




Hardware components | ||||||
| × | 1 | ||||
| × | 4 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
.png?auto=compress%2Cformat&w=48&h=48&fit=fill&bg=ffffff) |
| |||||
 |
| |||||
 |
| |||||
Hand tools and fabrication machines | ||||||
 |
| |||||
 |
| |||||
 |
| |||||
| ||||||
Strawberries are a very time sensitive crop and labor-intensive crop to pick. Unlike many other fruits, once the strawberries are picked, they stop ripening so they have to be picked at exactly the right time before they become over-ripe but only after they are ripe.
The labor-intensive nature of strawberry harvesting significantly impacts both costs and quality. The delicate berries must be hand-picked to avoid bruising and damage, necessitating a large workforce during the short harvesting period. In Florida, labor constitutes about 40% of the total production cost of strawberries, with temporary labor alone costing approximately $9, 793 per acre. This cost has increased by 32% over five years due to rising wages and labor shortage according to FE1041/FE1041: Labor Shortages in the Florida Strawberry Industry (ufl.edu)
Our team had previously worked on a project called Farmaid which detected diseases in plants and when AMD announced the Pervasive AI Contest, we wanted to take the project further with the Kria KR260. In fact, during our tests of Farmaid when we showed it to different greenhouses, this was one of their most common questions. The other was about how we could use a bot to help their chickens exercise.
The ApproachOur original idea was to use Kria KR260's GPIO or PMOD pins to control a robot arm and attach the equipment to our existing platform that is controlled by an Arduino MEGA and ROS. For the current platform, we used a Raspberry PI to issue commands to the MEGA which in turn controls the wheels.
Since the KR260 also supports ROS2, we wanted to port the controls over to it and have it control both the robot wheels and the arm.
For detecting and picking strawberries, we would use a combination of two cameras and lidars. An Intel RealSense D435i would find the strawberries from a distance using an object detection model running on the KR260. It would provide a bounding box and a distance to the actual plant. Then a second lighter camera mounted on top of the arm along with another distance sensor would help the arm close the gap and pick up an individual strawberry.
The driving would have two modes, one being autonomous and the other being manual. This would help navigate more tricky situations which autonomous driving is not ready for.
Our ProcessThe team had three members and divided the tasks. Alex Polonsky and Keith Aylwin worked on the bot side while I (Muhammad Sohaib Arif) worked mainly with the KR260. For the robotic arm, we used a LeARM Robotic arm to cut down on time to build the system.
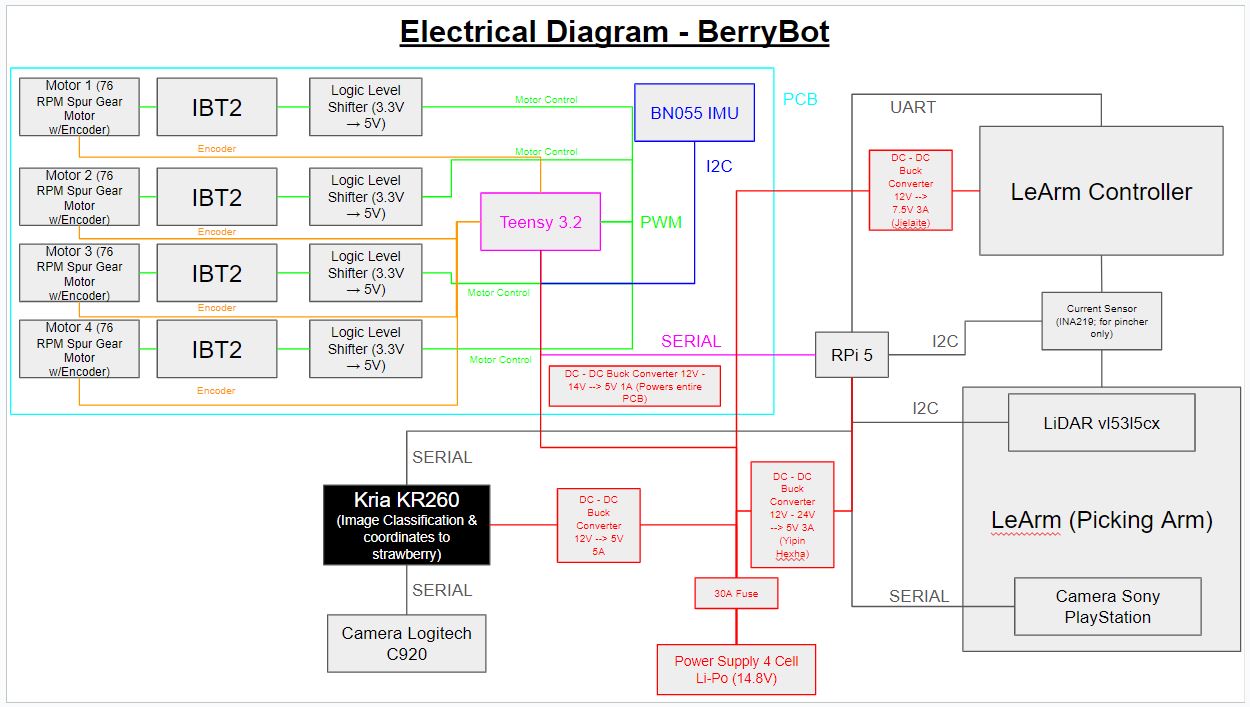
Building the robot and armWe opted to use the RPi5 as the primary onboard computer with plans to port everything to the Kria once the robot was operational.
