
_qgh11KVK5v.gif?auto=format%2Ccompress&gifq=35&w=400&h=300&fit=min)

Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
 |
| |||||
| ||||||
Robotic Arm has already been changing the evolution of human being. But the knowledge is usually kept as industrial level, while building this project, it was still difficult to find open source guides and libraries that both utilizes and controls the robotic arm, so I've decide to write a guide on how to use the robotic arm using Jetson Nano to sort out recyclable garbage.
In this article, we will be discussing how to train the data using and deploying them through Jetson Nano.
For this project, we are focusing on UN Sustainable Develop Goals
- 9. Industry, Innovation and Infrastructure
- 12. Responsible Consumption and Production
The Jetson pack contains a Quad-core ARM A57 @ 1.43 GHz with 128-core Maxwell, allowing the device to run full on linux.
We utilized couple of libraries such as qt 5 where you have to install prior making the project work. And after not finding much support on dobot's website, we've still managed to get Dobot Arm working with Jetson Nano.
The equipment needed is a Jetson Nano, Camera, Robotic Arm and Suction Cup Addon. Make sure you have at least 5v/2.5 amp power supply, between camera. Personally I've tried 2.1amp and it was not enough. Also, use the power jack over the micro usb power, this has proven to be much more stable. You first need to place a Jumper on J48, then the power jack on J25 would work. I've tried up to 5v/6amp and it was fine.
For further instruction, you can follow this video by JetsonHacks on youtube
Installation of OS Image and Jetpack can be downloaded at
https://developer.nvidia.com/embedded/jetpack
NVIDIA has already wrote down a pretty detailed guide on Jetson NANO setup, the guide can be seen at
https://courses.nvidia.com/courses/course-v1%3ADLI%2BC-RX-02%2BV1/course/
There are a lot of guides out there that trains these on windows 10 machine, this guide follows through a lot of it from Evan's Windows 10 guide. But after 2 days of unsuccessfully tinkering their examples I've decided to run this on Jetosn Nano instead. As the object_detection model does not yet run on tensorflow 2.0, we will be using tensorflow 1.14.0 to get this project running in stable fashion
Luckily, Cuda Toolkit and cuDNN is already included in the Jetpack so we can get straight to business. The Jetson NANO will be pretty slow to train, and you can follow the same method using other GPU based computer or server to achieve faster results via Ubuntu.
After Jetpack being installed we can follow instructions via https://docs.nvidia.com/deeplearning/frameworks/install-tf-jetson-platform/index.html
Install system packages required by TensorFlow:
$ sudo apt-get update
$ sudo apt-get install libhdf5-serial-dev hdf5-tools libhdf5-dev zlib1g-dev zip libjpeg8-dev
Install system packages required by TensorFlow:
$ sudo apt-get update
$ sudo apt-get install libhdf5-serial-dev hdf5-tools libhdf5-dev zlib1g-dev zip libjpeg8-devInstall and upgrade pip3.
$ sudo apt-get install python3-pip
$ sudo pip3 install -U pip testresources setuptoolsInstall and upgrade pip3.
$ sudo apt-get install python3-pip
$ sudo pip3 install -U pip testresources setuptoolsInstall the Python package dependencies.
$ sudo pip3 install -U numpy==1.16.1 future==0.17.1 mock==3.0.5 h5py==2.9.0 keras_preprocessing==1.0.5 keras_applications==1.0.8 gast==0.2.2 enum34 futures protobufInstall the Python package dependencies.
$ sudo pip3 install -U numpy==1.16.1 future==0.17.1 mock==3.0.5 h5py==2.9.0 keras_preprocessing==1.0.5 keras_applications==1.0.8 gast==0.2.2 enum34 futures protobufAfter that you can install tensorflow via
$ sudo pip3 install --pre --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v43 'tensorflow-gpu==1.14.0'After that you can test the tensorflow installed successfully via
$ python3
>>> import tensorflow as tf
>>> hello = tf.constant('Hello, Tensorflow!')
