


Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 2 | ||||
| × | 2 | ||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
| ||||||
| ||||||
 |
| |||||
Hand tools and fabrication machines | ||||||
 |
| |||||
 |
| |||||
 |
| |||||
The general idea for this project came from my Master Thesis, in which I've created an autonomous cart which was able to move in dynamic environments. The "dynamic" part means environments populated by humans that were not trained to behave safely in robot's persence. For this purpose I've created simple neural network that took scans from 2D LIDAR sensor and returned scans that contained detection of human legs. The network was based on this paper. The resulting scans were then postprocessed and passed through Kalman Filter to give somewhat accurate estimations of people's position and velocity. While it was working okay during my tests, in reality, due to scans being only two dimensional, it would perform rather poorly in real life scenarios as the 2D scan covers only people's legs at some specific height, which means it would have problems with classifying children and could be easily fooled by "leg like" objects such as two poles being close enough.
This left me a bit unsatisfied and with urge to make it better. This project is a second iteration of my human estimator and is based on similar concept to the first one, but uses DIY 3D LIDAR as a scan source. Due to this, the project is split into two parts: the first one describes the process of building the LIDAR and it's control, while the second part describes human detection pipeline.
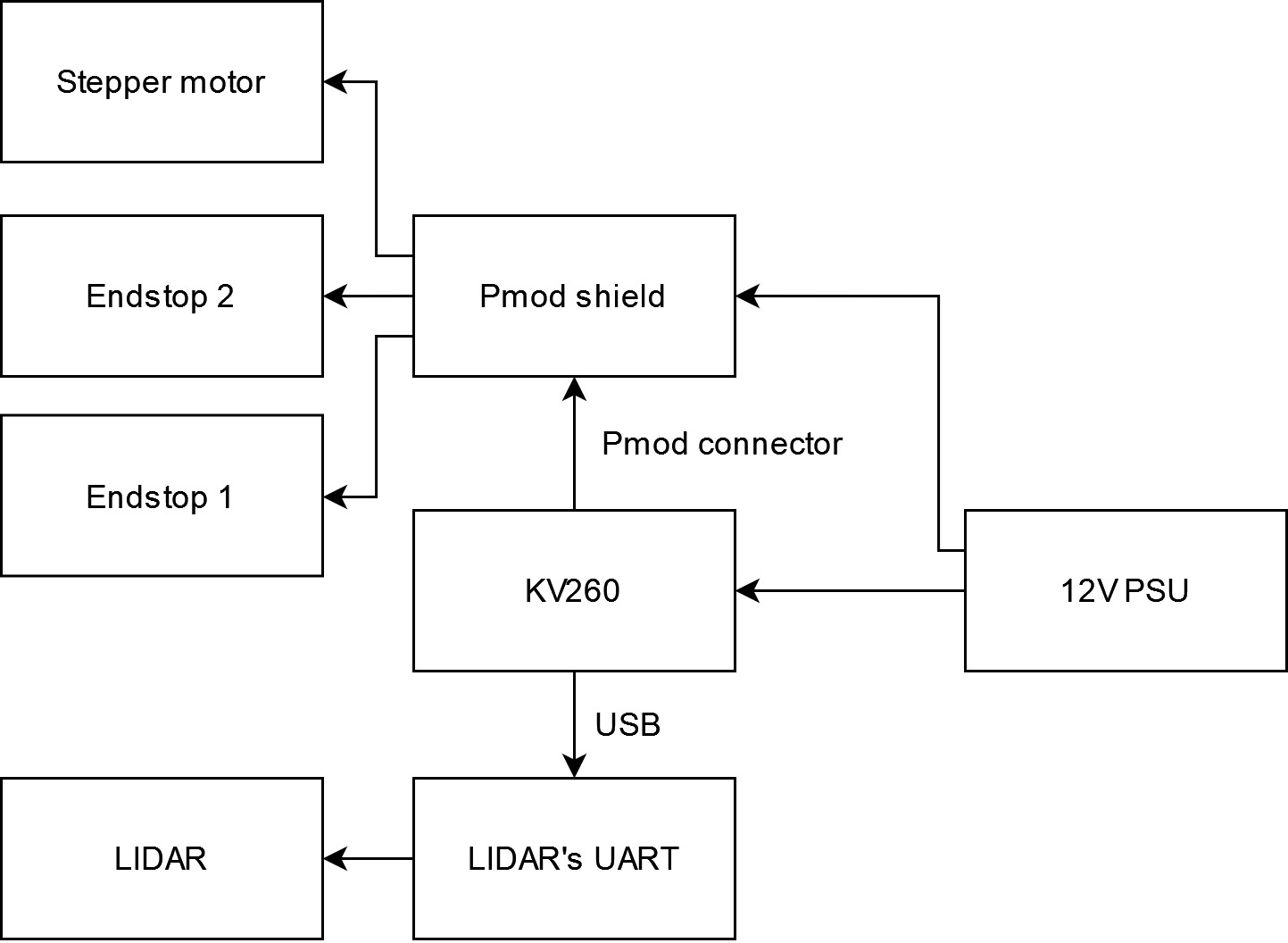
HardwareTo create 3D LIDAR there are two main things required. The first one is the laser scanner, and the second is the source of three dimensional motion. For the scaner I've reused aformentioned 2D LIDAR, which also removes the need for two dimensions of motion. This left me with need for only one dimensional source of motion, cool!
It's not a secret that for scanning, LIDAR requires knowledge about it's position to get satisfying scan precision. This means position controlled motor, and while there is a lot of options to choose from, to not overengineer this with control loops, I've decided to use the simpliest solution, a NEMA17 stepper motor, which is easy to control and allows for fine and precise movement.
Thanks to built-in into K26 SoC FPGA, there is not much to add in terms of electronics. The only things I've added were required to control the LIDAR itself, to control stepper's coils, and to home the stepper controlled axis. The motor is controlled by A4988 stepper motor driver, the LIDAR communicates with KV260 by serial to USB adapter which was included with the lidar itself and the homing is performed with help of two endstop switch boards from Creality 3D printer.
To avoid breadboard mess, I've decided to create simple Pmod shield with connectors for stepper driver, switches, the motor and additional I2C connector, which finally was left unused.
Looking back at the project I think I could've replaced the serial to USB board with simple AXI Serial attached to Pmod connector in the place of unused I2C, but anyway.
To make the third axis I've created simple 3D printable frame, which contains rotary cradle for LIDAR sensor and mount points for stepper motor and homing switches. There is also enough space under the cradle to lock KV260 in place.
The frame was printed in PLA and assembled together using M3 screws and nuts.
The third axis allows rotary movement of 90 degrees, and as seen below, it translates to field of view of LIDAR in this axis to 180 degrees, which means that our LIDAR can cover now two quarters of a sphere (roughly, due to misalignment of the laser to center of the cradle), that's a nice upgrade from simple 2D scanner!.
