
.gif?auto=format%2Ccompress&gifq=35&w=400&h=300&fit=min)

Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 15 | |||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
In earlier days of computer, interaction with computer was held via punch-cards, trackball, light-gun, keyboards and even via touch screen. All of these devices requires some kind of physical contact to operate them.
With decade-by-decade, new technology improves over the old one. Wireless input devices become popular as they provide clean and less cluttered desk. With the current enhancement in software as well as hardware, a new kind of inputs are possible which are: Visual and Speech Input.
This article will help you to learn Speech Recognition technology provided in Windows 10 IoT Core. At the end of the topic, we will create a robot using Windows 10 IoT Core and Raspberry Pi 2 running Speech Recognition application. This Speech Recognition application enables robot to perform various movement task (for ex: move forward, turn, stop, etc.) based upon user interaction by speech.
New to the Windows 10 IoT Core? or Beginner? refer this link first.
This article was updated on March 30, 2016What is Speech Recognition?
In single line, Speech Recognition means translation of spoken words into possible equivalent text. Speech Recognition can be divided into main two components: Signal Processing and Speech Decoder. We don't have to bother with its complexity because Microsoft has already developed solution for that. We just have to use their Speech libraries.
Let's start with basic idea:
- Create Speech Recognition Grammar (SRGS Grammar)
- Initialize Speech Recognizer Object and Load Grammar (SpeechRecognizer)
- Register for Speech Recognizer Events and Create Handler
Before starting with speech recognition, we need to understand how we can program Universal Windows App to understand our language or commands. To do so, we need to create Speech Recognition Grammar. Speech Recognition Grammar can be created using SRGS Grammar for Universal Windows App:
- Use XML to create grammar documents that conform to the Speech Recognition Grammar Specification (SRGS) Version 1.0, the W3C standard for speech recognition grammars.
Note: Other possible ways are available in .Net Framework but they are not supported in UWP when this article was written. Which are:
- Author grammars programmatically using members of the GrammarBuilder and Choices classes in the System.Speech.Recognition namespace.
- Use constructors and methods of classes in the System.Speech.Recognition.SrgsGrammar namespace to programmatically create SRGS-compliant grammars.
We will start with XML Grammar. Before we begin creating grammar file, we need to envision and define how user will interact with our application. In context of this project, user will command robot to move in either direction, stop and command to engage/disengage obstacle detection. We can make list of speech vocabulary which are as follows:
- Move Forward
- Move Reverse
- Turn Right
- Turn Left
- Stop
- Engage Obstacle Detection
- Disengage Obstacle Detection
For this vocabulary, we need to design XML Grammar. We just need to follow some basic rules of SRGS v1.
To create SRGS grammar some basic rules must be follow which are:
- Root element must be
grammar - Attribute grammar's version, language and XML namespace must be present.
- Grammar must contain at least one
ruleelement. (Rule element contains a word or phrase that user can speak). - Each
ruleelement must have unique id attribute.
We have seen basic required structure for SRGS grammar. Now we need to create vocabulary for it. Vocabulary is a set of words that produces something meaningful command to the robot.
For ex: "Move Forward" or "Move Reverse", here Move comes before Forward and Reverse. Thus in rule, it must comes first before Forward and Reverse. So we can extract Forward and Reverse into another rule. See image given below:
What is root rule? It is the starting node or root node to load when Speech Recognizer loads grammar. It is optional. You can ignore it but then you need to specify root node programmatically.
What is root attribute in grammar tag? Root attribute defines startup rule for speech recognizer when it loads grammar. If it not specified as attribute, you need to specify it programmatically.
This article is intended for beginner purpose and so it not possible to cover complex SRGS tags and attributes. You can learn more about SRGS grammar at MSDN and W3C.
We just created SRGS grammar for our robot. Now, we will see how to implement Speech Recognizer for Universal Windows App.
SpeechRecognizer class is available in Windows.Media.SpeechRecognition namespace. Import the namespace into your code file. Before initializing, we need to create XML Grammar file into our project. We have already created content for grammar file in previous section.
