming activity that occupies a significant portion of our daily lives. Moreover, if specific safety protocols are neglected, driving can pose potential risks.
As a driver, it’s quite important for you to know where the blind spots are on your own vehicle as well as other drivers' vehicles. Knowing this will help protect you and those around you from an easily-avoidable accident (no one wants to get sideswiped, really).
Blind spots are the areas to the sides of your car that can’t be seen in your rear mirror or side mirrors.
Despite being very noticeable in trucks (1), cars also have this type of blind spots, which can generate up to 800, 000 accidents per year (2).
- https://www.fmcsa.dot.gov/ourroads/large-blind-spots
- https://www.natlawreview.com/article/what-if-my-car-accident-was-caused-blind-spot
The Center for Disease Control and Prevention (CDC) says that 35% of American drivers sleep less than the recommended minimum of seven hours a day. It mainly affects attention when performing any task and in the long term, it can affect health permanently.
According to a report by the WHO (World Health Organization) falling asleep while driving is one of the leading causes of traffic accidents. Up to 24% of accidents are caused by falling asleep, and according to the DMV USA (Department of Motor Vehicles) and NHTSA (National Highway traffic safety administration) 20% of accidents are related to drowsiness, being at the same level as accidents due to alcohol consumption with sometimes even worse consequences than those.
Also, the NHTSA mentions that being angry or in an altered state of mind can lead to more dangerous and aggressive driving, endangering the life of the driver due to these psychological disorders.
Solution:We have previously developed this idea with a couple of iterations one of them was a small project that ran on Edge impulse, called Edge driving Monitor:
https://www.hackster.io/422087/edge-driving-monitor-c504a8
Regretfully, as you can see, we had quite a lot of limitations in this project. The CV models used were very limited because we were just using an ESP32 to run them on site so the information provided had a great deal of error. In addition to that it was slow and the visual stimulus was very limited, at least if you were diving.
At at the time the limitations of entry level hardware and the training models we had at hand were several, the project is almost 3 years old by now.
We also did a second try with a Jetson Nano:
https://devpost.com/software/torch-drowsiness-monitor
We still had a miriad of problems.
At first we wanted to run Pytorch and do the whole CV application on a Raspberry Pi 3, which is much more available and an easier platform to use. It probably was too much processing for the Raspi3 as it wasn't able to run everything we demanded so we upgraded to a Jetson Nano, we found several problems with the thermals at that point.
Later we had a little problem of focus with certain cameras so we had to experiment with several webcams that we had available to find one that didn't require to focus.
What we needed was:
- A better platform to run the CV models
- Better Models (it was 3 years ago :( )
- A better User interface
We built a prototype which is capable of performing these 3 monitoring reliably and in addition to being easy to install in any vehicle.
This PoC uses a Raspberry Pi 4 as the main computer to maintain low consumption for continuous use in a vehicle.
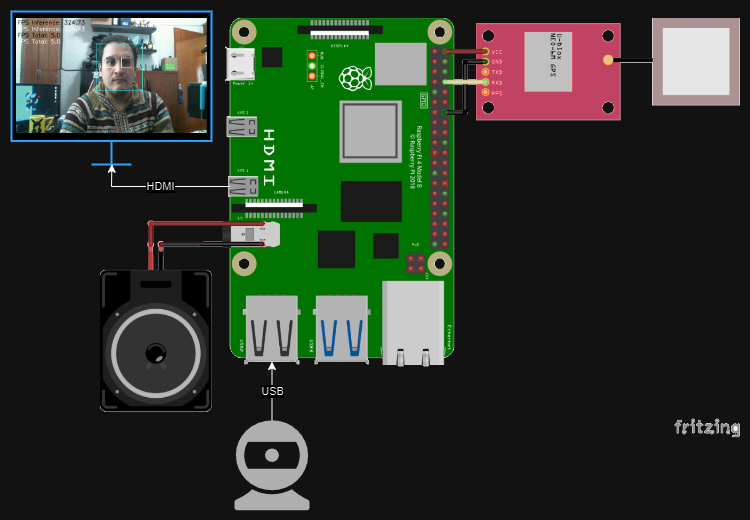
Connection Diagram:This general connection diagram shows how through a camera we can obtain images of the driver or those of the streets to later obtain relevant data on the driver's alertness, his state of mind and the objects around the car. All fed back by our internal screen and our online web map.
