

Pneumonia is an infectious disease of the lungs that mainly affects the pulmonary vasculature and causes the oxygen not to pass into the blood. Symptoms usually include a combination of cough, chest pain, high fever and difficulty breathing. Pneumonia is most often caused by a bacterial or viral infection and sometimes by autoimmune diseases. Diagnosis of inflammation is based on performing an X-ray of the chest and blood tests.
During this period of the corona virus (Covid-19) whose patients are in a higher risk group to develop pneumonia the importance of accuracy and decoding time of the test increases.
In light of this period there is a high increase in patients and therefore a quick and accurate solution is needed to decipher the X-rays. This project presents a solution for deciphering photographs using Deep Learning technology. This solution brings results almost in real time and with an accuracy of over 90% and thus will be used to reduce the load of radiologists who decode a lot of photographs of patients.
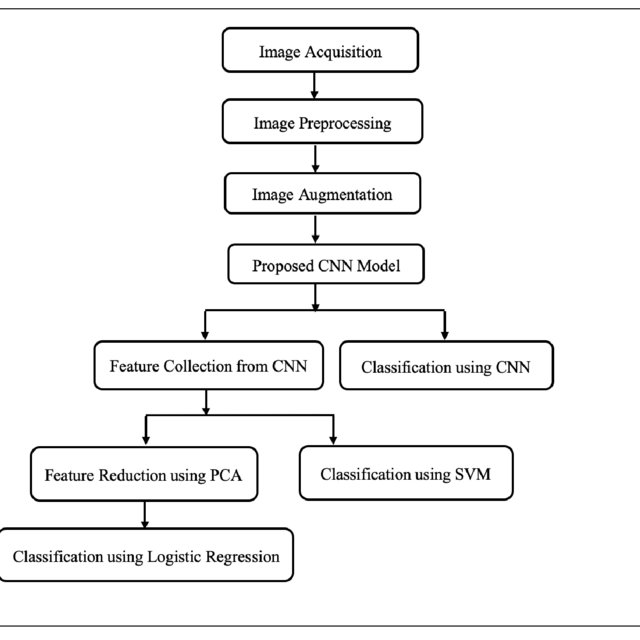
The mechanism will "learn" from a pre-existing X-ray database of healthy and sick people (the training set), using the CNN (Convolutional Neural Network) algorithm we "taught". He will know how to classify new x-rays that he has never encountered (test set) and determine if there is a presence of pneumonia in the photo.
# Tasks that this article deal with:1) You need to design a deep network to solve the problem: the entry of the deep network is a picture and the starting point is the probability
That the picture represents a positive case of pneumonia. The probability is between 0 and 1 where 1 represents a certain case of
Pneumonia.
Performance will be measured on the test image set, which is completely separated from the training set. Good performance will be considered a chance
Error lower than 10% (i.e. Accuracy higher than 90%)
2) 1. For the network you selected, draw the PRECISION-RECALL performance graph, with each point in the graph calculated for
Different threshold level) in relation to the probability produced by the network (to decide on a positive example) i.e. with pneumonia (.
The threshold will be in the range 1.0 to 9.0 in jumps of 05.0. Also mark on the graph the SCORE-F points that will be calculated from each pair
PRECISION-RECALL values.
2. For which threshold was the highest SCORE-F value obtained?
3) 1. For the network you selected, try to improve Accuracy performance by making the following changes:
A. Addition of one layer according to your decision - the choice must be justified.
B. Addition of two layers according to your decision - the choice must be justified.
C. Examine five changes in the depth of existing layers and / or the number of convolution kernels (no additional layers)
- The choice must be justified.
2. Check the network performance with the following training algorithms Check the effect of the EPOCHS and LEARNING number
RATE per algorithm :
A. SGD algorithm
B. SGD algorithm with MOMENTUM and MOMENTUM NESTEROV.
C. ADAM Algorithm
D. RMSPROP algorithm
3. Examine the effect of the following changes:
E. DROPOUT - check the effect of changing the probability (this is the parameter of DROPOUT) if there is a layer.DROPOUT
In this project, a database from the Kaggle website was used which contains 5, 863 real X-rays of pneumonia patients and healthy people.