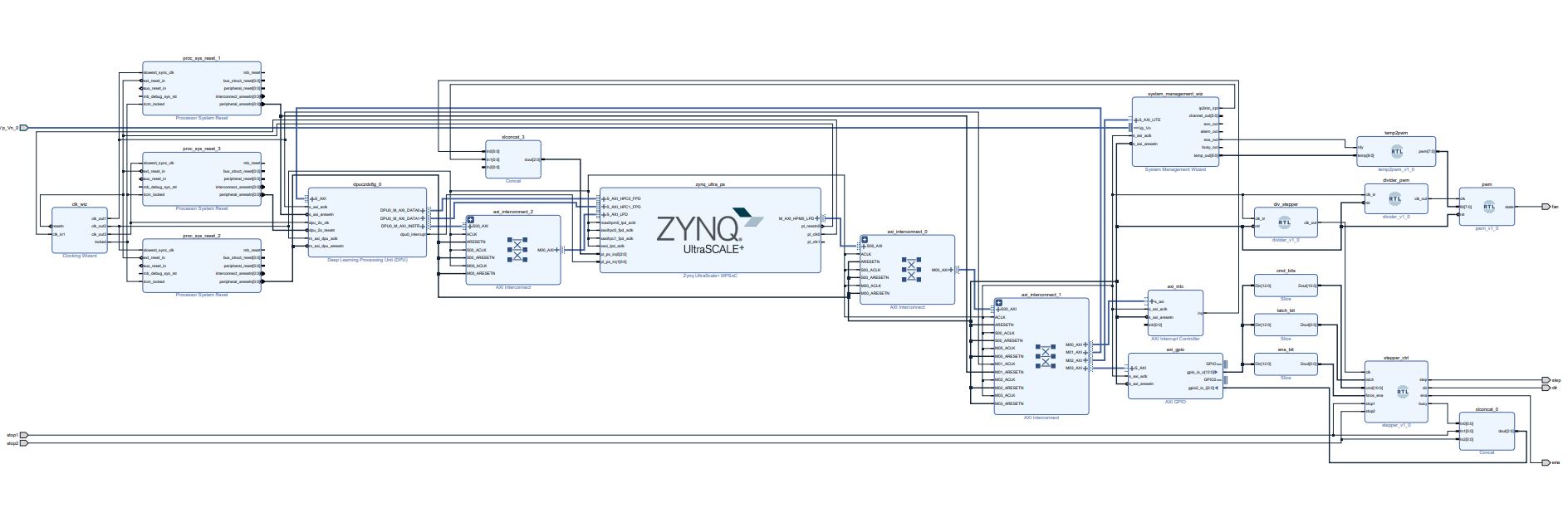
The Vivado part of the project consists of four main building blocks. The first one is the typical stuff such as Zynq UltraScale MPSoC+, interrupt handler, clocking, system reset and AXI interconnect for additional HLS kernels. The second part is just temperature controlled cooling fan (love the silence!). The third part is additional custom circuity to control stepper motor directly from FPGA. And the last but not least is DPU core that will be used as inference engine for the detector.
Stepper controller is one block of Verilog code which contains simple state machine to home and move the motor through Pmod connector using A988's interface (ena/step/dir) and communicates with the A53 CPU through AXI GPIO interface. I'm aware that I could just write my own AXI interface, but I don't think that I'm on that level yet. Also I think it would take more lines of code to write just the interface than the state machine itself.
As you can see above, the controller has 6 inputs. Stepping clock is a constant frequency 50Hz clock that is responsible for step signal generation (there's no acceleration or velocity control as it's not necessary in this project). Force enable forces ena output to turn on the motor even if the controller is not busy. Cmd is 11 bit bus which contains data about command to perform:
- 2 bits for command (NOP - no operation / stop current operation, BASE - move to one of the endstops, MOV - move by given number of steps)
- 1 bit for direction (0 - move to endstop 1, 1 - move to endstop 2)
- 8 bits for MOV command to set number of steps to perform (treated as unsigned 8 bit integer)
LOW to HIGH transition on latch pin starts loaded command.
Also you can see that the controller has 4 outputs: 3 for A4988 interface and busy pin which is tells A53 CPU whether the previously latched command is still in progress or finished.
The code for this block can be seen below:
module stepper(
input clk,
input latch,
input [10:0] cmd,
input force_ena,
input stop1, // Active LOW.
input stop2, // Active LOW.
output step,
output reg dir = 1'b0,
output ena, // Active LOW.
output busy
);
localparam reg unsigned [3:0] CMD_MSB = 4'd10;
localparam reg unsigned [3:0] CMD_LSB = CMD_MSB - 4'd1;
localparam reg unsigned [3:0] DIR_BIT = CMD_LSB - 4'd1;
localparam reg unsigned [3:0] PARAM_MSB = DIR_BIT - 4'd1;
localparam reg unsigned [3:0] PARAM_LSB = 0;
localparam reg unsigned [1:0] CMD_NOP = 2'd0;
localparam reg unsigned [1:0] CMD_BASE = 2'd1;
localparam reg unsigned [1:0] CMD_MOV = 2'd2;
localparam reg DIR_STOP1 = 1'b0;
localparam reg DIR_STOP2 = 1'b1;
// Store current command.
reg unsigned [1:0] curr_cmd = 2'd0;
// Used to track whether new command arrived.
reg cmd_latch_flip = 1'b0; // Flips in latch detection to inform pos clock edge detection that new command was latched.
reg cmd_posedge_flip = 1'b0; // Get's compared to cmd_latch_flip in pos clock edge detection
// to detect whether new command was latched and reset state registers.
// Flip flop for step on pos and neg clock edges.
reg step_posedge = 1'b0;
reg step_negedge = 1'b0;
// Flip flop for busy on latch and pos clock edge.
reg busy_latch = 1'b0;
reg busy_posedge = 1'b0;
// For MOV command.
reg unsigned [7:0] steps_performed = 8'd0;
reg unsigned [7:0] steps_to_perform = 8'd0;
assign busy = busy_latch ^ busy_posedge;
assign step = step_posedge ^ step_negedge;
assign ena = force_ena ? 1'b0 : ~busy;
always @ (posedge latch) begin
// Stop command received so stop doing stuff.
if(cmd[CMD_MSB:CMD_LSB] == CMD_NOP && busy) begin
busy_latch <= ~busy_latch;
end
// BASE or MOV received so prepare to move.
else if (cmd[CMD_MSB:CMD_LSB] == CMD_BASE || cmd[CMD_MSB:CMD_LSB] == CMD_MOV) b egin
if(~busy) busy_latch <= ~busy_latch;
steps_to_perform <= cmd[PARAM_MSB:PARAM_LSB];
dir <= cmd[DIR_BIT];
end
cmd_latch_flip <= ~cmd_latch_flip; // Mark that new command was received.
curr_cmd <= cmd[CMD_MSB:CMD_LSB];
end
always @ (posedge clk) begin
// New command arrived so reset MOV's step counter.