We quickly achieved joystick-controlled movement for the robot, using a Teensy board to communicate commands to the motor controllers (IBT2) and implemented differential steering with a PID controller.
Our plan involved receiving coordinates from the strawberry detection camera (Real Sense) via Ethernet and ZMQ. Once the robot approached within about 1 meter, the camera on the robot arm would take over, guiding the pincher to within 8 centimeters of the strawberry's center. A LiDAR mounted at a fixed distance would then ensure precise pinching.
To grab the strawberry, we installed a current shunt to measure pinching strength, followed by a rotating motion to twist the strawberry off the plant. Due to some issues with the long-range camera that we will describe later, we had to incorporate some manual processes. The robot was driven to the strawberry bed via a wireless remote to about 30 cm, where the arm-mounted camera used OpenCV color thresholding to detect the strawberry. The arm then autonomously centered the berry within the pincher. However, the actual picking and placing of the berry in the basket was done manually to demonstrate the concept.
For autonomous driving, we planned to use an IMU and wheel encoders. The initial position was not critical, as long as the long-range camera could see a strawberry plant, allowing the robot to navigate to it. The Real Sense D435 also provided distance measurement.
The build started with a piece of plywood, which we cut to make a platform to fit our needs. We attached wheels, designed, and 3D-printed our own brackets. We also created a custom PCB to handle commands to the motors, wheel encoders, and IMU.
Here are some of the images we took while building the bot.
I initially assumed the KR260 was similar to the Nvidia Jetson in terms of programming but quickly learned there were a lot more problems with the documentation.
To get started with the KR260 I followed the guide to get a compatible version of ubuntu on it and then inserted the SD card into the device. After plugging everything in, and using an adapter for to use the Display Port in my HDMI monitor, I found out that it did not work. I thought there was a problem with the adapter so I bought a new one that also did not work. Finally, I used an old monitor which had a mini-Display Port connection and was able to get the screen from the KR260 but this exercise alone took multiple days.
The next step was to learn how to use ROS and run simple Machine Learning models on the KR260 and I needed to get the Intel RealSense camera running on it.
Learning about the tech stack on the KR260 was problematic because the various products and documentation were completely different and confusing. I eventually understood the one most relevant to my use case was Vitis AI and PYNQ but the Vivado toolset would be good to know to get the GPIO pins working to port over the controls from the Raspberry Pi. However, just getting my head around which specific software tools I needed to learn, and use took several days.
The RealSense caused issues because the installation instructions we found required installing PetaLinux and creating a modified OS image using it that was not a regular Ubuntu image. However, the Vitis AI and PYNQ tutorials as well as the getting started page only mentioned Ubuntu 22.04. After trying to install anyway using the instructions in the RealSense Github, we decided to use a regular Logitech 920 camera and instead of getting the distance from the point cloud of the camera, we decided to get it using a projection onto the ground plain and utilizing homography.
The next step was to train a custom model. I used the Kria-RoboticsAI github repo to start with. I followed the tutorials to install ROS and PYNQ on the KR260 but ran into a problem installing it on the host machine since I was using a laptop with Windows and WSL wasn't supported. I was able to use a new hard drive to install Ubuntu on and then installed the Vitis AI repo and built the docker container for PyTorch since that was my preferred framework.