The images in the database are divided into three folders:
Train - The training set is a database of examples (tagged images) used during the learning process to adjust parameters, including weights.
Validation - The control set, is a separate set used for control during the training process and allows to improve the classification level of the images by improving the hyperparameters that are not usually improved during the training process (such as Learning Rate). The set contains 8 images without pneumonia, And 8 with pneumonia.
Test - The test set, we were a set of untagged images that is used to actually test the system after the training process, and allows to characterize the quality of the network.
Principle of operation in brief: First, we train the system (Train). At this point the system learns how to identify images, by various parameters and weights them. We then move on to the test phase. At this point, we check image after image without tagging. Finally, we compare the control set (Validation) which actually criticizes the level of success of learning in the parameters learned. From here we come to a certain accuracy (Accuracy), in percent.
# Network training process:From the accuracy graph it can be seen that in the 11th iteration we got a certain peak followed by a significant decrease in accuracy. It is hypothesized that this decrease is due to a change in the learning rate as a result of using an algorithm that changes the learning rate.
From the graph of losses it can be seen that the losses change, decrease to a local minimum and then increase which activates the mechanism of reducing the pace of learning.
The layers used:
● Conv2D - a two-dimensional convolution layer that produces a nucleus that is applied to the image at the entrance to the system to identify the image properties (edges, magnification, reduction and more). First we will define the N number of layers of the filters (we chose 32), then the kernel size Kernel Size, later we will need to select the size of the Stride window slider. We will set the image size (the image is two-dimensional so we will set 200X200, 1). We will then use a Relu activation layer (because it trains the network without significant penalty in the overall accuracy of the system) and finally we will use a Sigmoid activation layer that will give us a value of 0 or 1.
● Relu - is an Activation Function that resets the negative values and leaves the positive values as they are, the most common function due to its runtime efficiency and resource cost.
● MaxPool2D - a layer that aims to reduce calculation costs and runtime by reducing the number of parameters that need to be studied.This layer is done after convolution and actually reduces the Feature Map. The layer will take the maximum value from each Pool Size, we will make a 2X2 kernel with Stride 2 every time we use this operation.
● Flatten - A major step in CNN, we will use it when we want the output to be flat.The intention is to turn a two-dimensional matrix into vector values that we can insert into the Classifier layer, this layer is located before the classification layer.
● Dense - a layer in which each neuron in the layer receives input from all the neurons of the previous layer. The dense layer was found to be the most common layer in models. Behind the scenes the layer performs a product multiplication by a matrix, with the matrix values being verifiable weights.
The origin of the layer is a vector, which means that the role of the layer is to actually change the vector dimension.
● Batch Size - Sets the size of the sample group used for training, for example the number of images in the control set.
● Epochs - the number of times we train with a different sample group (divides the set into groups in the amount of Epochs and compares to different sample groups).
● Loss Function - A loss function, is a function that maps values of one or more variables to an actual number that represents the "cost" of an event. This function is used to perform optimization, while want to keep its output as small as possible
● Train / Val Accuracy - The accuracy of a learning system is determined by the proximity of the measurements of a particular quantity, to the true actual value of that quantity.
Q1 Results:
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
Extracting all the files now...
Done!