// This takes first clock cycle after latch.
if(cmd_latch_flip != cmd_posedge_flip) begin
cmd_posedge_flip <= ~cmd_posedge_flip;
steps_performed <= 8'd0;
end
// Do received command.
else if (busy) begin
case(curr_cmd)
CMD_BASE: begin
// Stop if stepper hit corresponding endstop.
if ((dir == DIR_STOP1 && ~stop1) || dir == DIR_STOP2 && ~stop2) beg in
busy_posedge <= ~busy_posedge;
end
// Do step otherwise.
else begin
if(~step) step_posedge <= ~step_posedge;
end
end
CMD_MOV: begin
// Stop if stepper performed desired number of steps
// or hit endstop corresponding to direction of rotation.
if ((steps_performed == steps_to_perform) || (dir == DIR_STOP1 && ~stop1) || dir == DIR_STOP2 && ~stop2) begin
busy_posedge <= ~busy_posedge;
end
// Do step otherwise.
else begin
steps_performed <= steps_performed + 8'd1;
if (~step) step_posedge <= ~step_posedge;
end
end
endcase
end
end
// Pull step LOW if it's high.
always @ (negedge clk) begin
if (step) step_negedge <= ~step_negedge;
end
endmoduleWhile it wouldn't be too hard to program such controller in CPU (probably even easier), writting it into FPGA saves CPU cycles and allows for REALLY smooth real time control as steps are as consistent as possible, there is no delay from transmitting every step pulse through AXI, no scheduler switching processes between steps, no endstop pooling, etc. Just set command, latch and wait for busy_flag = false, done!
PetaLinuxAfter creating nice and clean hardware structure of the design, the next step is to create bootable Linux image, which will perform all of the higher processing, such as floating point math, communication with LIDAR, ROS and dynamic HLS kernels. Considering that it was pretty much my first time with compiling Linux from scratch, I was a bit worried about this step. As it turned out, the compilation process was trivial (literally one command). The main problem I had at this step was to append valid Ethernet and USB3.0 hub configuration to the device tree as these peripherals are disabled by default. Below you can see the valid device tree addition which resides in <PETALINUX PROJ>/project-spec/meta-user/recipes-bsp/device-tree/files/system-user.dtsi
/include/ "system-conf.dtsi"
/ {
chosen {
bootargs = "earlycon console=ttyPS1,115200 clk_ignore_unused ext4=/dev/mmcblk1p2:/rootfs init_fatal_sh=1 cma=1000M ";
stdout-path = "serial1:115200n8";
};
firmware {
zynqmp-firmware {
method = "smc";
u-boot,dm-pre-reloc;
#power-domain-cells = <0x01>;
compatible = "xlnx,zynqmp-firmware";
phandle = <0x0c>;
pinctrl {
compatible = "xlnx,zynqmp-pinctrl";
status = "okay";
phandle = <0x32>;
usb0-default {
phandle = <0x82>;
mux {
function = "usb0";
groups = "usb0_0_grp";
};
conf {
slew-rate = <0x01>;
groups = "usb0_0_grp";
power-source = <0x01>;
};
conf-tx {
pins = "MIO54\0MIO56\0MIO57\0MIO58\0MIO59\0MIO60\0MIO61\0MIO62\0MIO63";
bias-disable;
};
conf-rx {
pins = "MIO52\0MIO53\0MIO55";
bias-high-impedance;
};
};
i2c1-default {
phandle = <0x7c>;
mux {
function = "i2c1";
groups = "i2c1_6_grp";
};
conf {
slew-rate = <0x01>;
bias-pull-up;
groups = "i2c1_6_grp";
power-source = <0x01>;
};
};
i2c1-gpio {
phandle = <0x7d>;
mux {
function = "gpio0";
groups = "gpio0_24_grp\0gpio0_25_grp";
};
conf {
slew-rate = <0x01>;
groups = "gpio0_24_grp\0gpio0_25_grp";
power-source = <0x01>;
};
};
};
};
};
};
&i2c1 {
pinctrl-names = "default\0gpio";
pinctrl-0 = <0x7c>;
pinctrl-1 = <0x7d>;
usb5744@2d {
reset-gpios = <0x0e 0x2c 0x00>;
compatible = "microchip,usb5744";
reg = <0x2d>;
phandle = <0x87>;
};
};
&usb0 {
pinctrl-names = "default";
pinctrl-0 = <0x82>;
phy-names = "usb3-phy";
phys = <0x16 0x02 0x04 0x00 0x01>;
reset-names = "usb_crst\0usb_hibrst\0usb_apbrst";
};
&dwc3_0 {
snps,usb3_lpm_capable;
dr_mode = "host";
maximum-speed = "super-speed";
/* dma-coherent; */
/* snps,enable-hibernation; */
};
&amba {
dpcma: dpcma {
compatible = "deephi,cma";
};
};
&fpga_full {
power-domains = <&zynqmp_firmware 69>;
};After making sure that all required peripherals work, all I had to do was do add USB_SERIAL (for serial communication through USB) and USB_SERIAL_CP210x (to be able to use family of CP210x USB - UART converters) flags to kernel config to be able to communicate with my LIDAR. I've also enabled Xilinx Runtime support in rootfs config and installed ROS2 for later use.
Now, having the system's image done, I was able to focus on high level code.
Lidar ProcessingWhen I was designing this part of the project I've had some thoughts about how should I represent the scans, how could I verify whether the math that converts multiple 2D scans into 3D one was on point and also, how could I show off the results. The first thing that came to my mind was to connect somehow the app with desktop Python application that will display the results using Matplotlib, but this method would turn this project into some sort of tech demo, without any real world usage potential. Then, it same to my mind that there is some popular framework that has standarized way to represent different types of sensory data, that can visualize this data in a clear manner and also makes this project somewhat practical as due to standards, it can be seamlessly integrated into new or existing projects. And yes, this framework I'm talking about is of course ROS2.
With the use of ROS2 I can easily display and verify my results using RViz2 and standard PointCloud2 message. Thanks to ROS2's decentralized nature, my data in PointCloud2 format is available right away to any of the ROS2 capable devices connected to my home network. And thanks to this, I could see my data through RViz2 running on my PC in real time. This also means that this project can be used as data provider for common ros packages, in example for mapping or even SLAM with some luck.
