


Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
| ||||||
 |
| |||||
With the introduction of ChatGPT in the last year, the concept of large language models has become popular among technology lovers. I decided to run a large language model locally on my PC as a first step and add voice conversation functionality to it as a next step. I thought to myself, it would be interesting if, in addition to voice conversation with artificial intelligence, we could also control electronic hardwares with this system. Next, we'll learn how to have a voice conversation with a language model and turn it into a voice assistant, which can controls our electronic devices, plays music, and tell us the temperature and humidity.
you can see full video tutorial in below
first of all I wrote a program using langchain library in Python and Ollama in windows. by help of these tools we can run a LLM locally on our PC. for these purpose go to Ollama webpage and download Ollama for your OS. after installing Ollama you must download your desired LLM model, for example I downloaded phi model on my computer. for more details please see Ollama github page. after installing your LLM model, you must install these packages in python:
pip install langchain
pip install SpeechRecognition
pip install PyAudio
pip install pyttsx3With the help of these packages, you can write a program to have an audio conversation with a large language model. This program recognizes your voice and then reads the produced text of the language model for you. you can see the program in below:
from langchain_community.llms import Ollama
import pyttsx3
import speech_recognition as sr
llm = Ollama(model = "phi")
engine = pyttsx3.init()
def audio_recognizer():
speech = sr.Recognizer()
with sr.Microphone() as source:
audio = speech.listen(source)
text = ''
try:
text = speech.recognize_google(audio,language = "en-US")
#print(text)
except:
print("I can't hear you.....")
return text
while True:
print("speak with me: ")
question = audio_recognizer()
print("your question: ",question)
response = llm.invoke(f"{question} please give me an brief answer.")
print(response)
engine.say(response)
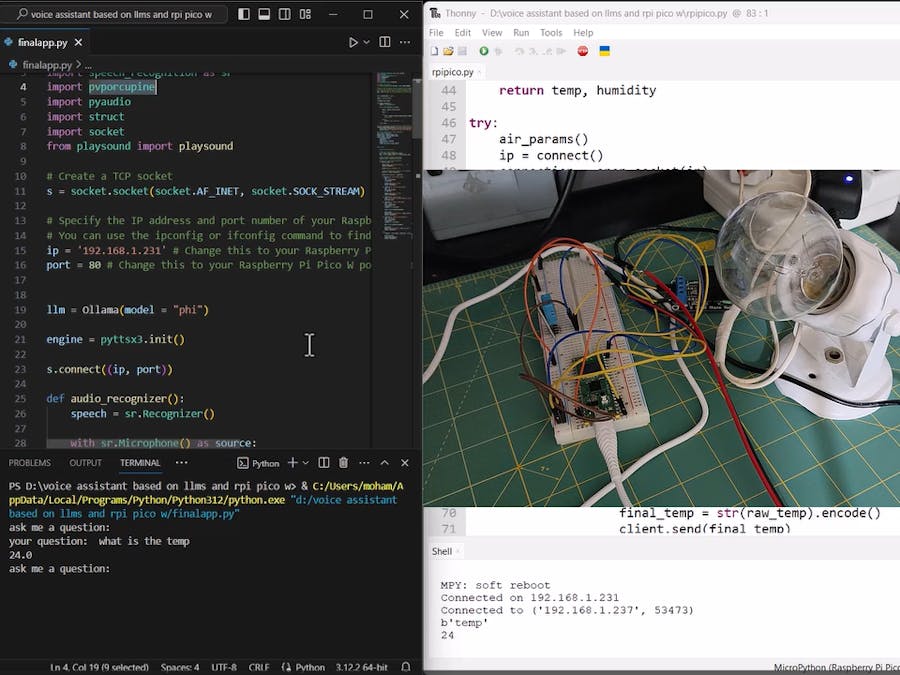
engine.runAndWait()After writing this program, it is time to define a wake word detection for our voice assistant. I used the picovoice platform for this purpose. But I will not explain about this issue here and I will only talk about the main program. Before talking about the main program, I will introduce my simple hardware. I used a Raspberry Pi Pico W microcontroller to control devices in receiving voice commands. And with the help of Raspberry Pi and a SSR relay I control the lamp. I also used a DHT11 sensor to measure the temperature and humidity of the environment. You can easily understand circuit diagram from the code.