- Eye State Detection: Through preprocessing in OpenCV haarcascades, OpenCV DNN and a frozen graph inference model (Tensor Flow), we obtain the driver's state of attention and drowsiness. Details
- Emotions Identification: Through preprocessing in OpenCV haarcascades, OpenCV DNN and a frozen graph inference model (Tensor Flow), we obtain the driver's mood. Details
- YoloV3: Using OpenCV DNN and the famous network YoloV3 from Darknet We carry out the identification of vehicles and pedestrians in the blind spot of the car. Details
- Open Driving Monitor: Using a board enabled with OpenCV DNN, we created a system that can run the 3 AI models and also provide vehicle GPS information at all times. The selected board will be shown later. Details
- Open Driving Navigator: Using the NextJS, Open Layers and Vercel framework, we create a map that allows us to display the cars that are on our platform in real time and their states. Details
- Open Driving Emulator: Using the React Native and AWS IoT framework, we created a car emulator so you can confirm that the data correctly reaches our online map. Details
Our hardware system shows the correct connection of the hardware used, the selection of a raspberry pi as our final hardware was made by doing benchmarks with other boards specialized in AI.
- Raspberry Pi 4 (4Gb): This board allows the neural networks corresponding to each module to be run using the OpenCV DNN module with an ideal efficiency for the POC.
- USB Cam: This camera allows the input of images to the neural networks, it can be replaced by a native Raspberry camera or a wireless camera.
- GY-GPS6MV2: This module allows you to obtain the geolocation data of the device since the Raspberry Pi, despite being a computer, does not contain native GPS. This sensor provides data to the raspberry via serial.
- Speaker: This speaker allows us to obtain an auditory alarm signal for the correct function of the drowsiness detector, in the same way you can choose to connect it directly to the car speakers.
- LCD Screen: Allows the visualization of the navigation system in our Open Driving Navigator, in addition to providing Blind point information on the side of the car.
The correct training and testing of neural networks is essential to enhance the efficiency of driver assistance systems, as proposed in this project. However, carrying out these processes effectively requires appropriate datasets and frameworks. In this section, we will provide all the necessary resources so that you can reproduce the neural networks presented in this project as well as test their efficiency.
NOTE: The only neural network that was not trained was the Darknet YoloV3 network because it is a network already trained and ready to use, so we will only show its implementation with OpenCV DNN.
Online Training:For the efficient training of this type of neural networks, the use of GPUs is usually required due to their exceptional efficiency compared to CPUs. However, this type of infrastructure can be somewhat expensive and difficult to maintain. However, thanks to Google and TensorFlow, it is possible to do this training for free thanks to Google Colab.
By having a Google account, it will give us free access to Jupyter Notebooks Online with GPU or TPU (with certain limitations). Which are enough for us to train, deploy the neural networks and share the notebooks that we will show below.
NOTE: Please note the layers supported by the OpenCV DNN module, some models with complex or very modern layers may not be supported yet.
https://docs.opencv.org/4.8.0/d6/d87/group__dnnLayerList.html
Emotions Model Training:Here is the link for the training notebook: CLICK HERE
The neural network to detect emotions is a convolutional neural network designed specifically to recognize and classify emotions through images. To perform this task correctly we design the following neural network in tensorflow.
- Conv2d: This layer applies kernels to the image and obtains its main characteristics.
- Activation: This layer always comes after a convolutional layer to detect activations after the kernel.
- BatchNormalization: This layer normalizes the activations of a previous layer and accelerates the training of the neural network.
- MaxPooling2D: this layer reduces the number of parameters in the network and is added in order to prevent overfitting in training.
- Dropout: Randomly turns off a percentage of neurons during each training step, which improves model generalization.
- Flatten: this layer converts the output of the 3D layers into a one-dimensional vector that is finally passed to layers of fully connected neural networks, that is, it converts it into a format that this layer understands and can classify.
- Dense: in this layer each neuron is connected to all the neurons in the previous layer and has the purpose of performing the final classification.
The dataset we used in this training was FER-2013 which is a dataset with more than 28k images of emotions already classified.
Already in the notebook we have detailed the entire process of importing the dataset, separating it into Test, Train and Validation subsets, you only have to open the notebook in colab and hit run there to create the model yourself.
The notebook for this neural network is: CLICK HERE
NOTE: Also in the sale file folder Train We added the requirements.txt file so you know exactly in which ENV and version of all the python modules the training was carried out.
Finally, after training we will be able to obtain a Frozen Graph which is an inference model that is already optimized for production, this will be the file that we will provide to the OpenCV DNN module.
To directly download the Frozen Graph: CLICK HERE
Drowsiness Model Training:Link to the training notebook: CLICK HERE
The neural network for detecting eye state is a convolutional neural network specifically designed to recognize a closed eye from an open eye. To perform this task correctly we design the following neural network in tensorflow.