Note: If 'CompilationResult' failes, there might be some problem with the Mic interface. Verify connection with the microphone. Check whether it is detected in default IoT Core app or not.In the last step, we have started speech recognizer and is ready to listen speech and parses it. After successful parsing, 'ContinuousRecognitionSession' will raises an event named 'ResultGenerated'. This event provide parsing result as event arguments that can be processed to perform task based upon spoken speech. We can also listens to the recognizer's state by event 'StateChanged' to give speaker some indication that recognizer is listening.
Here, 'MyRecognizerStateChanged' is function which will be raised by 'MyRecognizer' when its state changed from one to another. It will provide valuable state information that when 'MyRecognizer' has started to listening and when stops to listen. After it stops listening, 'MyRecognizer' parses the speech against provided grammar and raises event 'ResultGenerated' on successful.
Note: You do not need to create function 'MyRecognizer_StateChanged' and 'MyRecognizer_ResultGenerated' by yourself. Instead, Visual Studio provides a way to create them automatically for you. You can create them automatically by Visual Studio using<Tab Key>twice on the right hand side of the += of an event.
You can also register event handlers just after initializing SpeechRecognizer object.
We are almost done!
In previous section, we have configured custom grammar and speech recognizer for Universal Windows App. When Speech Recognizer successfully parses spoken speech, it will raises event 'ResultGenerated'. This event contains parsed result as argument. Let's see how to detect what is being spoken and what to do based upon spoken speech:
Here, 'args' argument passed to the event handler by SpeechRecognizer on successful parsing of speech. 'args.Result.Text' is of string type. It contains the spoken speech as text. You can perform speech specific task using conditional block.
It is not feasible to show complete code to drive robot. I have provided a static class named 'MotorDriver' which contains various functions to drive robot. This class manages Gpio pins to drive robot. Complete source code is given at the end of the project. If you are newer to the Raspberry Pi 2 and Windows 10 IoT, refer this link to get started with.Before deploying Universal Windows App to the Raspberry Pi 2, we need to set appropriate device capability for the application to run with specific hardware access rights. In this application's context, we need external device 'Microphone' to use. To enable 'Microphone' in package manifest:
All done at software side. Now its time to wire up hardware. Source code is provided at the end of the article.
Major part to implement Speech Recognition is done and it is not feasible to explain each and every line of the code here. Instead, source code is well commented. Ask for any query.
Robot need to recognize speech commands whenever it is powered on. To achieve this, you need to register your app as startup app so that every time Raspberry Pi 2 boots, it will start your app just after booting. To do so, you first need to deploy your app to the Raspberry Pi 2 and then register it as startup application.
Before deployment, it is good to change application's package family name:
After changing package family name, deploy application to the remote device (your Raspberry Pi 2).
If you don't know proper way to deploy your application to the Raspberry Pi 2, refer this link.
Once app is successfully deployed, you need to register app as startup application. You can register your app as startup using two methods: using PowerShell or Windows IoT Core's Web-Management Portal. I'll go with second method. Open web-browser and follow:
Having trouble while registering as startup app? Refer this article.
Once you successfully register your app as startup app, reboot Raspberry Pi 2 and see whether your application starts after booting or not. If not, verify all of the steps from deployment to the registration. With successful startup of the app, now it's time to wire up things.