To get 3D data from just designed 3D lidar, it is necessary to perform three logical steps: use the PL stepper controller to change position of 2D LIDAR between it's scans, use 2D lidar to get chunk of full 3D scan, convert all received chunks along with other available data to PointCloud2 message understandable by common ROS nodes and also to intermediate format understandable by human detecting neural net. For reasons described later in the text, the converter will be implemented as hardware kernel. Below you can see rough sketch of algorithm to generate single 3D scan:
Steppercontrol
While waiting for this long and boring process of PetaLinux compilation, I was reading how exacly can I control AXI GPIOs connected to my PL stepper controller. All I saw were some scary GPIO and AXI libraries that were nowhere to be found in my Ubuntu environment. As it turned out, these libraries were required only for bare metal applications. In Linux all attached AXI peripherals are visible like all other standard devices and so I could control them using C++'s file streams to /sys/class/gpio/gpio<n> like in below.
void GPIO::write(bool val) {
if (!gpio)
throw GPIOUnaccessibleException(valPath, gpioNum);
gpio << val;
gpio.flush();
}
bool GPIO::read() {
if (!gpio)
throw GPIOUnaccessibleException(valPath, gpioNum);
gpio.seekg(std::ios_base::beg);
bool res
gpio >> res;
return res;
}This allowed me to write rough sketch of C++ class to control the PL stepper controller very fast:
void StepperController::latchCmd() {
gpio[latchOffset].write(0);
gpio[latchOffset].write(1);
gpio[latchOffset].write(0);
}
void StepperController::home(Endstop dir) {
gpio[cmdOffset].write(0);
gpio[cmdOffset - 1].write(1);
gpio[dirOffset].write(dir);
latchCmd();
}
void StepperController::move(Endstop dir, uint8_t steps) {
gpio[cmdOffset].write(1);
gpio[cmdOffset - 1].write(0);
gpio[dirOffset].write(dir);
for (unsigned int i = 0; i < paramLength; i++) {
gpio[LSBParamOffset + i].write(steps & (1 << i));
}
latchCmd();
}
void StepperController::stop() {
gpio[cmdOffset].write(0);
gpio[cmdOffset - 1].write(0);
latchCmd();
}2DLIDAR control
There is not much to write about the 2D LIDAR as Ydlidar provides easy to use SDK that can be easily integrated into any C++ project. The whole pipeline to get it working was: connect to serial -> turn motor on -> read scans in loop -> turn motor off -> disconnect. I don't think you can get simpler as that. It's worth noting that the provided SDK alone sets up LIDAR's hardware faster than Ydlidar's ROS node. There's no delay nor this some-seconds-sequence to set the laser spinning, which is weird as the ROS node uses the same SDK and pretty much the same code as mine during tests.
Scan time tuning
Assumimg 25 LIDAR scans per 3D scan and the LIDAR's scan frequency of 7.5Hz, it would take around 3.3 seconds per one scan, which is not that bad in itself, but there should be some places for improvements.
The main bottleneck came from the scan time of the LIDAR itself. By default the LIDAR spins with frequency of 7.5Hz and there isn't any option in SDK to increase it even when the product page of the LIDAR says it can go up to 12Hz. Well, looking (for the first time) into the instruction, it turned out that the biggest improvement in this whole project happened to be in pin M_SCTR, which is responsible for PWM motor control (0-3.3V, 0 - max speed, 3.3 - min speed). By default this pin is set at 1.65V, which translates to 50% PWM fill. The pin in cable connector was left empty, so I've attached the cable by myself and shorted it to the ground, which was the black cable in the connector.
With this simple trick I brought down the scan time to around 2 seconds:
Scan processing
This was the part which took like two days of me trying to be mathematican, wanting to come up with some smart and simple solution to convert from a bunch of tilted polar coordinate transforms into common cartesian one. I've drawn a lot of triangles, arcs, projections and other trigonometry stuff until I gave up and just did it the standard way, by converting polar into cartesian, then rotating these cartesian coordinates into common reference frame. To be honest, when I did the math, I don't think it would be possible to come with anything simpler than that. Starting with polar ones, there is nothing spectacular here. The formula is always the same simple pair of sine and cosine:
Where r is the measured range to obstacle at LIDAR's angle alpha.
Now comes the cool stuff. It is known that polar coordinates are two dimensional, so our z coordinate in this case always equals to 0, which makes next calculations much simpler. Next known thing is that the stepper rotates the LIDAR (and it's polar coordinates) only in one axis. This means that, instead of using this big and scary 3D rotation matrix which takes into account rotations from x, y and z directions, I could use only part of it that is responsible for one direction (y in my case):
But if you look at this matrix you will see that only first column of it is needed, as y (second column) is constant, and z (third column) always equals to zero!
The last known rule is that the LIDAR has some offset from the center of the cradle (the threaded rod), but the offset is always constant. So to convert this offset from vector form into x, z parts of it use:
Where beta is the current angle of the stepper.
The equations in code form looks like this:
void Lidar::generatePointCloudSW(float startStepperAngle, int sign) {
union FloatData {
float f;
char buf[sizeof(float)];
};
FloatData x, y, z;
// Process every obtained lidar scan.
float currStepperAngle = startStepperAngle;
unsigned int pointOffset = 0;
for (auto scan : scans) {
// Get rotation and shift params.
float rotationOffsetY = -currStepperAngle;
float transformOffsetX = std::sin(std::abs(rotationOffsetY)) * conf.lidar2d.heightFromCenter;
float transformOffsetZ = std::sqrt(std::pow(conf.lidar2d.heightFromCenter, 2) - std::pow(transformOffsetX, 2));
// Convert each sample of current scan to point cloud.
float currScanAngle = scan.config.min_angle;
for (auto sample : scan.ranges) {
// Convert sample from polar to cartesian in rotated lidar's frame.
x.f = sample * std::sin(currScanAngle);
y.f = -sample * std::cos(currScanAngle);
// Rotate and shift sample to main lidar's frame.
float tx = x.f;
x.f = tx * std::cos(rotationOffsetY) - transformOffsetX;
z.f = -tx * std::sin(rotationOffsetY) - transformOffsetZ;
// Save results in PointCloud2 blob.
for (unsigned int byte = 0; byte < sizeof(float); byte++) {
scanMsg.data[pointOffset + scanMsg.fields[0].offset + byte] = x.buf[byte];
scanMsg.data[pointOffset + scanMsg.fields[1].offset + byte] = y.buf[byte];
scanMsg.data[pointOffset + scanMsg.fields[2].offset + byte] = z.buf[byte];
}
currScanAngle += scan.config.ang_increment;
pointOffset += scanMsg.point_step;
}
currStepperAngle += sign * angIncBet2DScans;
}
}I've verified the algorithm in Rviz2:
This is the part in which I've wanted to complain about performance and excuse myself into using custom kernel function. But to my surprise, the average time of execution of this function at around 17000 scans is 8ms, which is nothing compared to LIDAR's scan time of around 2 seconds. Well, I guess there is no point in making it for performance reasons, but I'm not gonna lie that since the start of this project this point in scanning pipeline was meant to be hardware accelerated. If not for high performance gains, then I'll just do it out of curiosity and to compare kernel with CPU implementation and judge how faster/slower it is.