- Conv2d: This layer applies kernels to the image and obtains its main characteristics.
- Activation: This layer always comes after a convolutional layer to detect activations after the kernel.
- BatchNormalization: This layer normalizes the activations of a previous layer and accelerates the training of the neural network.
- MaxPooling2D: this layer reduces the number of parameters in the network and is added in order to prevent overfitting in training.
- Dropout: Randomly turns off a percentage of neurons during each training step, which improves model generalization.
- Flatten: this layer converts the output of the 3D layers into a one-dimensional vector that is finally passed to layers of fully connected neural networks, that is, it converts it into a format that this layer understands and can classify.
- Dense: in this layer each neuron is connected to all the neurons in the previous layer and has the purpose of performing the final classification.
The dataset we used in this training was B-eye which is a dataset with more than 4,800 images of open and closed eyes already classified.
Already in the notebook we have detailed the entire process of importing the dataset, separating it into Test, Train and Validation subsets, you only have to open the notebook in colab and hit run there to create the model yourself.
The neural network notebook is: CLICK HERE
NOTE: Also in the same file folder Train we added the requirements.txt file so you know exactly in which ENV and version of all the python modules the training was carried out.
Finally, after training we will be able to obtain a Frozen Graph which is an inference model that is already optimized for production, this will be the file that we will provide to the OpenCV DNN module.
To download directly the Frozen Graph: CLICK HERE
Online Models Testing:Once we have the models ready, it is necessary to move on to the Testing stage, which involves the exhaustive evaluation of the models with inputs completely outside the training dataset, the objective of this is to verify the accuracy and performance of the model.
Here is a link for the testing training notebook: CLICK HERE
We invite you to open the Notebook and perform the test yourself, the dataset we created was 28 images, 7 of each emotion, in order to verify the accuracy with this new data.
Finally, the model precision percentages show us the following.
We can notice that the emotion that has the most problems recognizing is disgust and fear. Which tells us that this model still has room for improvement.
Drowsiness Model Testing:Here is a link directly to the testing notebook: CLICK HERE
We invite you to open the Notebook and perform the test yourself, but when testing with a test dataset that we created, we reached the following results.
Finally, the model precision percentages show us the following.
We can see that the model is perfect, however we noticed during the in-field tests that when we closed our eyes a little or distracted them from the camera, the model resulted in closed eyes, which for practical purposes to detect drowsiness or distraction this is very useful to us. .
NOTE: in the demo video we demonstrate this function clearly, you can go watch it to see this project in operation!
YoloV3 Model Testing:Here is a link directly to the testing notebook: CLICK HERE
We invite you to open the Notebook and take the test yourself. Nevetheless here we share the test results with you.
The model used in the test is the Yolo-Tiny model, because it is the lightest that we can use in this project and its detections are not sufficient for the proper functioning of the project.
NOTE: In the next section you will see the comparison of the models in various HW, if you want to use the complete YoloV3 model we recommend using at least the Jetson Nano, since it does perform processing on GPU and allows a frame rate realistic to function.
Board Setup:The correct choice of hardware for these AI models is essential for correct operation, adjusting to the energy consumption of the vehicle and the budget to carry out this project in production.
In all boards the AWS IoT configuration is the same, since it is done through certificates in the following code section.
EndPoint = "XXXXXXXXXX-ats.iot.us-east-1.amazonaws.com"
caPath = "opencvDNN/certs/aws-iot-rootCA.crt"
certPath = "opencvDNN/certs/aws-iot-device.pem"
keyPath = "opencvDNN/certs/aws-iot-private.key"The data frame that must be sent to the platform so that data begins to appear is the following.
{
"coordinates": [
-99.4738495,
19.3749642
],
"color": "#808080",
"data": "Emotion: Neutral\nState: Awake",
"id": 98574584180
}And the GPS configuration also has no difference from one board to another since they all have the same 40-pin configuration.
The GPS module does not require any additional configuration, it is configured only when it is connected, when it is already working the LED on the board will flash every second.
The Raspberry Pi 4 (RPi4) is a board the size of a credit card that provides us with the minimum characteristics so that this project can be carried out.