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:40: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
Model: "sequential_12"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_62 (Conv2D) (None, 200, 200, 32) 320
_________________________________________________________________
max_pooling2d_62 (MaxPooling (None, 100, 100, 32) 0
_________________________________________________________________
conv2d_63 (Conv2D) (None, 100, 100, 32) 9248
_________________________________________________________________
max_pooling2d_63 (MaxPooling (None, 50, 50, 32) 0
_________________________________________________________________
conv2d_64 (Conv2D) (None, 50, 50, 32) 9248
_________________________________________________________________
max_pooling2d_64 (MaxPooling (None, 25, 25, 32) 0
_________________________________________________________________
conv2d_65 (Conv2D) (None, 25, 25, 32) 9248
_________________________________________________________________
max_pooling2d_65 (MaxPooling (None, 13, 13, 32) 0
_________________________________________________________________
flatten_12 (Flatten) (None, 5408) 0
_________________________________________________________________
dense_24 (Dense) (None, 128) 692352
_________________________________________________________________
dense_25 (Dense) (None, 1) 129
=================================================================
Total params: 720, 545
Trainable params: 720, 545
Non-trainable params: 0
Loss of the model is - 0.29045939445495605
20/20 [==============================] - 1s 30ms/step - loss: 0.2905 - accuracy: 0.9038 - recall: 0.8060 - precision: 0.8141
Accuracy of the model is - 90.38461446762085 %
# Recall-Precision Graph (Q2)Description of the performance of the basic model by the Recall-Precision graph where each point in the graph is calculated for a different threshold level in relation to the probability the network produces for deciding on a personal example
From the table it can be seen that the highest harmonic mean (F1 -Score) is 0.8556825 and it occurs for a probability threshold level of 0.4 i.e. if we define any sample whose probability is positive (positive for pneumonia) will be above 0.4 we will get the best performance.
# Q3I added one layer of different thickness at a time and with a fixed kernel ((3, 3) for Conf2D and (2, 2) for Max pool)
Option 1: depth of convolution = 32
Layer (type) Output Shape Param #
=================================================================
conv2d_66 (Conv2D) (None, 200, 200, 32) 320
_________________________________________________________________
max_pooling2d_66 (MaxPooling (None, 100, 100, 32) 0
_________________________________________________________________
conv2d_67 (Conv2D) (None, 100, 100, 32) 9248
_________________________________________________________________
max_pooling2d_67 (MaxPooling (None, 50, 50, 32) 0
_________________________________________________________________
conv2d_68 (Conv2D) (None, 50, 50, 32) 9248
_________________________________________________________________
max_pooling2d_68 (MaxPooling (None, 25, 25, 32) 0
_________________________________________________________________
conv2d_69 (Conv2D) (None, 25, 25, 32) 9248
_________________________________________________________________
max_pooling2d_69 (MaxPooling (None, 13, 13, 32) 0
_________________________________________________________________
flatten_13 (Flatten) (None, 5408) 0
_________________________________________________________________
dense_26 (Dense) (None, 128) 692352
_________________________________________________________________
dense_27 (Dense) (None, 1) 129
=================================================================
Total params: 720, 545
Trainable params: 720, 545
Non-trainable params: 0
Loss of the model is - 0.27853989601135254
20/20 [==============================] - 1s 30ms/step - loss: 0.2785 - accuracy: 0.9087 - recall: 0.8200 - precision: 0.8245Accuracy of the model is - 90.86538553237915 %
From the accuracy graph it can be seen that starting from the 11th iteration there is a regularity and in the 15th iteration there is a fall.
From the loss graph it can be seen that there are fluctuations that activate the learning rate reduction mechanism. In any case the accuracy of the system remains around 90 percent.
Option 2: addition of 64
20/20 [==============================] - 1s 23ms/step - loss: 0.2692 - accuracy: 0.8798 - recall: 0.8300 - precision: 0.8336
Loss of the model is - 0.2692185044288635
20/20 [==============================] - 0s 23ms/step - loss: 0.2692 - accuracy: 0.8798 - recall: 0.8295 - precision: 0.8340
Accuracy of the model is - 87.9807710647583 %
From the accuracy graph it can be seen that starting from the 11th iteration there is a regularity and in the 10th iteration there is a fall.
From the loss graph it can be seen that there are fluctuations that activate the learning rate reduction mechanism.
In any case the accuracy of the system remains around 90 percent.
Option 3: addition of 128
20/20 [==============================] - 3s 101ms/step - loss: 0.4191 - accuracy: 0.8349 - recall: 0.8096 - precision: 0.8148
Loss of the model is - 0.41905343532562256
20/20 [==============================] - 2s 103ms/step - loss: 0.4191 - accuracy: 0.8349 - recall: 0.8078 - precision: 0.8155
Accuracy of the model is - 83.49359035491943
From the accuracy graph it can be seen that starting from the 10th iteration there is a regularity and in the 12th iteration there is a fall.