The implementation took me like 10 minutes as it was only necessary to replace std:: with hls::, add some input arguments and replace some high level syntax:
void krnl_lidar_proc(const float* ranges, unsigned int rangesSize, unsigned int numScans, float scanStartAngle, float scanAngleInc, float stepperStartAngle, float stepperAngleInc, float lidarHeightOffset, uint8_t* outBuf) {
FloatData x, y, z;
// Process every obtained lidar scan.
float currStepperAngle = stepperStartAngle;
unsigned int pointOffset = 0;
for (unsigned int scan = 0; scan < numScans; scan++) {
// Get rotation and shift params.
float rotationOffsetY = -currStepperAngle;
float transformOffsetX = hls::sin(hls::abs(rotationOffsetY)) * lidarHeightOffset;
float transformOffsetZ = hls::sqrt(lidarHeightOffset * lidarHeightOffset - transformOffsetX * transformOffsetX);
// Convert each sample of current scan to point cloud.
float currScanAngle = scanStartAngle;
for (int sample = 0; sample < rangesSize; sample++) {
int currSample = scan * rangesSize + sample;
// Convert sample from polar to cartesian in rotated lidar's frame.
x.f = ranges[currSample] * hls::sin(currScanAngle);
y.f = -ranges[currSample] * hls::cos(currScanAngle);
// Rotate and shift sample to main lidar's frame.
float tx = x.f;
x.f = tx * hls::cos(rotationOffsetY) - transformOffsetX;
z.f = -tx * hls::sin(rotationOffsetY) - transformOffsetZ;
// Save results in PointCloud2 blob.
for (unsigned int byte = 0; byte < sizeof(float); byte++) {
outBuf[pointOffset + byte] = x.buf[byte];
outBuf[pointOffset + sizeof(float) + byte] = y.buf[byte];
outBuf[pointOffset + sizeof(float) * 2 + byte] = z.buf[byte];
}
currScanAngle += scanAngleInc;
pointOffset += 3 * sizeof(float);
}
currStepperAngle += stepperAngleInc;
}
}
}To run this kernel, I've written simple class that wraps all of the OpenCL/XRT objects and buffers elegantly into simple interface.
class KernelLidarProc {
private:
cl::Context context;
cl::CommandQueue queue;
std::vector<char> binBuf;
cl::Program::Binaries binaries;
std::vector<cl::Device> devices;
cl::Program program;
cl::Kernel kernel;
cl::Buffer rangesBuf;
cl::Buffer outBuf;
float *rangesPtr;
int rangesSize = -1;
uint8_t *outPtr;
int outSize = -1;
bool findDevice();
bool loadBinary(const std::string &xclbin);
public:
KernelLidarProc() = default;
KernelLidarProc(const std::string &xclbin);
~KernelLidarProc();
bool init(const std::string &xclbin);
void deinit();
bool setPersistentArgs(unsigned int numScans, unsigned int singleScanRangesCnt, flo at scanStartAngle, float scanAngleInc, float centerOffset);
bool allocateBuffers(int rangesSize, int outSize);
void setRangesChunk(const std::vector<float> &ranges, unsigned int offset);
bool run(float stepperStartAngle, float stepperAngleInc);
void getOutBuf(std::vector<uint8_t> &buf);
};In short: use "setRangesChunk" after each 2D LIDAR scan to allocate range measurements into OpenCL buffer, after all scans are performed use "run", then "getOutBuf" to fill ROS2's PointCloud2 data buffer.
Usage of the kernel brought down processing time from 8ms to 0.4ms, which is amazing considering the amount of data, floating points and trigonometry. And while alone seems amazing, as I found out, the real kernel's processing time of the cloud points was at around 0.1ms. The 0.3ms overhead comes from std::copy from OpenCL's output buffer into PointCloud2 data buffer, which is sadly necessary as XRT uses memory alignment of 4K, while PointCloud2 data vector uses default memory alignment of uint8_t, so additional copy can't be avoided without going REALLY deep into ROS2 message system (which I've tried to some degree, but didn't get too far).
At this point my LIDAR was capable of generating simple 3D scans of the environment and send them to RViz2 and other agents through ROS2's messaging system.
Human detectionScan preprocessing
Considering that the data from the LIDAR can have multiple totally different representations, is is important to select the one that will be easy to label manually by human (me, sadly), easy to select neural model for and in as much compact form as possible, which will yield gains during training and inference. There are two types of data that are available out of the box: The raw scan / range data and point cloud. The scan / range data is a no-no as it looks like nothing and it would be impossible to label it:
On the other side, the sematic segmentation of raw 3D point cloud data looks cool and smart, but it has rather complicated pipeline and in my opinion is kind of overkill for embedded devices. It has it's uses, in example in dense clouds, where classified objects are fully scanned, but thats not the case in this project.
To create input to my neural network, I've decided to go with third, intermediate representation of scans. Considering that the LIDAR scans the environment somewhat like a person would do while creating panoramic picture with a smartphone, I thought that it's a good idea to use similar method and as an input to the network pass flat panoramic representations of the scans. This method has some advantages that pretty much sold it to me: The first one is that the data is just a simple grayscale image representation of the scan, in which height is the angle of the scan, width is defined by number of samples from single 2D scan and level of gray is just measured range, which means that it can be used with standard sematic segmentation networks like U-Net. The second advantage is that it is stupid easy to label. The humans are easily distinguishable from the envoronment, even while deformed due to spherical projection:
For a disadvantage I'd say that it is a bit bigger than raw scan / range grayscale image, but considering the pros it is a no issue to be honest.
To get the correct pair of (x, y) coordinates I have used such function (along with HW version implemented as the kernel):
void Lidar::generatePanoramicImageSW() {
float startStepperAngle = conf.stepper.currDirection == StepperController::ENDSTOP1 ? -conf.stepper.endstopAngle : conf.stepper.endstopAngle;
int sign = conf.stepper.currDirection == StepperController::ENDSTOP1 ? 1 : -1;
int imgWidth = panoramicScanMsg.layout.dim[1].stride;
int imgHeight = std::round(2 * conf.stepper.endstopAngle * 180 / M_PI);
float currStepperAngle = startStepperAngle;
for (unsigned int scan = 0; scan < scans2d.size(); scan++) {
float scan2DCurrAngle = scans2d[scan].config.min_angle;
float scan2DAngleInc = scans2d[scan].config.ang_increment;
for (unsigned int x = 0; x < scans2d[scan].ranges.size(); x++) {
int y = imgHeight - std::round(currStepperAngle * 180.0 / M_PI * std::sin(scan2DCurrAngle) + std::fabs(conf.stepper.endstopAngle) * 180.0 / M_PI);
panoramicScanMsg.data[imgWidth * y + x] = scans2d[scan].ranges[x] / conf.lidar2d.maxRange; // Normalize the scan.