Now we come to our main program. you need to install these modules in python.
pip install struct
pip install playsound
pip install pvporcupinein main program we use socket programming to send commands to Raspberry Pi Pico W. you can see source code in below. you must run this program on your PC or on a SBC like Raspberry Pi 5 or Nvidia Jetson Nano.
from langchain_community.llms import Ollama
import pyttsx3
import speech_recognition as sr
import pvporcupine
import pyaudio
import struct
import socket
from playsound import playsound
# Create a TCP socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# Specify the IP address and port number of your Raspberry Pi Pico W
# You can use the ipconfig or ifconfig command to find out the IP address of your device
ip = '192.168.1.231' # Change this to your Raspberry Pi Pico W IP address
port = 80 # Change this to your Raspberry Pi Pico W port number
llm = Ollama(model = "phi")
engine = pyttsx3.init()
s.connect((ip, port))
def audio_recognizer():
speech = sr.Recognizer()
with sr.Microphone() as source:
audio = speech.listen(source)
text = ''
try:
text = speech.recognize_google(audio,language = "en-US")
#print(text)
except:
print("I can't hear you.....")
return text
# Create a Porcupine instance with your custom wake word
handle = pvporcupine.create(
access_key='your access key', # Get this from Picovoice Console
keyword_paths=['your wake word detection model from picovoice platform']) # Download this from Picovoice Console
# Get the required audio input parameters
pa = pyaudio.PyAudio()
sample_rate = handle.sample_rate
frame_length = handle.frame_length
audio_stream = pa.open(
rate=sample_rate,
channels=1,
format=pyaudio.paInt16,
input=True,
frames_per_buffer=frame_length)
while True:
#print("speak with me: ")
# Read one frame of audio
pcm = audio_stream.read(frame_length)
pcm = struct.unpack_from("h" * frame_length, pcm)
# Pass the audio frame to Porcupine
keyword_index = handle.process(pcm)
# Check if a wake word is detected
if keyword_index >= 0:
engine.say("i am at your service........")
engine.runAndWait()
print("ask me a question: ")
# Wake word detected, listen for the question
question = audio_recognizer()
print("your question: ",question)
if question == "turn on the light":
cmd = 'o'
cmd = cmd.encode()
s.send(cmd)
engine.say("light is on")
engine.runAndWait()
elif question == "turn off the light":
cmd = 'f'
cmd = cmd.encode()
s.send(cmd)
engine.say("light is off")
engine.runAndWait()
elif question == "play a song":
song = "D:\\voice assistant based on llms and rpi pico w\\['1'].wav"
playsound(song)
elif question == "what is the temp":
cmd = "temp"
cmd = cmd.encode()
s.send(cmd)
response = s.recv(1024)
temp = float(response.decode())
print(temp)
engine.say(f"temperature is {temp} degree Celsius")
engine.runAndWait()
elif question == "what is the humidity":
cmd = "humidity"
cmd = cmd.encode()
s.send(cmd)
response = s.recv(1024)
hum = float(response.decode())
print(hum)
engine.say(f"humidity is {hum} percent")
engine.runAndWait()
else:
response = llm.invoke(f"{question}, please give me a brief answer.")
print(response)
engine.say(response)
engine.runAndWait()also we have a script for Raspberry Pi Pico W, upload this MicroPython script on your Microcontroller.
import socket
import network
from time import sleep
from machine import Pin
import dht
ssid = 'Mrsh77'
password = '1m77n2299215r77#'
def connect():
#Connect to WLAN
wlan = network.WLAN(network.STA_IF)
wlan.active(True)
wlan.connect(ssid, password)
while wlan.isconnected() == False:
print('Waiting for connection...')
sleep(1)
ip = wlan.ifconfig()[0]
print(f'Connected on {ip}')
return ip
def open_socket(ip):
address = (ip,80)
connection = socket.socket()
connection.bind(address)
connection.listen(1)
#print(connection)
return connection
led_pin = Pin(0,Pin.OUT)
led_pin.value(0)
dht_sensor = dht.DHT11(Pin(15))
def air_params():
sleep(4)
dht_sensor.measure()
temp = dht_sensor.temperature()
humidity = dht_sensor.humidity()
return temp, humidity
try:
air_params()
ip = connect()
connection = open_socket(ip)
while True:
# Accept a connection from a client
client, addr = connection.accept()
print(f'Connected to {addr}')
while True:
# Receive data from the client
data = client.recv(1024)
if data:
# Print the data to the console
print(data)
if data == b'o':
led_pin.value(1)
elif data == b'f':
led_pin.value(0)
# Send a response back to the client
elif data == b"temp":
raw_temp, _ = air_params()
print(raw_temp)
final_temp = str(raw_temp).encode()
client.send(final_temp)
elif data == b"humidity":
_, raw_hum = air_params()
print(raw_hum)
final_hum = str(raw_hum).encode()
client.send(final_hum)
except KeyboardInterrupt:
# Close the server socket
connection.close()
machine.reset()now, you can speak with a LLM and control your devices using voice commands.
I hope to you enjoy this project.










{kind=link}
Comments
Please log in or sign up to comment.