>>> sess = tf.Session()
>>> print(sess.run(hello))And output should be Hello, Tensorflow! For our guide we will include these in workspace folder, we will first need tensorflow model to sample it with
$ mkdir workspace
$ cd workspace
$ mkdir tensorflow1
$ cd tensorflow1
$ git clone https://github.com/tensorflow/models.gitNow we can will install all the dependencies
$ sudo python3 -m pip install --upgrade pip
$ sudo pip3 install pillow
$ sudo pip3 install lxml
$ sudo pip3 install Cython
$ sudo pip3 install contextlib2
$ sudo pip3 install jupyter
$ sudo pip3 install matplotlib
$ sudo pip3 install pandas
$ sudo pip3 install pycocotools
$ sudo pip3 install absl-py
$ sudo apt-get install python-opencvSet the PYTHONPATH environment variable
$ export PYTHONPATH=$PYTHONPATH:~/workspace/tensorflow1/models:~/workspace/tensorflow1/models/research:~/workspace/tensorflow1/models/research/slim
$ export PATH=$PATH:PYTHONPATH
$ cd ~/workspace/tensorflow1/model/research
$ python setup.py build
$ python setup.py installWe can test the default model by going into object_detection folder
$ cd ~/workspace/tensorflow1/model/research/object_detection
$ jupyter notebook object_detection_tutorial.ipynbWhen all done, you will have following running.
We will be using dividing TrashNet into separates 6 categories as following
- Cardboard
- Glass
- Plastic
- Metal
- Trash
- Paper
For this article we just took some simple images of our own so you can get this trained really quickly, and only focusing on cardboard and plastic. Optionally, you can download the entire dataset at https://drive.google.com/drive/folders/0B3P9oO5A3RvSUW9qTG11Ul83TEE and it contains total about 2600 images, 501 glass, 403 cardboard, 482 plastic, 410 metal and 137 trash.
In our example we just took 800 images of our own so we can get this trained relatively quickly on Jetson Nano.
$ git clone https://github.com/Nyceane/Trash-sorting-robotic-arm.gitCopy trash-sorting-robotic-arm/object_detection/* files into model/research/object_detection and open up terminalt and install following dependencies or you can put 80% of the images in /images/train folder, and /images/test folder.
Once that's done, we will be labeling our images, we will be using LabelImg, we can either build from source or just download binary from https://github.com/tzutalin/labelImg
We will also use ssd_mobilenet_v3_large_coco from model zoo, this is small enough to load into memory on AI on the edge.
http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v3_large_coco_2019_08_14.tar.gz
extract that into object_detection folder
Once this is all done, we will Generating training data by entering command under object detection folder
$ python3 xml_to_csv.pyThis creates a csv file for all the bounding objects on both training and testing files
next we will change generate_tfrecord to our own label classes. This will be automatically included if you just get it from repo. if you have more classes, you can add it from line 31
"""
Usage:
# From tensorflow/models/
# Create train data:
python generate_tfrecord.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record
# Create test data:
python generate_tfrecord.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record
"""
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('image_dir', '', 'Path to the image directory')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'cardboard':
return 1
elif row_label == 'glass':
return 2
elif row_label == 'plastic':
return 3
elif row_label == 'metal':
return 4
elif row_label == 'trash':
return 5
elif row_label == 'paper':
return 6
else:
print(row_label)
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.path.join(os.getcwd(), FLAGS.image_dir)
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()After that we can launch the python file via and get the message
$ python3 generate_tfrecord.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record
Successfully created the TFRecords: /home/ai/workspace/tensorflow1/models/research/object_detection/train.record
$ python3 generate_tfrecord.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record
Successfully created the TFRecords: /home/ai/workspace/tensorflow1/models/research/object_detection/test.recordnext we will create a labelmap.pbtxt under training folder, to map the labels and ids.
item {
id: 1
name: 'cardboard'
}
item {
id: 2
name: 'glass'
}
item {
id: 3
name: 'plastic'
}
item {
id: 4
name: 'metal'
}
item {
id: 5
name: 'trash'
}
item {
id: 6
name: 'paper'
}Next we will follow the similar config file to faster_rcnn_inception_v2_pets.config
Line 14. Change num_classes to the number of different objects you want the classifier to detect. For the above basketball, shirt, and shoe detector, it would be num_classes : 6 .
