

Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
AI is a constantly evolving field and often changes in software occur too quickly for hardware accelerators to catch up. The increasing complexity of Deep Learning algorithms demands huge computational power and flexible hardware. FPGAs can provide a needed boost in performance whilst also adapting to the latest and compute-intensive AI techniques. With almost 3X AI performance and 2X performance-per-watt versus competing SOMs, Kria SOM proved to be an ideal development environment for ML edge applications. The Vision AI starter kit comes with the vision-centric carrier card and the pre-built accelerated applications which can be customized to our needs at different levels of abstraction (software application to hardware design).
Initial setupThe Kria K26 SOM can be configured with various Deep learning Processing Unit configurations based on performance requirements. The KV260 benchmarks are derived on DPU B4096 while the KV260 applications are designed on DPU B3136.
Vitis AI - 1.4.1
Docker image - 1.4
Refer to the detailed guide here on:
- how to flash the image
- set up the board
- run the smart camera application (optional but recommended).
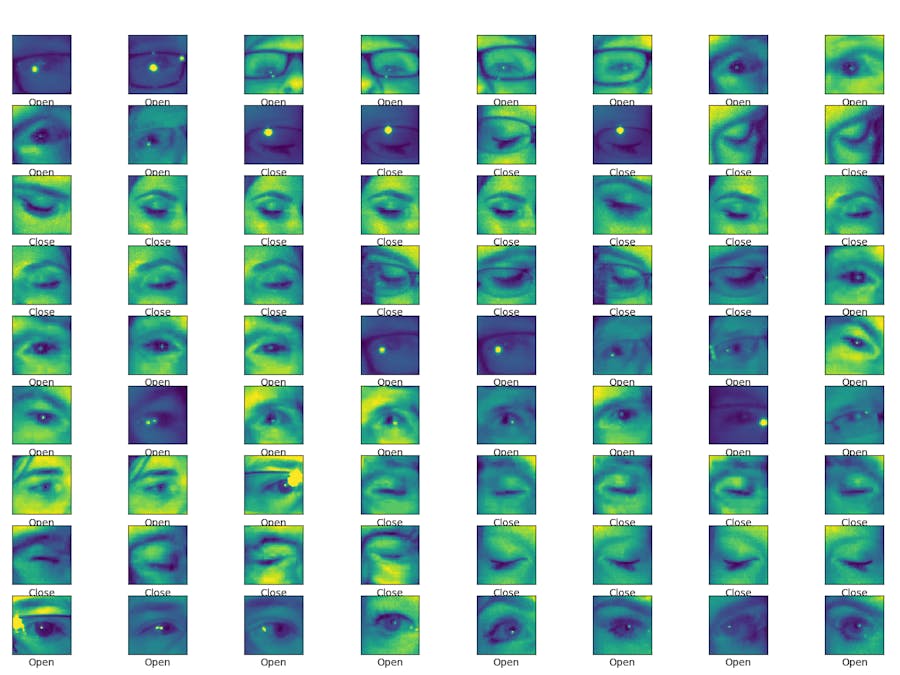
Detecting and monitoring the eye state of a person can be used in various applications from driver assistance systems (drowsiness detection) to health care (determining the fatigue levels of an individual).
The data set used for the training can be found here.
image size - 150x150 (The inputs to the CNN model need to be square for Vitis-AI. If the input isn't square it must be padded to make a square).
The binary classification model training flow can be found here. For this particular run, the validation accuracy was 0.912
Freeze graphCreate the frozen graph of the trained model (moving the model from the training phase to the inference phase through freezing - locking the weights). Pass the trained model and checkpoints to the freeze_graph() function.We can use the Vitis in-built freeze graph function as well, to create the frozen graph.
Use Tensorboard/Netron to visualize the frozen model, get the input/output nodes.
> pip install netron
> import netron
> netron.start('classification_model.h5')Verify that freezing the model has not caused any significant variation in accuracy using evaluate_graph() function.
The accuracy of the frozen model is 0.908
Vitis-AIClone the Vitis-AI repository in your project directory and check out the 1.4 version.
git clone https://github.com/Xilinx/Vitis-AI
cd Vitis-AI
git checkout v1.4The docker setup mounts the current directory as /workspace/ in the container. In the docker environment, you should have the binary_classification directory of this project in your workspace.
.<path_to_Vitis-AI>/docker_run.sh xilinx/vitis-ai-cpu:1.4.1.978Activate the TensorFlow environment
Vitis-AI /workspace > conda activate vitis-ai-tensorflowUse the setenv.sh script to create the required folders.