scan2DCurrAngle += scan2DAngleInc;
}
currStepperAngle += sign * conf.stepper.angIncPer2DScan;
}
}During the hardware description I wrote that my 3D LIDAR is able to scan roughly two quarters of a sphere, you can see that clearly now:
This data will be used as neural network input on the device directly in vectorized form from the code above, but to get the training data (and the above scan pictures), the LIDAR additionaly publishes Float32MultiArray message with the content of this vectorized form, which is then reshaped and processed on the host in Python 3 based ROS2 node:
def listener_callback(self, msg):
heatmap = np.array(msg.data)
heatmap = np.reshape(
heatmap, (msg.layout.dim[0].size, msg.layout.dim[1].size))
self.last_file = self.get_last_file()
plt.imshow(heatmap, cmap='rainbow',
interpolation='none', vmin=0, vmax=0.2)
plt.pause(0.05)
np.save('dataset/%d.npy' % self.last_file, heatmap)
plt.imsave("dataset/%d.png" % self.last_file, heatmap)This calback receives the message, reshapes it, shows on desktop (because why not), then saves it as numpy array for Tensorflow and as png image so I can create labels using labeling software. Thanks to this, the dataset collection came down to me moving around the room for some time (moving the LIDAR too from time to time), then with all the data collected I could sit down and mindlessly label it.
Before training, there was some important preprocessing of the dataset required. Firstly, as you can see above, label image has two colors: white for human, gray for no human, which corresponds to numeric values of 1 and 0.5. Considering that this is a binary segmentation task, value of 0.5 makes things a bit more complicated than necessary. As the first preprocessing task we will set non gray values to 0:
label[label < 128] = 0Next thing worth nothing is that the label is pretty much a painted blob of continous white color, which conflicts with the format of input image, that could be summed as projection of discrete points (you can see in above picture that the projection input image is just a bunch of loose points). Labeling every single point in the image would be a close to impossible task, but thanks to NumPy it can be done using it's fancy indexing, which can be summed as: set label to 1 where label is 1 and sample is not 0:
label[np.logical_and(label > 0, sample == 0)] = 0After both of these simple commands, the label looks much better:
The last thing to do before training was to generate loss weight matrix. The matrix will allow to achieve much faster convergence, as the loss function will focus more on more important areas of the image. In this project's case it means: focus more on empty space between labeled points, which, not by accident sounds similar to U-Net's weight function:
As you can see above, the weight function focuses on space between two closest cells (distances d1 and d2 in equation). This weight forces neural network to learn faster about this empty space.
In my case, the equation looks similar, but instead of using distance from two closest pixels, I've just used distance from one closest labeled scan point (only used d1 without d2 in the equation):
Preprocessed sample, label and weight map were saved as npy files, which allowed for fast dataset loading pipeline.
Network architecture and training
For the architecture of the neural network I've decided to use aformentioned popular U-Net.
In my case neural structure looks like this:
_______________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
=======================================================================================
input_1 (InputLayer) [(1, 128, 512, 1)] 0
_______________________________________________________________________________________
conv2d (Conv2D) (1, 128, 512, 64) 640 input_1[0][0]
_______________________________________________________________________________________
conv2d_1 (Conv2D) (1, 128, 512, 64) 36928 conv2d[0][0]
_______________________________________________________________________________________
batch_normalization (BatchNorma (1, 128, 512, 64) 256 conv2d_1[0][0]
_______________________________________________________________________________________
max_pooling2d (MaxPooling2D) (1, 64, 256, 64) 0 batch_normalization[0][0]
_______________________________________________________________________________________
conv2d_2 (Conv2D) (1, 64, 256, 128) 73856 max_pooling2d[0][0]
_______________________________________________________________________________________
conv2d_3 (Conv2D) (1, 64, 256, 128) 147584 conv2d_2[0][0]
_______________________________________________________________________________________
batch_normalization_1 (BatchNor (1, 64, 256, 128) 512 conv2d_3[0][0]
_______________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (1, 32, 128, 128) 0 batch_normalization_1[0][0]
_______________________________________________________________________________________
conv2d_4 (Conv2D) (1, 32, 128, 256) 295168 max_pooling2d_1[0][0]
_______________________________________________________________________________________
conv2d_5 (Conv2D) (1, 32, 128, 256) 590080 conv2d_4[0][0]
_______________________________________________________________________________________
batch_normalization_2 (BatchNor (1, 32, 128, 256) 1024 conv2d_5[0][0]
_______________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (1, 16, 64, 256) 0 batch_normalization_2[0][0]
_______________________________________________________________________________________
conv2d_6 (Conv2D) (1, 16, 64, 512) 1180160 max_pooling2d_2[0][0]
_______________________________________________________________________________________
conv2d_7 (Conv2D) (1, 16, 64, 512) 2359808 conv2d_6[0][0]
_______________________________________________________________________________________
batch_normalization_3 (BatchNor (1, 16, 64, 512) 2048 conv2d_7[0][0]
_______________________________________________________________________________________
max_pooling2d_3 (MaxPooling2D) (1, 8, 32, 512) 0 batch_normalization_3[0][0]
_______________________________________________________________________________________
conv2d_8 (Conv2D) (1, 8, 32, 1024) 4719616 max_pooling2d_3[0][0]
_______________________________________________________________________________________
conv2d_9 (Conv2D) (1, 8, 32, 1024) 9438208 conv2d_8[0][0]
_______________________________________________________________________________________
batch_normalization_4 (BatchNor (1, 8, 32, 1024) 4096 conv2d_9[0][0]
_______________________________________________________________________________________
up_sampling2d (UpSampling2D) (1, 16, 64, 1024) 0 batch_normalization_4[0][0]