Line 164. Change fine_tune_checkpoint to:
- fine_tune_checkpoint : "/home/ai/workspace/tensorflow1/models/research/object_detection/ssd_mobilenet_v3_large_coco_2019_08_14/model.ckpt"
Lines 187 and 189. In the train_input_reader section, change input_path and label_map_path to:
- input_path : "/home/ai/workspace/tensorflow1/models/research/object_detection/train.record"
- label_map_path: "/home/ai/workspace/tensorflow1/models/research/object_detection/training/labelmap.pbtxt"
Line 198. remove num_examples as it checks entire folder
Lines 198 and 200. In the eval_input_reader section, change input_path and label_map_path to:
- input_path : "/home/ai/workspace/tensorflow1/models/research/object_detection/test.record"
- label_map_path: "/home/ai/workspace/tensorflow1/models/research/object_detection/training/labelmap.pbtxt"
# SSDLite with Mobilenet v3 large feature extractor.
# Trained on COCO14, initialized from scratch.
# 3.22M parameters, 1.02B FLOPs
# TPU-compatible.
# Users should configure the fine_tune_checkpoint field in the train config as
# well as the label_map_path and input_path fields in the train_input_reader and
# eval_input_reader. Search for "PATH_TO_BE_CONFIGURED" to find the fields that
# should be configured.
model {
ssd {
inplace_batchnorm_update: true
freeze_batchnorm: false
num_classes: 6
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
use_matmul_gather: true
}
}
similarity_calculator {
iou_similarity {
}
}
encode_background_as_zeros: true
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.2
max_scale: 0.95
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.3333
}
}
image_resizer {
fixed_shape_resizer {
height: 320
width: 320
}
}
box_predictor {
convolutional_box_predictor {
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.8
kernel_size: 3
use_depthwise: true
box_code_size: 4
apply_sigmoid_to_scores: false
class_prediction_bias_init: -4.6
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
random_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.97,
epsilon: 0.001,
}
}
}
}
feature_extractor {
type: 'ssd_mobilenet_v3_large'
min_depth: 16
depth_multiplier: 1.0
use_depthwise: true
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.97,
epsilon: 0.001,
}
}
override_base_feature_extractor_hyperparams: true
}
loss {
classification_loss {
weighted_sigmoid_focal {
alpha: 0.75,
gamma: 2.0
}
}
localization_loss {
weighted_smooth_l1 {
delta: 1.0
}
}
classification_weight: 1.0
localization_weight: 1.0
}
normalize_loss_by_num_matches: true
normalize_loc_loss_by_codesize: true
post_processing {
batch_non_max_suppression {
score_threshold: 1e-8
iou_threshold: 0.6
max_detections_per_class: 10
max_total_detections: 10
use_static_shapes: true
}
score_converter: SIGMOID
}
}
}
train_config: {
batch_size: 12
sync_replicas: true
startup_delay_steps: 0
replicas_to_aggregate: 32
num_steps: 400000
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
fine_tune_checkpoint: "/home/ai/workspace/tensorflow1/models/research/object_detection/ssd_mobilenet_v3_large_coco_2019_08_14/model.ckpt"
fine_tune_checkpoint_type: "detection"
optimizer {
momentum_optimizer: {
learning_rate: {
cosine_decay_learning_rate {
learning_rate_base: 0.4
total_steps: 400000
warmup_learning_rate: 0.13333
warmup_steps: 2000
}
}
momentum_optimizer_value: 0.9
}
use_moving_average: false
}
max_number_of_boxes: 10
unpad_groundtruth_tensors: false
}
train_input_reader: {
tf_record_input_reader {
input_path: "/home/ai/workspace/tensorflow1/models/research/object_detection/train.record"
}
label_map_path: "/home/ai/workspace/tensorflow1/models/research/object_detection/training/labelmap.pbtxt"
}
eval_config: {
}
eval_input_reader: {
tf_record_input_reader {
input_path: "/home/ai/workspace/tensorflow1/models/research/object_detection/test.record"
}
label_map_path: "/home/ai/workspace/tensorflow1/models/research/object_detection/training/labelmap.pbtxt"
shuffle: false
num_readers: 1
}When all ready, we can start training our model by doing following command. Since train.py is deprecated and running lots of issues, we'd be using model_main instead.