From the loss graph it can be seen that there are fluctuations that activate the learning rate reduction mechanism. In any case the accuracy of the system remains around 90 percent.
A final conclusion that adding the convolution depth of 32 resulted in the best accuracy improvement of 90.8% so we will use this method.
3.1.2) Addition of 2 layers
Option 1: addition of two 32 layers
20/20 [==============================] - 1s 30ms/step - loss: 0.2069 - accuracy: 0.9199 - recall: 0.7988 - precision: 0.8079
Loss of the model is - 0.2068600356578827
20/20 [==============================] - 1s 27ms/step - loss: 0.2069 - accuracy: 0.9199 - recall: 0.7991 - precision: 0.8090
Accuracy of the model is - 91.98718070983887 %
From the accuracy graph it can be seen that starting from the 11th iteration there is a regularity and in the 12th iteration there is a fall.
From the loss graph it can be seen that there are fluctuations that activate the learning rate reduction mechanism. In any case the accuracy of the system remains around 90 percent.
Option 2: addition of two 64 layers
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 200, 200, 32) 320
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 100, 100, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 100, 100, 32) 9248
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 50, 50, 32) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 50, 50, 32) 9248
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 25, 25, 32) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 25, 25, 32) 9248
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_8 (MaxPooling2 (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 7, 7, 64) 36928
_________________________________________________________________
max_pooling2d_9 (MaxPooling2 (None, 4, 4, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 1024) 0
_________________________________________________________________
dense_2 (Dense) (None, 128) 131200
_________________________________________________________________
dense_3 (Dense) (None, 1) 129
=================================================================
Total params: 214, 817
Trainable params: 214, 817
Non-trainable params: 0
Loss of the model is - 0.2688480317592621
20/20 [==============================] - 0s 15ms/step - loss: 0.2688 - accuracy: 0.9006 - recall: 0.8014 - precision: 0.8103
Accuracy of the model is - 90.06410241127014 %
From the accuracy graph it can be seen that starting from the 11th iteration there is a regularity and in the 15th iteration there is a fall.
From the loss graph it can be seen that there are fluctuations that activate the learning rate reduction mechanism. In any case the accuracy of the system remains around 90 percent.
Option 3: one layer of 32 and one of 64
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 200, 200, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 100, 100, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 100, 100, 32) 9248
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 50, 50, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 50, 50, 32) 9248
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 25, 25, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 25, 25, 32) 9248
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 13, 13, 32) 9248
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 7, 7, 64) 18496
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 4, 4, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 1024) 0
_________________________________________________________________
dense (Dense) (None, 128) 131200
_________________________________________________________________
dense_1 (Dense) (None, 1) 129
=================================================================
Total params: 187, 137
Trainable params: 187, 137
Non-trainable params: 0
Loss of the model is - 0.36978185176849365
20/20 [==============================] - 1s 28ms/step - loss: 0.3698 - accuracy: 0.8638 - recall: 0.8042 - precision: 0.8135
Accuracy of the model is - 86.37820482254028
From the accuracy graph it can be seen that starting from the 11th iteration there is a regularity and in the 14th iteration there is a fall.
From the loss graph it can be seen that there are fluctuations that activate the learning rate reduction mechanism. In any case the accuracy of the system remains around 90 percent.