_______________________________________________________________________________________
concatenate (Concatenate) (1, 16, 64, 1536) 0 up_sampling2d[0][0]
batch_normalization_3[0][0]
_______________________________________________________________________________________
conv2d_10 (Conv2D) (1, 16, 64, 512) 7078400 concatenate[0][0]
_______________________________________________________________________________________
conv2d_11 (Conv2D) (1, 16, 64, 512) 2359808 conv2d_10[0][0]
_______________________________________________________________________________________
batch_normalization_5 (BatchNor (1, 16, 64, 512) 2048 conv2d_11[0][0]
_______________________________________________________________________________________
up_sampling2d_1 (UpSampling2D) (1, 32, 128, 512) 0 batch_normalization_5[0][0]
_______________________________________________________________________________________
concatenate_1 (Concatenate) (1, 32, 128, 768) 0 up_sampling2d_1[0][0]
batch_normalization_2[0][0]
_______________________________________________________________________________________
conv2d_12 (Conv2D) (1, 32, 128, 256) 1769728 concatenate_1[0][0]
_______________________________________________________________________________________
conv2d_13 (Conv2D) (1, 32, 128, 256) 590080 conv2d_12[0][0]
_______________________________________________________________________________________
batch_normalization_6 (BatchNor (1, 32, 128, 256) 1024 conv2d_13[0][0]
_______________________________________________________________________________________
up_sampling2d_2 (UpSampling2D) (1, 64, 256, 256) 0 batch_normalization_6[0][0]
_______________________________________________________________________________________
concatenate_2 (Concatenate) (1, 64, 256, 384) 0 up_sampling2d_2[0][0]
batch_normalization_1[0][0]
_______________________________________________________________________________________
conv2d_14 (Conv2D) (1, 64, 256, 128) 442496 concatenate_2[0][0]
_______________________________________________________________________________________
conv2d_15 (Conv2D) (1, 64, 256, 128) 147584 conv2d_14[0][0]
_______________________________________________________________________________________
batch_normalization_7 (BatchNor (1, 64, 256, 128) 512 conv2d_15[0][0]
_______________________________________________________________________________________
up_sampling2d_3 (UpSampling2D) (1, 128, 512, 128) 0 batch_normalization_7[0][0]
_______________________________________________________________________________________
concatenate_3 (Concatenate) (1, 128, 512, 192) 0 up_sampling2d_3[0][0]
batch_normalization[0][0]
_______________________________________________________________________________________
conv2d_16 (Conv2D) (1, 128, 512, 64) 110656 concatenate_3[0][0]
_______________________________________________________________________________________
conv2d_17 (Conv2D) (1, 128, 512, 1) 577 conv2d_16[0][0]
=======================================================================================
Total params: 31,352,897
Trainable params: 31,347,137
Non-trainable params: 5,760
_______________________________________________________________________________________To train the network I've used 785 samples of me moving, sitting and standing in my room in different poses, angles, heights, positions and resolutions (1 scan per step, 1 scans per 2 steps and 1 scan per 4 steps of the stepper) of the LIDAR. It's not much to be honest but considering that it is mostly proof of concept and that my room isn't too big then it should be enough for this project (also, there is not a lot of time left to submit the entry so...). To get as much as I can from my small dataset, I've used simple augmentation. Considering that my image must always have the same format of parts of spherical projection, I was cut off from some basic augmentation methods like skew and zoom. Only vertical flip was available. To make up I had to come up with some non standard augmentation methods. For my project I've used three additional augmentation functions, that modify the range data directly, by increasing or decreasing ranges of whole scan by some constant, by increasing or decreasing ranges of scan points that are not labeled as humans and to only increase ranges that are labeled as humans:
# Increase or decrease range of whole scan.
op = bool(random.getrandbits(1))
if op:
val = random.uniform(0, 0.4)
add = bool(random.getrandbits(1))
if add:
sample[np.logical_and(sample > 0, label == 0)] += val
sample[sample > 1] = 1
else:
sample[np.logical_and(sample > 0, label == 0)] -= val
sample[sample < 0] = 0
# Increase range of detected person.
op = bool(random.getrandbits(1))
if op:
val = random.uniform(0, 0.4)
sample[np.logical_and(label > 0, sample > 0)] += val
sample[sample > 1] = 1
# Increase or decrease range of all but detected person.
op = round(random.uniform(0, 20.0))
if not op:
val = random.uniform(0, 0.2)
add = bool(random.getrandbits(1))
if add:
sample[np.logical_and(label == 0, sample != 0)] += val
sample[sample > 1] = 1
else:
sample[np.logical_and(label == 0, sample != 0)] -= val
sample[sample < 0] = 0After like two days of training, my network started showing some promising results:
After some more training time I've decided that overall results are good enough for this proof of concept project so I've quantized this network:
# Restore training from checkpoint if possible
ckpt = tf.train.Checkpoint(step=tf.Variable(1), net=net, optimizer=optimizer)
manager = tf.train.CheckpointManager(ckpt, "./tf_ckpts", max_to_keep=100)
path = manager.restore_or_initialize()
if path:
print("Restored checkpoint from %s" % path)
else:
print("Initializing training from scratch.")
# Convert to functional model.
net = net.model((128, 512, 1))
net.summary()
# Quantization dataset.
dataset = tf.data.Dataset.from_generator(
get_sample, output_types=(tf.float32, tf.float32, tf.float32)).batch(1)
# Quantize model into int8 representation.
quantizer = vitis_quantize.VitisQuantizer(net)
quantized_net = quantizer.quantize_model(calib_dataset=dataset)
quantized_net.save('./quantized/inference_model.h5')and converted to.xmodel file using Vitis-AI container:
vai_c_tensorflow2 -m ./quantized/inference_model.h5 -a ./arch.json -o ./quantized/final -n unet -e '{"input_shape":"1,128,512,1"}'Which resulted in 44MB compiled xmodel.
With the xmodel prepared, I could've started playing with the main part of this project: the inference engine.
Inference
For inference engine I've used simple B512, 1 core DPU, which I was pretty much forced to use as bigger designs wouldn't fit along with stepper controller, fan controller and HLS kernels. I can guarantee that this is more than enough for this project though.