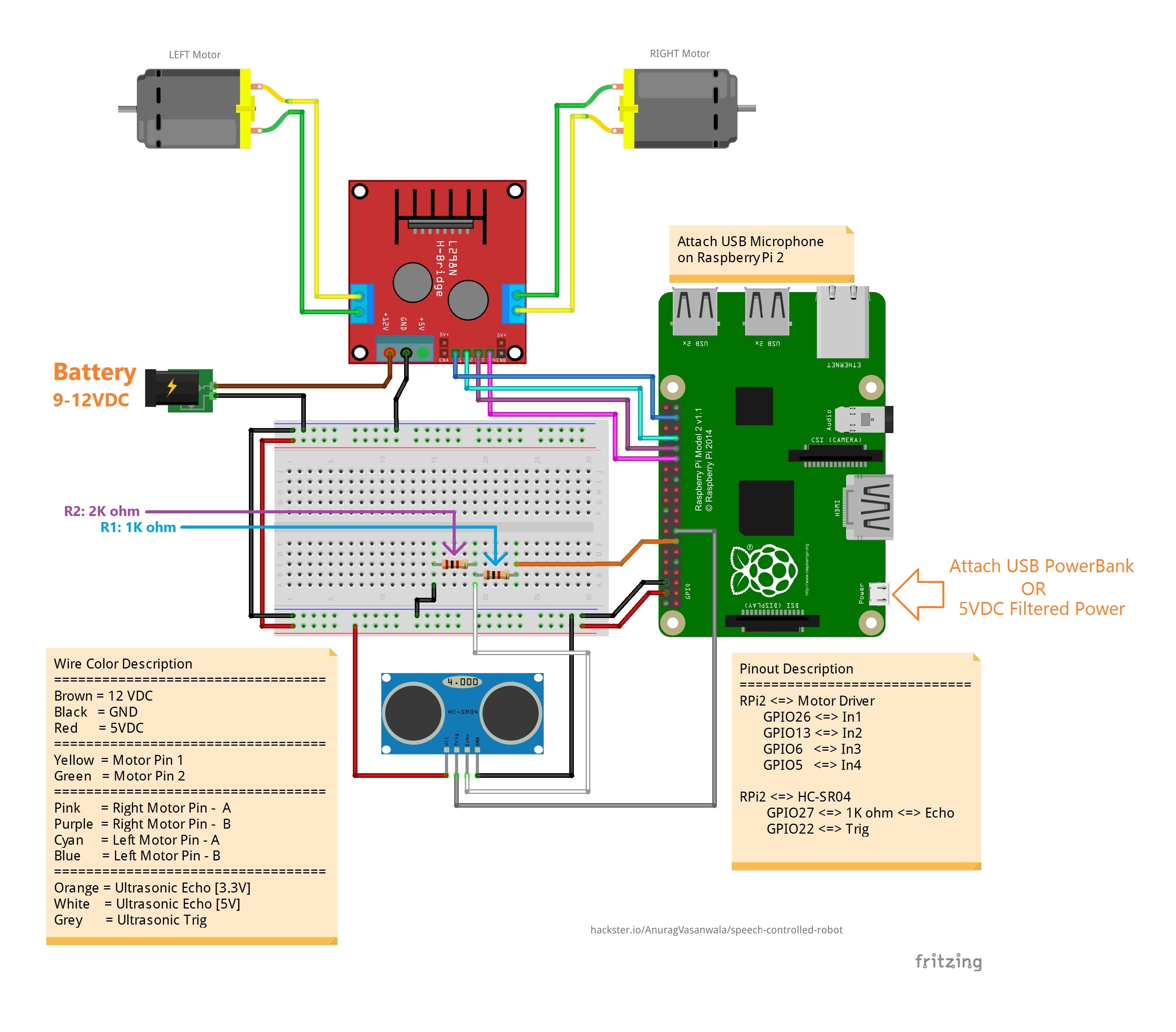
Hardware parts are consists of robot chassis (with DC motors), Raspberry Pi 2 (having Windows 10 IoT Core), battery, distance sensor, etc. Power comes from the Motor Battery (shown in image at left side 'Battery:9-12VDC') and directly goes to the H-Bridge motor driver. A separate power supply for Raspberry Pi 2 is required. USB PowerBank is suitable to provide sufficient power to Raspberry Pi 2. In absence of USB PowerBank or Filtered 5VDC Supply, a separate voltage regulator circuit (using 7805) is required to power up Raspberry Pi and Ultrasonic Distance Sensor.
If you do not have USB PowerBank or 5VDC filtered supply, you can use Motor Battery(shown in above image at left side - Orange Color, Battery : 9-12VDC) to power up Raspberry Pi 2. The schematic for the configuration is provided at the end of the article (named 'Schematic : Motor Battery').
