


Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
| ||||||
| ||||||
| ||||||
| ||||||
With the proliferation of low-cost sensors and the Internet-of-Things (IoT), we are now living in a world in which far more data is being collected than can reasonably be processed and stored. Much of this data takes the form of time series: an ordered sequence of data points captured at a sensor-specific sampling frequency. Given the most recent window of sampled data points, we wish to ask the following simple and straightforward question
- Have we seen a similarly shaped pattern before?
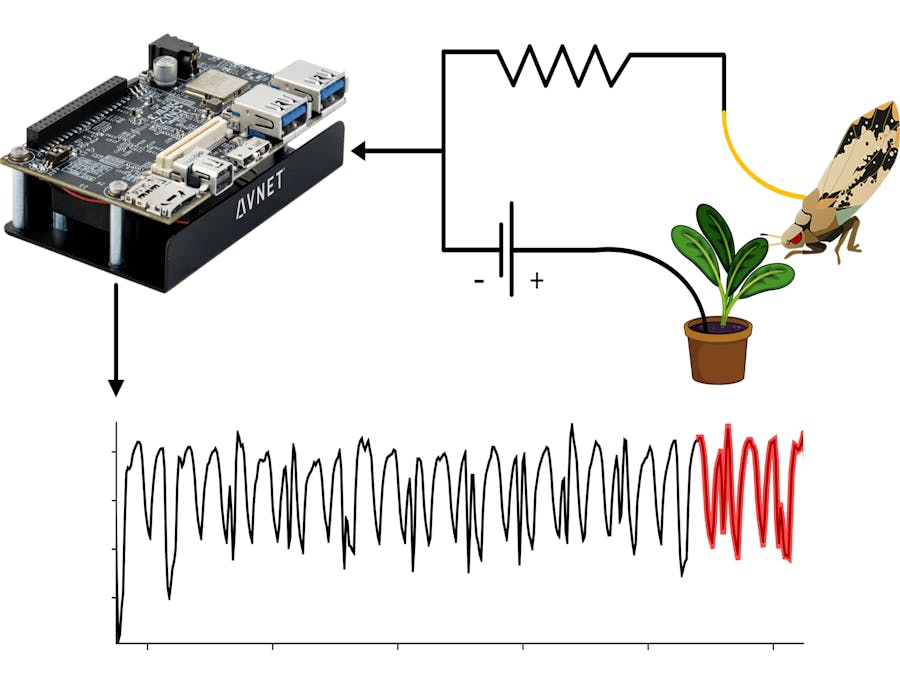
Figure 1, below, gives two examples of how this question may generalize to important scientific domains. On top, an entomologist is trying to understand insect behavior based on data obtained from an Electrical Penetration Graph (EPG); on the bottom, a seismologist wants to know if similar readings have been archived in the historical record. Many other important applications of similar time series analysis exist, and computational methods designed for time series analysis in one domain readily transfer to others.
This question is relatively straightforward to answer if the entire time series can be stored and archived; however, as time series grow large, searching the history becomes intractable, even at the cloud computing scale. In contrast, we propose to answer this question probabilistically using machine learning: our system trains a 2-dimensional convolutional neural network (2D-CNN) and deploys it on a Xilinx Ultra96-V2 FPGA board. The 2D-CNN predicts the similarity of a recent sampling of data points to the time series that were used to train the model.
The entire time series history can be searched using a data structure called the Matrix Profile (MP) [1], as shown in Figure 2. Without going into too much detail, the MP is relatively expensive to compute [2]; however, given the MP, many classically challenging time series data mining tasks such as anomaly detection, classification, and motif discovery become trivial. Ideally, we would like to perform these tasks as close to the sensor as possible [3], thereby eliminating the need to transmit and store data in the cloud for post-hoc analysis.
Our solution uses machine learning to predict the value of a Learned Approximate Matrix Profile (LAMP) [4], as shown in Figure 3, rather than computing the MP directly. The runtime of LAMP is orders of magnitude faster than computing and updating the MP as each datapoint arrives. This project reports an implementation of LAMP on a Ultra96-V2 FPGA board. We show that our implementation maintains an accuracy of over 90% with comparable inference execution time to similar CPU implementation.