The core uses DPU clock with frequency of 325MHz and communicates with my C++ application through VART api:
bool Detector::init(const std::string &model) {
graph = xir::Graph::deserialize(model);
xir::Subgraph *root = graph->get_root_subgraph();
std::vector<xir::Subgraph *> children = root->children_topological_sort();
for (auto child : children) {
std::string device = child->get_attr<std::string>("device");
if (device != "USER" && device != "CPU") {
runner = vart::Runner::create_runner(child, "run");
std::cout << "Subgraph: " << child->get_name() << ", device: " << device << std::endl;
auto inTensors = child->get_input_tensors();
for (auto inTensor : inTensors) {
auto shape = inTensor->get_shape();
inputHeight = shape[1];
inputWidth = shape[2];
inputScaler = std::exp2f(1.0f * (float)inTensor->get_attr<int>("fix_point"));
inputData.resize(shape[0] * shape[1] * shape[2] * shape[3]);
std::cout << "Input: " << inTensor->to_string() << std::endl;
}
auto outTensors = child->get_output_tensors();
for (auto outTensor : outTensors) {
auto shape = outTensor->get_shape();
outputHeight = shape[1];
outputWidth = shape[2];
outputScaler = std::exp2f(-1.0f * (float)outTensor->get_attr<int>("fix_point"));
outputData.resize(shape[0] * shape[1] * shape[2] * shape[3]);
std::cout << "Output: " << outTensor->to_string() << std::endl;
}
break;
}
}
allGood = true;
return true;
}The inference itself looks like this:
std::vector<float> Detector::run(const std::vector<float> &img, int imgWidth, int imgHeight) {
fillInputData(img, imgWidth, imgHeight);
std::vector<std::unique_ptr<vart::TensorBuffer>> inputs, outputs;
std::vector<vart::TensorBuffer *> inputsPtr, outputsPtr;
std::unique_ptr<xir::Tensor> inputTensor = xir::Tensor::create(runner->get_input_tensors()[0]->get_name(),
runner->get_input_tensors()[0]->get_shape(),
xir::DataType{xir::DataType::XINT, 8});
std::unique_ptr<xir::Tensor> outputTensor = xir::Tensor::create(runner->get_output_tensors()[0]->get_name(),
runner->get_output_tensors()[0]->get_shape(),
xir::DataType{xir::DataType::XINT, 8});
inputs.push_back(std::make_unique<CpuFlatTensorBuffer>(inputData.data(), inputTensor.get()));
inputsPtr.push_back(inputs[0].get());
outputs.push_back(std::make_unique<CpuFlatTensorBuffer>(outputData.data(), outputTensor.get()));
outputsPtr.push_back(outputs[0].get());
auto jobId = runner->execute_async(inputsPtr, outputsPtr);
runner->wait(-1, -1);
return convertOutputData(imgWidth, imgHeight);
}As you can see in the code snippet above, the inference method takes vector of floats, which is in fact the data container of Float32MultiArray message! This vector is then converted to vector of signed 8 bit integers and passed to VART runner. After that, the output data from the runner is converted back to vector of floats of the same size as the input image. After my initial tests I've measured that inference, along with data pre/postprocessing takes roughly 2.5ms, which I've had to check multiple times as it was kinda hard to belive. To confirm this visually, I've created additional float publisher and copy pasted my dataset listener node (with dataset saving functions removed), and looks like it's in fact working as expected (see video below).
Result postprocessing
To convert the results into the point cloud, I've used the same approach as in generating float array, just in reverse:
void krnl_projection_to_cloud(const float* rangesBuf, unsigned int single2DScanSize,
unsigned int num2DScans, float scan2DStartAngle,
float scan2DAngleInc, float stepperStartAngle,
float stepperAngleInc, float stepperEndstopAngle, float centerOffset,
const float* inferenceBuf, unsigned int imgWidth, unsigned int imgHeight,
uint8_t* cloudBuf) {
FloatData cloudX, cloudY, cloudZ;
// Process every obtained lidar scan.
float currStepperAngle = stepperStartAngle;
unsigned int pointOffset = 0;
for (unsigned int scan = 0; scan < num2DScans; scan++) {
// Get rotation and shift params.
float rotationOffsetY = -currStepperAngle;
float transformOffsetX = hls::sin(hls::abs(rotationOffsetY)) * centerOffset;
float transformOffsetZ = hls::sqrt(centerOffset * centerOffset - transformOffsetX * transformOffsetX);
// Process every obtained lidar sample.
float scan2DCurrAngle = scan2DStartAngle;
for (int x = 0; x < single2DScanSize; x++) {
int currSample = scan * single2DScanSize + x;
int y = imgHeight - hls::round(currStepperAngle * RAD_2_DEG * hls::sin(scan2DCurrAngle) + stepperEndstopAngle * RAD_2_DEG);
// Overflow might happen.
if (y >= imgHeight)
continue;
float range = inferenceBuf[imgWidth * y + x] ? rangesBuf[currSample] : 0;
// Convert sample from polar to cartesian in rotated lidar's frame.
cloudX.f = range * hls::sin(scan2DCurrAngle);
cloudY.f = -range * hls::cos(scan2DCurrAngle);
// Rotate and shift sample to main lidar's frame.
float tx = cloudX.f;
cloudX.f = tx * hls::cos(rotationOffsetY) - transformOffsetX;
cloudZ.f = -tx * hls::sin(rotationOffsetY) - transformOffsetZ;
// Save results in PointCloud2 blob.
for (unsigned int byte = 0; byte < sizeof(float); byte++) {
cloudBuf[pointOffset + byte] = cloudX.buf[byte];
cloudBuf[pointOffset + sizeof(float) + byte] = cloudY.buf[byte];
cloudBuf[pointOffset + sizeof(float) * 2 + byte] = cloudZ.buf[byte];
}
scan2DCurrAngle += scan2DAngleInc;
pointOffset += 3 * sizeof(float);
}
currStepperAngle += stepperAngleInc;
}
}This kernel converts the spherical projection into 3D point cloud, which then is sent to additional PointCloud2 ROS topic, which can then be seen in RViz2:
On the video above you can see that network in fact performs valid human detection (with some false positives for some reason, not enough data maybe?).
Full pipeline
To sum up the project, below you can see full ROS2 node's pipeline for single 3D scan:
The node publishes four messages: Full 3D scan of the environment, panoramic image, panoramic image containing only human detections and filtered 3D cloud containing only human detections.
Conclusions
- 3D vs 2D LIDAR price difference aside, I still think that it was a good idea to use 2D LIDAR here as 3D LIDARS typically return data already in point cloud form, which means that there is no this intermediate format of 2D laser scans which allows to create matrix "image" for neural network.
- It would be better to use smooth TMC stepper drivers instead of the cheapest A4988 as during rather fast stepper movements between 3D scans the frame was vibrating like there's no tomorrow.
- The LIDAR samples shown in this project are in somewhat low resolution as my LIDAR is probably dying on his own and after further inspection I've confirmed that it returns mostly zeros from measurements... not cool.
- The human 3D point cloud data could be easily collected to clusters and the clusters could be processed into simple bounding boxes (one per human) making human's representation even simplier, which would increace network's throughtput, but that's the idea for later time as the deadline is getting closer.
- After some testing I've measured that kernel pipeline is around 9 times faster than CPU implementation. It would be possible to speed it up even more as most of time of kernel pipeline is wasted on data copy from OpenCL pointer to ROS2's std::vector's container due to XRT's pointer allocator requirements. If someone is capable to replace ROS2's default STL allocator, then speed gains would be colossal (talking about 40 times faster rather than 9). While it doesn't matter in such project (27ms vs 3ms on around 17000 LIDAR scans), it would make big difference in projects that process denser scans (millions of samples).
- As you can see on video posted above, when moved, LIDAR reading can become chaotic and in some times unreadable at all. In newer versions of the project it would be a good idea to attach IMU sensor and use it to sompensate LIDAR movement. It won't work on other moving objects though.
Instructions
Pretty much follow instructions from project's repository. Physical design aside, building the project consists of running bitstream generation in Vivado and two Shell scripts that will grind through all complicated build steps for several hours. After that, image and program's binaries will be ready to deploy on starter kit using SCP and putty.









{kind=link}
{kind=link}
Comments