This is just to show the capability of Jetson Nano, if you feel training on Jetson Nano is too slow, you can use a more powerful GPU machine on Linux with almost exact same method. Jetpack has already pre-installed CUDA and cuDNN, in case if you want to do it on a server, you just need to download CUDA 10.0 and cuDNN v7.6.4 for CUDA 10.0 as well as drivers for your graphics card.
$ python3 model_main.py --logtostderr --model_dir=training --pipeline_config_path=training/ssdlite_mobilenet_v3_large_320x320_coco.configAdditionally, you can check the training progress via tensorboard to check the progress by opening another terminal
$ cd ~/workspace/tensorflow1/models/research/object_detection
$ tensorboard --logdir=training
TensorBoard 1.14.0 at http://ai:6006/After a couple of hours, and loss always being lower than 0.05, we can stop the training via Ctrl + C, and now we will need our model, we can do it via following command, where XXX is your highest iteration of ckpt file
$ python3 export_inference_graph.py --input_type image_tensor --pipeline_config_path training/ssdlite_mobilenet_v3_large_320x320_coco.config --trained_checkpoint_prefix training/model.ckpt-XXX --output_directory inference_graphThe frozen model should now be saved in inference_graph folder. We can test the model by running following message and you should see the following.
$ python3 Object_detection_webcam.pyNow we are getting ready for robotic arm, for the article sample, we will focus on getting robot to sorting 2 categories, you can easily extend this to additional categories. But first, we'll first need the python libraries to do so
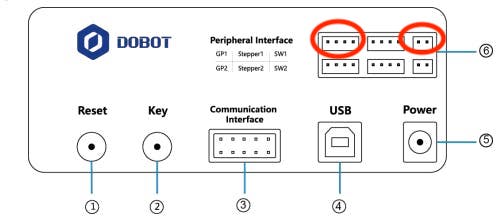
pip3 install pydobotWe would need to connect arm on SW1 and GP1 to power the suction cup
When all done it should look like this.
This would give us the library to control the Dobot Magician itself. Next we need to go through Dobot Studio and record all the coordinates that's needed for the robotic arm to move.
Alternatively, you can just get the coordinates straight out of calibrate.py, this way you can skip the entire Dobot Studio on another machine and just get it from Jetson NANO instead.
Now that we have the coordinates from that, we can translated these into our code in testmove.py on Jetson Nano, suction cup can be controlled via device.suck(True)
import time
from serial.tools import list_ports
from pydobot import Dobot
port = list_ports.comports()[0].device
device = Dobot(port=port, verbose=True)
(x, y, z, r, j1, j2, j3, j4) = device.pose()
print(f'x:{x} y:{y} z:{z} j1:{j1} j2:{j2} j3:{j3} j4:{j4}')
device.move_to(96, 100, -12, -47, wait=False)
device.move_to(166, -211, -52, -47, wait=False)
device.suck(True)
time.sleep(1)
device.move_to(300, 7, 15, 5, wait=False)
device.suck(False)
time.sleep(0.5)
device.move_to(96, 100, -12, -47, wait=False)
device.close()After that, we can run our code
python3 testmove.pyRepeat the same for the right side, the code will be written in robot_arm.py in attachment section, and integrated into final code. If you wish to set 3rd category, simply follow the same step and drop the 3rd category somewhere.