Option 4: one layer of 64 and 128
Layer (type) Output Shape Param #
=================================================================
conv2d_10 (Conv2D) (None, 200, 200, 32) 320
_________________________________________________________________
max_pooling2d_10 (MaxPooling (None, 100, 100, 32) 0
_________________________________________________________________
conv2d_11 (Conv2D) (None, 100, 100, 32) 9248
_________________________________________________________________
max_pooling2d_11 (MaxPooling (None, 50, 50, 32) 0
_________________________________________________________________
conv2d_12 (Conv2D) (None, 50, 50, 32) 9248
_________________________________________________________________
max_pooling2d_12 (MaxPooling (None, 25, 25, 32) 0
_________________________________________________________________
conv2d_13 (Conv2D) (None, 25, 25, 32) 9248
_________________________________________________________________
max_pooling2d_13 (MaxPooling (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_14 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_14 (MaxPooling (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_15 (Conv2D) (None, 7, 7, 128) 73856
_________________________________________________________________
max_pooling2d_15 (MaxPooling (None, 4, 4, 128) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 2048) 0
_________________________________________________________________
dense_4 (Dense) (None, 128) 262272
_________________________________________________________________
dense_5 (Dense) (None, 1) 129
=================================================================
Total params: 382, 817
Trainable params: 382, 817
Non-trainable params: 0
Loss of the model is - 0.3012300729751587
20/20 [==============================] - 0s 14ms/step - loss: 0.3012 - accuracy: 0.8910 - recall: 0.8065 - precision: 0.8157
Accuracy of the model is - 89.10256624221802 %
From the accuracy graph it can be seen that starting from the 11th iteration there is a regularity and in the 14th iteration there is a fall.
From the loss graph it can be seen that there are fluctuations that activate the learning rate reduction mechanism. In any case the accuracy of the system remains around 90 percent.
3.1.3): Five changes in depth of the layers / number of kernels of the convolution:
Option 1: reducing the kernels of the convolution to (2X2)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_10 (Conv2D) (None, 200, 200, 32) 320
_________________________________________________________________
max_pooling2d_10 (MaxPooling (None, 100, 100, 32) 0
_________________________________________________________________
conv2d_11 (Conv2D) (None, 100, 100, 32) 9248
_________________________________________________________________
max_pooling2d_11 (MaxPooling (None, 50, 50, 32) 0
_________________________________________________________________
conv2d_12 (Conv2D) (None, 50, 50, 32) 9248
_________________________________________________________________
max_pooling2d_12 (MaxPooling (None, 25, 25, 32) 0
_________________________________________________________________
conv2d_13 (Conv2D) (None, 25, 25, 32) 9248
_________________________________________________________________
max_pooling2d_13 (MaxPooling (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_14 (Conv2D) (None, 13, 13, 32) 4128
_________________________________________________________________
max_pooling2d_14 (MaxPooling (None, 7, 7, 32) 0
_________________________________________________________________
conv2d_15 (Conv2D) (None, 7, 7, 32) 4128
_________________________________________________________________
max_pooling2d_15 (MaxPooling (None, 4, 4, 32) 0
_________________________________________________________________
conv2d_16 (Conv2D) (None, 4, 4, 32) 4128
_________________________________________________________________
max_pooling2d_16 (MaxPooling (None, 2, 2, 32) 0
_________________________________________________________________
conv2d_17 (Conv2D) (None, 2, 2, 32) 4128
_________________________________________________________________
max_pooling2d_17 (MaxPooling (None, 1, 1, 32) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 32) 0
_________________________________________________________________
dense_2 (Dense) (None, 128) 4224
_________________________________________________________________
dense_3 (Dense) (None, 1) 129
=================================================================
Total params: 48, 929
Trainable params: 48, 929
Non-trainable params: 0
Loss of the model is - 0.2754925787448883
20/20 [==============================] - 1s 27ms/step - loss: 0.2755 - accuracy: 0.8910 - recall: 0.7731 - precision: 0.7936
Accuracy of the model is - 89.10256624221802 %
Option 2: reducing the kernels of the convolution to (4X4)
Loss of the model is - 0.25276684761047363
20/20 [==============================] - 1s 30ms/step - loss: 0.2528 - accuracy: 0.9119 - recall: 0.7889 - precision: 0.8016
Accuracy of the model is - 91.18589758872986
Option 3: Reducing dense layer to 32
Loss of the model is - 0.28824353218078613
20/20 [==============================] - 1s 29ms/step - loss: 0.2882 - accuracy: 0.9103 - recall: 0.8130 - precision: 0.8261
Accuracy of the model is - 91.02563858032227 %
Option 4: Layers depth are doubled
Loss of the model is - 0.284391850233078
20/20 [==============================] - 1s 28ms/step - loss: 0.2844 - accuracy: 0.9151 - recall: 0.7903 - precision: 0.8094
Accuracy of the model is - 91.50640964508057 %
Option 5: Increasing kernels on each layer
Loss of the model is - 0.4851168096065521
20/20 [==============================] - 6s 309ms/step - loss: 0.4851 - accuracy: 0.8349 - recall: 0.7777 - precision: 0.7963
Accuracy of the model is - 83.49359035491943 %
It can be seen from this section that option 4 (option 4) resulted in the best performance, so doubling the amount of layers is recommended for optimizing the algorithm.