(vitis-ai-tensorflow) Vitis-AI /workspace $ ./setenv.shUse Vitis inspect command to estimate the input and output nodes.
(vitis-ai-tensorflow) Vitis-AI /workspace $ vai_q_tensorflow inspect --input_frozen_graph=frozen_graph.pbOne of the reasons to prefer Kria SOM over others is, it provides low precision support. Quantization essentially reduces the number of bits used for our tensors, weights and hence reduces memory usage. Going from 32-bit float to 8-bit fixed reduces our memory usage four times without much impact on the accuracy.
The Vitis-AI quantizer performs several forward passes on our training set and chooses an optimum scheme. The quantizer takes an input function (input_fn.py) to convert the calibration dataset to the input data of the frozen graph during quantize calibration (usually performs data pre-processing and augmentation). Run the quantize.sh script.
(vitis-ai-tensorflow) Vitis-AI /workspace $ ./quantize.shCheck the impact on accuracy. For this run, the accuracy of the quantized model was found to be 0.892
CompilationThe VAI_C compiler takes in the quantized model, optimizes the data and control flow, and splits the model into kernels to run on either DPU or CPU.
The --arch option supplies the specific configuration of the DPU Architecture. Create an arch.json file with the target DPU. (DPUCZX8G_ISA0_B4096_MAX_BG2 for B4096)
{
"target": "DPUCZX8G_ISA0_B3136_MAX_BG2"
}The –options parameter provides specific options for either edge or cloud flows of FPGAs or to dump debug files or if we want to run in debug or normal mode. In debug mode, the nodes of the DPU are run once at a time so we can explore debugging or performance profiles of each node. In normal mode, the DPU runs without interruption.
(vitis-ai-tensorflow) Vitis-AI /workspace $ ./compile.shOutputs the compiled.xmodel, md5sum.txt and meta.json files.
We can generate a png of the compiled model, to check the individual layers. layers as DPU subgraph - outlined in bluelayers deployed on the CPU - outlined in red
(vitis-ai-tensorflow) Vitis-AI /workspace $ xir png binary_classification.xmodel compiled_graph.pngCreate an application to test our model performance on the board. We use the vart runner class to handle the initialization and the communication with the DPU API.
- Creating the runner: dpu = vart.Runner.create_runner()
- Get input, output tensors: dpu.get_input_tensors(), dpu.get_output_tensors()
- Execute the runner: job_id = dpu.execute_async(inputData, outputData)
- Wait for the runner to finish: dpu.wait(job_id)
Set up the threads to run the DPU. (Vary between different threads to compare the performance and find the optimal results)
Copy the test images, compiled model and the app to the board.
The B4096 image is the DPU configured image. Thereby we can directly run the app after copying the required files. In the B3136 image, we can load the DPU by loading one of the corresponding pre-built applications.
Install Vitis AI package group.
sudo dnf install packagegroup-petalinux-vitisai
sudo dnf install packagegroup-petalinux-opencvLoad the smartcam app to load the associated DPU.
sudo xmutil unloadapp
sudo xmutil loadapp kv260-smartcamUse xdputil query or show_dpu command to verify the DPU version.
The vart.conf file needs to be updated to point to the dpu.xclbin of the loaded application
echo "firmware: /lib/firmware/xilinx/kv260-smartcam/kv260-smartcam.xclbin" | sudo tee /etc/vart.confRun the app_mt.py with the compiled model. (Use & at the end of the command to run it in the background).
python3 app.py -m binary_classification.xmodel -t 2 &Check the performance of the board.
xmutil platformstats -pModel accuracy in different stages:
| Post-training | Frozen Graph | Quantized Model | Hardware Model |
| (Float) | (Float) | (INT8) | (INT8) |
| ------------- | ------------ | --------------- | -------------- |
| 91.2 | 90.8 | 89.2 | 88.4 |Comparison between different DPU configurations:
| DPU | Latency optimized | Throughput optimized |
| | ----------------- | -------------------- |
| | FPS | Power(W) | FPS | Power(W) |
| ----- | ------ | -------- | --------- | -------- |
| B3136 | 379.50 | 7.03 | 418.55 | 7.37 |
| B4096 | 531.43 | 5.77 | 608.85 | 5.92 |Latency optimized - executing with 1 threadReferences
Throughput optimized - executing with 2 threads


{kind=link}
Comments
Please log in or sign up to comment.