######## Moving Dobot Arm #########
#
# Author: Peter Ma
# Date: 1/20/20
# Description:
# This program moves dobot arm
# Import packages
import threading
import time
from serial.tools import list_ports
from pydobot import Dobot
port = list_ports.comports()[0].device
device = Dobot(port=port, verbose=True)
isRoboticActive=False
thread_left = threading.Thread(target=_robotic_left, daemon=True)
thread_right = threading.Thread(target=_robotic_right, daemon=True)
def _robotic_left():
(x, y, z, r, j1, j2, j3, j4) = device.pose()
print(f'x:{x} y:{y} z:{z} j1:{j1} j2:{j2} j3:{j3} j4:{j4}')
if isRoboticActive == False:
isRoboticActive = True
device.move_to(96, 100, -12, -47, wait=False)
device.move_to(166, -211, -52, -47, wait=False)
device.suck(True)
time.sleep(1)
device.move_to(300, 7, 15, 5, wait=False)
device.suck(False)
time.sleep(0.5)
device.move_to(96, 100, -12, -47, wait=False)
isRoboticActive = False
def _robotic_right():
(x, y, z, r, j1, j2, j3, j4) = device.pose()
print(f'x:{x} y:{y} z:{z} j1:{j1} j2:{j2} j3:{j3} j4:{j4}')
if isRoboticActive == False:
isRoboticActive = True
device.move_to(96, 100, -12, -47, wait=False)
device.move_to(166, -211, -52, -47, wait=False)
device.suck(True)
time.sleep(1)
device.move_to(-125, -255, 33, -120, wait=False
device.suck(False)
time.sleep(0.5)
device.move_to(96, 100, -12, -47, wait=False)
isRoboticActive = False
def _robotic_home(direction):
(x, y, z, r, j1, j2, j3, j4) = device.pose()
print(f'x:{x} y:{y} z:{z} j1:{j1} j2:{j2} j3:{j3} j4:{j4}')
if isRoboticActive == False:
device.move_to(96, 100, -12, -47, wait=False)
device.suck(False)
def _move_robotic_arm(direction):
if direction == "left" and isRoboticActive == False:
thread_left.start()
elif direction == "right" and isRoboticActive == False:
thread_right.start()
# Clean up
device.close()Now we have both AI and Robotic arm running, we can use AI to trigger Robotic arm moves.
Below code is how we load the tensorflow model into memory
# Name of the directory containing the object detection module we're using
MODEL_NAME = 'inference_graph'
# Grab path to current working directory
CWD_PATH = os.getcwd()
# Path to frozen detection graph .pb file, which contains the model that is used
# for object detection.
PATH_TO_CKPT = os.path.join(CWD_PATH,MODEL_NAME,'frozen_inference_graph.pb')
# Path to label map file
PATH_TO_LABELS = os.path.join(CWD_PATH,'training','labelmap.pbtxt')
# Number of classes the object detector can identify
NUM_CLASSES = 6
## Load the label map.
# Label maps map indices to category names, so that when our convolution
# network predicts `5`, we know that this corresponds to `king`.
# Here we use internal utility functions, but anything that returns a
# dictionary mapping integers to appropriate string labels would be fine
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
# Load the Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
sess = tf.Session(graph=detection_graph)Next we will define input and output tensors for the object detection classifier
# Define input and output tensors (i.e. data) for the object detection classifier
# Input tensor is the image
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Output tensors are the detection boxes, scores, and classes
# Each box represents a part of the image where a particular object was detected
detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represents level of confidence for each of the objects.