3.2.1) SGD
Option 1:learning rate=0.05, Epochs num=8
20/20 [==============================] - 1s 29ms/step - loss: 0.4024 - accuracy: 0.8574 - recall: 0.5789 - precision: 0.7165
Loss of the model is - 0.4023500978946686
20/20 [==============================] - 1s 27ms/step - loss: 0.4024 - accuracy: 0.8574 - recall: 0.5814 - precision: 0.7194
Accuracy of the model is - 85.73718070983887 %
Option 2:SGD Learning rate=0.001 Epochs=16
Loss of the model is - 0.7018033266067505
20/20 [==============================] - 1s 29ms/step - loss: 0.7018 - accuracy: 0.6250 - recall: 0.2579 - precision: 0.1436
Accuracy of the model is - 62.5 %
Option 3: SGD Learning rate=0.0001 Epochs =32
20/20 [==============================] - 1s 29ms/step - loss: 0.6805 - accuracy: 0.6250 - recall: 0.5010 - precision: 0.1450
Loss of the model is - 0.6805050373077393
20/20 [==============================] - 1s 27ms/step - loss: 0.6805 - accuracy: 0.6250 - recall: 0.5009 - precision: 0.1452
Accuracy of the model is - 62.5
It can be seen that this optimizer (SGD) produces results that do not provide the 90% accuracy threshold, so we will not use it.
3.2.3)SGD+Momentum=0.4 +Nesterov=True:
Option 1: learning rate=0.05 epochs=8
Loss of the model is - 0.4116775393486023
20/20 [==============================] – 1s 28ms/step – loss: 0.4117 – accuracy: 0.8766 – recall: 0.6306 – precision: 0.7383
Accuracy of the model is - 87.66025900840759 %
Option 2: learning rate=0.0001 epochs=16
Loss of the model is - 0.6696860194206238
20/20 [==============================] – 1s 28ms/step – loss: 0.6697 – accuracy: 0.6250 – recall: 0.4505 – precision: 0.1474
Accuracy of the model is - 62.5 %
3.2.3)SGD+Momentum=0.8 +Nesterov=True
Option1: learning rate = 0.05 epochs=8
Loss of the model is - 0.4051578938961029
20/20 [==============================] – 1s 28ms/step – loss: 0.4052 – accuracy: 0.7965 – recall: 0.5356 – precision: 0.6973
Accuracy of the model is - 79.64743375778198 %
Option 2: learning rate = 0.05 epochs= 16
Loss of the model is - 0.696070671081543
20/20 [==============================] – 1s 31ms/step – loss: 0.6961 – accuracy: 0.6250 – recall: 0.2680 – precision: 0.1466
Accuracy of the model is - 62.5
It can be seen that even using this algorithm (SGD + Momentum) and using Nesterov we were unable to reach a 90% accuracy threshold therefore, we will not use this optimizer.
3.2.4) Adam:
Option 1: learning rate=0.05 epochs=16
Loss of the model is - 0.6952387690544128
20/20 [==============================] - 1s 29ms/step - loss: 0.6952 - accuracy: 0.6250 - recall: 0.2422 - precision: 0.1590
Accuracy of the model is - 62.5 %
Option 2: learning rate=0.001 epochs=8:
Loss of the model is - 0.3520313501358032
20/20 [==============================] – 1s 28ms/step – loss: 0.3520 – accuracy: 0.9087 – recall: 0.7662 – precision: 0.7860
Accuracy of the model is - 90.86538553237915 %
Option 3: learning rate=0.0001 epochs=32
Loss of the model is - 0.2995906174182892
20/20 [==============================] – 1s 28ms/step – loss: 0.2996 – accuracy: 0.9103 – recall: 0.7975 – precision: 0.8006
Accuracy of the model is - 91.02563858032227 %
In this optimizer (Adam) we got the best accuracy, it stands at 91.02%. Therefore, we will conclude that our premise is correct that Optimizer Adam is the best.