- CPU: Broadcom BCM2711 Quad-core
- GPU: VideoCore VI graphics
- RAM: 4GB
- Storage: 32 GB (MicroSD)
- Audio: 3.5mm jack
- Screen Port: 2 × micro HDMI
- Network Interface: Wi-Fi 802.11b/g/n/ac
- Board Price: $55 - (11/28/2023, Seeedstudio)
In the case of the RPi4 we are fortunate that there are already compiled versions of OpenCV with the DNN module. The steps to carry out this installation are as follows:
Update apt repository.
sudo apt updateUpdate pip, setuptools and wheel.
pip install --upgrade pip setuptools wheelInstall OpenCV requirements
sudo apt-get install -y libhdf5-dev libhdf5-serial-dev python3-pyqt5 libatlas-base-dev libjasper-devSelect the correct version of OpenCV module and install it
- opencv-python: The main distribution of the OpenCV library for Python, providing computer vision functionality.
- opencv-python-headless: A lightweight version of the OpenCV library for Python without GUI dependencies, suitable for headless environments or server deployments.
- opencv-contrib-python: An extended distribution of OpenCV for Python, including additional modules and features beyond the core library. (USE THIS)
- opencv-contrib-python-headless: A headless version of the extended OpenCV library for Python, omitting GUI components, making it suitable for server environments or systems without graphical interfaces.
Install the latest version (v4.8.0 - 11/28/2023) of opencv-contrib-python.
pip install opencv-contrib-pythonOnce this is done you will be able to use all the OpenCV modules on the RPi4 including the OpenCV DNN.
Jetson Nano:The Jetson Nano is an AI development board created by NVIDIA. This board provides us with a good cost benefit to carry out this project, in addition to allowing image processing by GPU.
- CPU: Quad-core ARM Cortex-A57 MPCore
- GPU: 128-core Maxwell
- RAM: 4GB
- Storage: 32 GB (MicroSD)
- Audio: 3.5mm jack
- Screen Port: HDMI 2.0
- Network Interface: Gigabit Ethernet
- Board Price: $149 - (11/28/2023, Seeedstudio)
In the case of the Jetson Nano it already comes with a version of OpenCV, but it is not adapted to work with CUDA and cuDNN, which are the modules in the jetson that allow us to perform image processing on the GPU. During the setup process we will use a script already designed to automatically configure OpenCV on our board.
Configuration:
Update apt repository.
sudo apt updateDownload the installation script, feel free to open the script file and review it.
wget https://raw.githubusercontent.com/altaga/Open-Driving-Monitor/main/OpenCV%20Scripts/build_opencv_nano.shFor the script to be successful, check that the OpenCV build parameters have the versions corresponding to our version of jetpack.
- In the script file change the CUDA_ARCH_BIN and CUDNN_VERSION numbers if they do not match on your jetson. ... -D CUDA_ARCH_BIN=5.3 # Cuda Arch BIN -D CUDA_ARCH_PTX= -D CUDA_FAST_MATH=ON -D CUDNN_VERSION='8.2' # cuDNN ...
- In the Jetson Nano the build process can take 4 to 5 hours, we still recommend that it have a small fan that diffuses the heat generated by the board, otherwise you run the risk of the board turning off mid-process and having to do it from the beggining.
Once this is done you will be able to use all the OpenCV modules on the Jetson Nano including the OpenCV DNN and GPU processing.
Jetson AGX Xavier:The Jetson AGX Xavier (Jetson AGX) is an AI development board created by NVIDIA. This board provides us with the best performance in AI models due to advanced GPU processing, but with high cost hardware.
- CPU: 8-core ARMv8.2
- GPU: NVIDIA Volta architecture with 512
- RAM: 32 GB
- Audio: Integrated audio codec HDMI
- Screen Port: HDMI 2.0, eDP 1.4, DP 1.2
- Network Interface: Gigabit Ethernet
- Board Price: $699 - (11/28/2023, Seeedstudio)
In the case of the Jetson AGX, it already comes with a version of OpenCV, but it is not adapted to work with CUDA and cuDNN, which are the modules in the jetson that allow us to perform image processing on the GPU. During the setup process we will use a script already designed to automatically configure OpenCV on our board.
Configuration:
Update apt repository.
sudo apt updateDownload the installation script, feel free to open the script file and review it.
wget https://raw.githubusercontent.com/altaga/Open-Driving-Monitor/main/OpenCV%20Scripts/build_opencv_agx.shFor the script to be successful, check that the OpenCV build parameters have the versions corresponding to our version of jetpack.
- In the script file change the CUDA_ARCH_BIN and CUDNN_VERSION numbers if they do not match on your jetson.
...
-D CUDA_ARCH_BIN=7.2 # Cuda Arch BIN
-D CUDA_ARCH_PTX=
-D CUDA_FAST_MATH=ON
-D CUDNN_VERSION='8.6' # cuDNN
...- On the Jetson AGX the build process can take 1 to 2 hours, the board already has its own built-in fan, so you don't have to worry about the temperature at all.