The 2D-CNN neural network model at the core of LAMP is trained offline; it is implemented on a Xilinx Ultra96-V2 FPGA for inference. We implemented the 2D-CNN using the Xilinx Vitis AI compiler, and synthesized it onto the programmable Xilinx Deep Learning Processing Unit (DPU) overlay for acceleration. The DPU, shown in Figure 4, supports common CNN layers such as convolution, deconvolution, max pooling, ReLU, and others. The DPU fetches instructions generated by the Vitis AI compiler from off-chip memory; on-chip memory buffers input, intermediate, and output data, while trying to re-use data as much as possible to minimize data transfer latencies. The processing element (PE) at the heart of the DPU computing engine consists of multipliers, adders, and accumulators.
All the weights and biases in our trained 2D-CNN model are implemented using 8-bit fixed point arithmetic to increase the efficiency of the design. We have further modified the model to make it suitable for Xilinx DPU. In the original 2D-CNN model [4], shown in Figure 5.left, a Convolutional layer is followed by ReLU and then Batch Normalization. This organization leads to sub-optimal performance, because the Vitis AI compiler cannot merge the Convolutional and Batch Normalization layers, because they are separated by an activation function; this leads to both poor performance and poor prediction. To overcome this difficulty, we switched the order to the ReLU and Batch Normalization layers in the 2D-CNN, as shown in Figure 5.right.
Figure 6 depicts the complete 2D-CNN model that we deployed on the Xilinx Ultra96-V2 board; all of the Batch Normalization layers are merged with the Convolutional layers. Unfortunately, the DPU does not support all the layers of the model: the Sigmoid and Global Average Pooling (named “Mean” in Figure 6) layers are offloaded to the ARM CPU.
We showcase the generalizability of our framework by evaluating the implemented design with three different datasets from three domains: seismology, entomology, and poultry farming:
- The Earthquake dataset is gathered from a seismic station [2]. The LAMP model’s output can be used to detect a seismic event in the waveform. The real-time event prediction impacts seismic hazard assessment and response and early warning systems (a snippet of this dataset is shown in Figure 1.bottom).
- The Insect EPG dataset is recorded using an Electrical Penetration Graph (EPG) that records insect behavior [2]. This time series data is the record of an insect feeding on a plant and was classified as Xylem Ingestion, Phloem Ingestion, or Phloem Salivation, which are behaviors of interest to entomologists. Understanding the feeding behavior of insects can help farmers identify vector-bearing pests that can decimate crops (a snippet of this dataset is shown in Figure 1.top).
- The Chicken Accelerometer dataset is collected by placing a tracking sensor on the back of a chicken, similar to a FitBit [5]. The sensor outputs acceleration measurements along the x-, y-, and z-axis. The data was labeled to classify the chicken’s behavior into one of three categories: Pecking, Preening, Dustbathing, and Other. Classifying chicken behavior allows farmers to detect and stop the spread of diseases among the poultry. For example, infected chickens exhibit a marked increase in preening and dustbathing behavior compared to uninfected chickens.
We split each dataset into separate data for training and inference. First, we train a LAMP model for inference using a GP; second, we import the model on the FPGA using the DPU overlay; last, we apply the test data to predict the MP values for the time series. We assess accuracy using the same methodology outlined in Ref. [4]. Table 1 reports the mean absolute error between the model’s output and the corresponding MP value, which we compute using the SCAMP algorithm [2] on a GPU for comparison. Table 1 illustrates the accuracy of each dataset as well as the size of training and test data.
The runtime of LAMP inference does not depend on the size of the representative dataset used for training; thus, the execution time is the same for a batch of input time series data across all datasets. The time to compute inference for a single batch of size 128 takes about 729ms on the Ultra96-V2 board with the PL frequency set to 100MHz; in comparison, the execution time of the same batch size on a system with an Intel Corei7-8570K CPU takes around 428ms. We don't consider the time overhead for reconfiguring the FPGA with the second DPU kernel (around 150ms). The reason is that this step can be done only once by first storing the intermediate results (first kernel's output) and later feeding them to the second kernel.