# The score is shown on the result image, together with the class label.
detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
# Number of objects detected
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Initialize webcam feed
video = cv2.VideoCapture(0)
ret = video.set(3,720)
ret = video.set(4,576)We will establish the robotic arm through these 3 functions, and use isRoboticActive as flag, make sure to declare them as global inside the functions, the thread_left and thread_right will be running the robotic arm on a seperate thread so it does not bother our performance
port = list_ports.comports()[0].device
device = Dobot(port=port, verbose=True)
isRoboticActive=False
def _robotic_left():
(x, y, z, r, j1, j2, j3, j4) = device.pose()
print(f'x:{x} y:{y} z:{z} j1:{j1} j2:{j2} j3:{j3} j4:{j4}')
if isRoboticActive == False:
isRoboticActive = True
device.move_to(96, 100, -12, -47, wait=True)
device.move_to(166, -211, -52, -47, wait=True)
device.suck(enable=True)
time.sleep(1)
device.move_to(300, 7, 15, 5, wait=True)
device.suck(enable=False)
time.sleep(0.5)
device.move_to(96, 100, -12, -47, wait=True)
isRoboticActive = False
def _robotic_right():
(x, y, z, r, j1, j2, j3, j4) = device.pose()
print(f'x:{x} y:{y} z:{z} j1:{j1} j2:{j2} j3:{j3} j4:{j4}')
if isRoboticActive == False:
isRoboticActive = True
device.move_to(96, 100, -12, -47, wait=True)
device.move_to(166, -211, -52, -47, wait=True)
device.suck(enable=True)
time.sleep(1)
device.move_to(-125, -255, 33, -120, wait=True)
device.suck(enable=False)
time.sleep(0.5)
device.move_to(96, 100, -12, -47, wait=True)
isRoboticActive = False
def _move_robotic_arm(direction):
if direction == "left" and isRoboticActive == False:
thread_left.start()
elif direction == "right" and isRoboticActive == False:
thread_right.start()
thread_left = threading.Thread(target=_robotic_left, daemon=True)
thread_right = threading.Thread(target=_robotic_right, daemon=True)Here is main part of the program, we are inferencing the incoming images, display them on the camera, then decide which category it goes, in his sample if it's cardboard we will sort it to the left, and if it's plastic we will sort it to the right. Pressing q key also allows it to exit the program.
while(True):
# Acquire frame and expand frame dimensions to have shape: [1, None, None, 3]
# i.e. a single-column array, where each item in the column has the pixel RGB value
ret, frame = video.read()
frame_expanded = np.expand_dims(frame, axis=0)
# Perform the actual detection by running the model with the image as input
(boxes, scores, classes, num) = sess.run(
[detection_boxes, detection_scores, detection_classes, num_detections],
feed_dict={image_tensor: frame_expanded})
# Draw the results of the detection (aka 'visulaize the results')
vis_util.visualize_boxes_and_labels_on_image_array(
frame,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8,
min_score_thresh=0.60)
#getting the detected item
i = 0
for x in np.squeeze(scores):
if x > .95:
print(np.squeeze(classes).astype(np.int32)[i])
result = np.squeeze(classes).astype(np.int32)[i]
#1 is cardboard
if result == 1:
_move_robotic_arm("left")
#3 is plastic
elif result == 3:
_move_robotic_arm("right")
break
i = i + 1
# All the results have been drawn on the frame, so it's time to display it.
cv2.imshow('AI Robotic Sorting', frame)
# Press 'q' to quit
if cv2.waitKey(1) == ord('q'):
breakAnd finally, cleaning up, we close the robotic arm and camera.
# Clean up
device.close()
video.release()
cv2.destroyAllWindows()We've now connected AI to robotics, and after all the hardwork let's take a look at the demo.
_9cLIDPLB7J.png)

_9cLIDPLB7J.png){kind=link}
{kind=link}
Comments
Please log in or sign up to comment.