Once this is done you will be able to use all the OpenCV modules on the Jetson AGX including the OpenCV DNN and GPU processing.
Comparison Benchmarks:We compare the performance of all the neural networks on each of the boards in order to obtain FPS data for each of the models.
RPi4:Drowsiness:
- Emotions:
- Yolo:
- Drowsiness:
- Emotions:
- Yolo:
- Drowsiness:
- Emotions:
- Yolo:
Once the tests are finished and taking the averages of the FPS of each test, we obtain the following results.
- The processing or inference time for each of the boards was as follows, this is just the time it takes for the image to go through the network and obtain a result.
- The real time it takes our program to carry out the pre-processing, inference and display of the image on each of the boards is.
Finally we decided to use the RPi4 as the final board because the FPS it provides us is not enough for this project, however you can use the board that you consider best.
Open Driving Navigator (WebPage):Already having the vehicle data, we create a web platform that allows us to monitor in real time the cars that are sending data to the system. This is in order to prevent accidents and provide more information to other vehicles.
URL: https://open-driving-navigator.vercel.app/
NOTE: the page requires location permissions so that when sending data to the platform we can see the cars appear in our location.
NextJS:For the web platform, the framework of NextJS was used in in its most recent version (11/28/2023) and the open source maps Open Layers.
All the code of the website is open source and is in the following link.
AWS IoT:Communication between the devices and the website is carried out through AWS IoT since it allows us to maintain a secure connection at all times and we use the MQTTS protocol.
Configuring AWS IoT on the web page is done in the following code section.
var awsConfiguration = {
poolId: "us-east-1:xxxxxxxxxxxxxxxxxxxxxxxxxxxxx", // 'YourCognitoIdentityPoolId'
host:"xxxxxxxxxxxxxxxxxxxxx.iot.us-east-1.amazonaws.com", // 'YourAwsIoTEndpoint', e.g. 'prefix.iot.us-east-1.amazonaws.com'
region: "us-east-1" // 'YourAwsRegion', e.g. 'us-east-1'
};
module.exports = awsConfiguration;The deployment of the website to the Internet can be done easily and for free thanks to the Vercel platform, Check Free Plan Limits
It is only necessary to connect the main repository of the website with Vercel and it will automatically perform the deployment.
URL: https://open-driving-navigator.vercel.app/
Open Driving Emulator (Android Native App):We can simulate a car by sending data from the simulator to the platform.
NOTE: the app requires location permissions so that when sending data to the platform we can see the simulated car appear in our location.
React Native Setup:To create the emulator, the framework of React Native in its most recent version (11/28/2023).
All the code of the app is open source and is in the following link.
AWS IoT:The communication between the app and the website is carried out through AWS IoT since it allows us to maintain a secure connection at all times and we use the MQTTS protocol.
The configuration of AWS IoT in the app is exactly the same as that of the website, since both work with javascript and this is done in the following section of code.
var awsConfiguration = {
poolId: "us-east-1:xxxxxxxxxxxxxxxxxxxxxxxxxxxxx", // 'YourCognitoIdentityPoolId'
host:"xxxxxxxxxxxxxxxxxxxxx.iot.us-east-1.amazonaws.com", // 'YourAwsIoTEndpoint', e.g. 'prefix.iot.us-east-1.amazonaws.com'
region: "us-east-1" // 'YourAwsRegion', e.g. 'us-east-1'
};
module.exports = awsConfiguration;To make it easier for them to test the web platform. This is the link to the beta of our application, with it you can send information to our online map and simulate our system without additional hardware. AI models can be tested from the application in future versions using OpenCV.JS
URL: https://play.google.com/store/apps/details?id=com.altaga.ODS
How use it:To use the app, you will only have to open the application, accept the location permissions and finally press "Start Emulation"
With this new hardware and the new models that we have in the year 2023 our vision for this project has finally been achieved. It now works without any delay and the models are instantaneous. Probably the next steps we will take for the project is just on the industrial side to try and make it a consumer product that can be in concept installed on every non-smart car. Thank you for reading and hopefully you like the project.
DEMO (again):References:
Links:
(1) https://medlineplus.gov/healthysleep.html
(2) http://www.euro.who.int/__data/assets/pdf_file/0008/114101/E84683.pdf
(3) https://dmv.ny.gov/press-release/press-release-03-09-2018
Connection Diagram


{kind=link}
{kind=link}


Comments
Please log in or sign up to comment.