I was able to follow the tutorials to quantize a Resnet model and then convert it to the required format from the Vitis AI quantizer and compiler. However when I transferred the model to the KR260, the model crashed. After a lot of debugging, I found out two potential issues. One was that the subgraph always seemed to be empty and the other was that the PYNQ notebooks through which I was running the model only officially worked with Vitis AI 2.5. There was a patch specifically applied to the KR260 which enabled the use of Vitis AI 3.5 with PYNQ but I was still having the issue after installing the patch.
However, I was able to run the notebooks that came with PYNQ including the one I needed which was the YOLO 3.0 notebook. Once I got that notebook running things became much easier since I finally had some direction of how to complete the project and the specific things I needed to learn.
I used the notebook as a base to start learning PYNQ by changing the code. I could run the DPU with the Resnet model and then eventually the YOLO model and show the results using the DisplayPort feature from PYNQ that allows remotely setting the entire connected DisplayPort screen from the notebook, then I connected the webcam and could run the model while displaying the results continuously on the screen. I then converted the notebook to a python script and ran it with both RESNET and then with YOLO. I now needed to find a dataset and fine tune YOLO v3, which I will describe in the next section.
Gathering the dataFor this task we needed a dataset which would include ripe strawberries, unripe strawberries, and overripe and rotten strawberries growing on the plants.
We specifically needed object detection as opposed to classification or image segmentation in this case because the program running the arm needed the center of the coordinates for each strawberry and the distance. Finding the center from image segmentation would be difficult given the irregular shapes involved.
We found 2 datasets that somewhat met our requirements, but both were very small, with one containing only 28 images.
We also had the option to gather and label the images ourselves but, in this case, we didn't have access to any farm growing strawberries near our area and we had to account for the time require to learn new hardware as well as the very time-consuming task of manually labeling several images.
Luckily, while working on the project an open-source large language model called Florence-2 was released that incorporates spatial information in images, which is unlike other image generation tools or question answering models.
Given a description in natural language as a phrase as well as one of a few fixed tasks like object detection, this model can provide bounding boxes somewhat accurately.
There was also an additional tool called ImageFX that runs their ImaGAN model that can generate photorealistic images given descriptions.
I used a combination of the two to create a dataset. I generated several images from ImageFX, then used Florence-2 to provide a detailed description of what is in those images. These descriptions included the ripeness levels of strawberries present in the image.
The resulting descriptions could then be fed into the "Caption to phrase grounding" task in Florence-2. Instead of just labeling most common objects in the image which a model like Yolo or FasterRCNN trained on a large general dataset would have done by default, the caption to phrase grounding extracted object names from the detailed descriptions and returned a bounding box around all of those objects.
These descriptions are probabilistic, so they contain mentions of several parts of the image instead of just the required strawberry types. Additionally, the strawberries are described and labeled in multiple ways. To take a simple example, the generated bounding box might call them "strawberries" in one case and in other case it might call them "strawberry" or "rotten strawberry" and many different variations.
Therefore, these generated labels had to be further filtered down so that only the locations of the strawberries were in the bounding boxes and they all had a uniform label.
To do this, I generated a large JSON file with the bounding boxes and labels into ChatGPT and asked to replace any labels mentioning strawberries or any variation of the word with the label strawberry.
Finally, I had it format the dataset into the required Pascal VOC format that the version of YOLO was following and to fine tune YOLO on this dataset.
Fine-tuned YOLO modelI mostly work with PyTorch or Tensorflow but this fine tuning had to be done in Darknet as per the instructions, so I used Google Colab and created a notebook with the finished generated data in my Google Drive to train the darknet model.
Then since there were issues with older versions of Tensorflow not working with the required version of the converted from darknet to tensorflow, I created a virtual environment on my local computer and created the model.
Finally, I quantized and then compiled the model to run on the KR260. However the compiled version was still giving the same errors as the previous resnet version I mentioned before.
As a workaround to get a proof of concept working, I noticed that the default YOLO model had a class for potted plants and one for bottles which could be substituted for our 3d printed strawberries and used this model with altered labels for our object detection to finish the project in time.
To map the result to the correct plant so that the arm could go in the right direction, we used homography.
If we had time one more thing that I would have loved to add is a way to add individual ids to each detected strawberry so that it would send the results in a queue via ZMQ and thus the arm would focus on one berry at a time and would remove that id from the queue once the berry was picked.
The final video is presented below:
As with most contests, working on this project was harder than we imagined but it was a great learning experience. The KR260 surprised us in many ways and it was a highly capable board, it just needed much better documentation. There are more things we wish we could add if we had the time, but I think overall the team consider this as a success for the amount of time we had.







{kind=link}
{kind=link}
Comments
Please log in or sign up to comment.