Ultrasonic Distance sensor works on 5V while Raspberry Pi 2 works on 3.3V. We can't directly connect sensor's Echo pin directly to the Raspberry Pi's pin as it will have 5V output. It will burn Raspberry Pi. Thus we need to drop down sensor's output voltage to 3.3V before sending to Raspberry Pi. Sensor's voltage can be drop down by using voltage divider circuit. Thus, Vout can be calculated as:
R1 = 1000 ohmR2 = 2000 ohmVin = 5V (Sensor's Echo pin)Vout = 5 * (2000 / (1000 + 2000)) = 3.3V (To the Raspberry Pi 2)
WARNING: Do not connect Ultrasonic Distance Sensor's Echo pin directly to the Raspberry Pi's GPIO pin. It may burn out Raspberry Pi. Use logic level converter or appropriate voltage divider instead.
Known IssuesSpeech Recognition won't works (Build 10586)
Speech recognition and syntheses won't works on any of IoT device (RPi2, MinnowBoard MAX and Dragonboard 410c) if you have installed Windows IoT build 10586.
Solution: At this moment, no valid solution is available. I hope Windows IoT team will resolve this bug in next build. Still, if you want to manipulate speech recognition, revert back to old version 10240 and it will work like charm.
Microphone ProblemSpeech recognition definitely requires a high quality microphone. You can still use low quality microphone when it is near but when microphone is far away about 1-2 meter, it won't recognize accurately.
Solution: (Option 1) : Purchase high quality microphone. Sometime it may happens that even after high quality microphone, it won't recognize correctly. In such case, loud voice needed. (Option 2) : Wireless microphone would be great. You can control robot even from great distance without worry about external noise. You can purchase one of it or make your own by referring this video.
It is obvious that recognizer needs some time to process speech. It is not problem or issue but it may cause problem in real-time system.
Suppose, we have a high speed robot cum car which follows our speech command. Let's assume, car will follow on our speech command after 600-2000ms (due to processing delay). So if we command to stop, car will parse the signal after some time which may lead to a catastrophic event.
Solution: Right now (when this article was written), there is no appropriate solution is available. Hope, it will be resolved in future. :)
People of different region use different pronunciation for a single word. Speech Recognizer unable to parse speech, if spoken word's pronunciation is different than what it is programmed to.
Solution: You can specify language and region in SRGS XML grammar file to parse pronunciation for the specific region.
Let's say, we want to parse English(UK), we need to set attribute of grammar tagxml:lang="en-GB". Here, ISO country code for UK is GB. Thus 'en-GB' tells the speech recognizer to parse speech based on English(UK) pronunciation. Another example, for Canadian French, use "fr-CA".
Unwanted sound and vibration, caused by one or more external entity will effect the processing accuracy. Sometimes, recognizer won't understand speech even if it was correctly spoken.
Solution: It may not be possible to resolve or eliminate such noise. At current level of technology, we can only hope to use such technology in noise free area. Another possible solution is to use intelligent microphone that is able to reduce noise (called noise cancellation microphone).
With the release of build 10531, Windows IoT Core supports generic audio device. Most of USB Microphone or USB SoundCard requires USB Generic Driver. If your device uses generic driver, it will work.
Solution: Try another USB Microphone or USB SoundCard.
In my case, I have purchased a USB SoundCard. It worked perfectly. I attached Microphone into Mic jack of the SoundCard. You can buy USB SoundCard from Amazon.com or other online shopping websites. Indian can buy USB SoundCard from Amazon.in.
There is no limitation when it comes to new ideas. This article explores the basic implementation of the speech recognition. Further, you can extend the project by providing visual indication of parsed result. For example, turn on green led for a second after successful parse of spoken command else turn on red led for a second. In addition, to prevent accidental commands, you can also program the robot to instruct when to listen and when sleep.
Those who have carefully seen animated title image of the project will know that I have not covered something that I have shown there. Watch it carefully and try to implement that hidden feature in your robot.
Good Luck :)







{kind=link}
Comments
Please log in or sign up to comment.