3.2.5) RMSProp
Loss of the model is - 0.6955061554908752
20/20 [==============================] - 1s 29ms/step - loss: 0.6955 - accuracy: 0.6250 - recall: 0.2272 - precision: 0.2684
Accuracy of the model is - 62.5 %
Option2: learning rate=0.0001 epochs =16
Loss of the model is - 0.5227556228637695
20/20 [==============================] - 1s 29ms/step - loss: 0.5228 - accuracy: 0.8317 - recall: 0.6938 - precision: 0.7694
Accuracy of the model is - 83.17307829856873 %
Option 3: learning rate=0.001 epochs=16
Loss of the model is - 0.3556261360645294
20/20 [==============================] - 1s 31ms/step - loss: 0.3556 - accuracy: 0.9054 - recall: 0.8099 - precision: 0.8389
Accuracy of the model is - 90.54487347602844 %
Option 4: learning rate=0.001 epochs=8
Loss of the model is - 0.3095395565032959
20/20 [==============================] - 1s 27ms/step - loss: 0.3095 - accuracy: 0.8910 - recall: 0.7277 - precision: 0.7822
Accuracy of the model is - 89.10256624221802 %
Option 5: learning rate=0.001 epochs=32
Loss of the model is - 0.3874219059944153
20/20 [==============================] - 1s 31ms/step - loss: 0.3874 - accuracy: 0.9006 - recall: 0.8508 - precision: 0.8710
Accuracy of the model is - 90.06410241127014 %
This optimizer (RMSProp) did not meet the 90% accuracy threshold according to the parameters tested.
# (3.3.5) Dropout:
● Dropout - is a mechanism by which some of the neurons are filtered (reset) at random. This makes the model less sensitive. We use this method to prevent Over Fitting. The idea is that if we use an almost complete network we will still cover most of the parameters and therefore the neurons develop a common dependency, which can affect the efficiency of each neuron individually.
Option 1: dropout=0.1
20/20 [==============================] - 1s 34ms/step - loss: 0.2978 - accuracy: 0.9038 - recall: 0.7699 - precision: 0.8206
Loss of the model is - 0.2978477478027344
20/20 [==============================] - 1s 30ms/step - loss: 0.2978 - accuracy: 0.9038 - recall: 0.7700 - precision: 0.8215
Accuracy of the model is - 90.38461446762085 %
Option 2: dropout=0.2
20/20 [==============================] - 1s 32ms/step - loss: 0.3578 - accuracy: 0.9022 - recall: 0.7867 - precision: 0.8312
Loss of the model is - 0.35782647132873535
20/20 [==============================] - 1s 30ms/step - loss: 0.3578 - accuracy: 0.9022 - recall: 0.7860 - precision: 0.8320
Accuracy of the model is - 90.22436141967773 %
Option 3: Dropout =0.3
20/20 [==============================] - 1s 29ms/step - loss: 0.3332 - accuracy: 0.8942 - recall: 0.7785 - precision: 0.8306
Loss of the model is - 0.33318087458610535
20/20 [==============================] - 1s 28ms/step - loss: 0.3332 - accuracy: 0.8942 - recall: 0.7776 - precision: 0.8315
Accuracy of the model is - 89.42307829856873 %
Option 4: Dropout =0.4
20/20 [==============================] - 1s 31ms/step - loss: 0.3126 - accuracy: 0.9135 - recall: 0.7414 - precision: 0.8127
Loss of the model is - 0.31257596611976624
20/20 [==============================] - 1s 28ms/step - loss: 0.3126 - accuracy: 0.9135 - recall: 0.7416 - precision: 0.8137
Accuracy of the model is - 91.34615659713745 %
conclusion:
It can be seen that adding a Dropout that weighs 0.4 causes for the best (accurate) performance.





{kind=link}
Comments