We used the following hardware and software components in this project.
Hardware: As per the rules of the Design Contest, we implemented LAMP on an Avnet Ultra96-V2 FPGA development board. We trained the LAMP models using a Thinkmate VSX R5 340V9 server, which features two Nvidia Tesla P100 GPUs; we only used one of the GPUs to train the model. We used a Micro SD card to run the pre-compiled PYNQ image on board and also load the datasets for predictions.
Software: We used two pieces of academic software to compute MPs and LAMP models as necessary. We used the SCAlable Matrix Profile (SCAMP) algorithm to compute MPs [2], which served as ground truth for LAMP model training. We then used the LAMP software [4] to train the 2D-CNN models. We compiled the LAMP models using Xilinx Vitis AI, and we configured the FPGA using the Pynq DPU Overlay. We program the SD Card with Xilinx PYNG V2.5 image to run the python host application on the ARM processor.
Hardware Components
- Avnet Ultra96-V2
- Thinkmate VXS R5 340V9 Server / Nvidia Tesla P100 GPU
- Micro SD Card
SoftwareApplications
Code and ContributionIn this section we show how to deploy LAMP on Xilinx Deep Processing Unit (DPU) and implement it on the FPGA given a pre-trained model on GPU. The instructions require Vitis-AI installed on the system.
1. Freezing Tensorflow graph
The Vitis-AI flow requires a frozen model for quantization and optimization steps. A frozen model contains information about the graph and checkpoint variables, saving these hyperparameters as constants within the graph structure. This allows fusing some of the layers together for deployment on DPU. We can generate a binary protobuf (.pb) file by running the freeze_graph.py script
python freeze_graph.py input_modelwhere input_model is the pre-trained LAMP model.
2. Quantization
We will quantize the weights and the biases and activations of the model to improve the performance of the model inference on FPGA. Currently, Xilinx DPU only supports 8 bit models, so we quantize the weights and the biases to 8 bits.
vai_q_tensorflow quantize
--input_frozen_graph frozen_graph.pb
--input_fn input_func.calib_input
--output_dir quantized
--input_nodes input_1
--output_nodes reshape_1/Reshape
--input_shapes ?,256,1,32
--calib_iter 128frozen_graph.pb is the frozen model generated in the previous step, input_func is the python file that generates the input data for quantizer (since there is no backpropagation step here, the unlabeled dataset is sufficient), and calib_iter is the number of iterations for calibrating the activations, we noticed that values larger than 128 do not increase the quantizer accuracy by a large degree.
3. Evaluation
We will test the accuracy of the generated quantized model before deploying it to the FPGA.
python evaluate.pyevaluate.py reads in the Tensorflow frozen binary graph, runs the inference, and lastly reports the mean squared error and mean absolute percentage error by comparing the model output with the labels (matrix profile values).
4. Compilation
Vitis-AI Docker image does not support Ultra96-v2 board, we need to generate the DPU configuration file (Ultra96.dcf) required in the compile step by first downloading the DPU Hardware Handoff file dpu.hwh and then running the following command
dlet -f dpu.hwhdlet is a host tool that extracts the DPU information from the input file and generates the configuration file.
Next, we will compile the model for the target hardware
vai_c_tensorflow --frozen_pb quantized\deploy_model.pb
--arch /opt/vitis_ai/compiler/arch/DPUCZDX8G/ultra96/arch.json
--output_dir .
--net_name lamparch.json is located in the files directory on the github repository. Since, Sigmoid and Global Average Pool layers are not supported by DPU, the command generates four kernels, two of which will be deployed to the FPGA and the other two will be implemented on the host ARM CPU. Xilinx DNNK API has an issue with loading the static libraries that start with the same name, in order to fix this issue, we run the same command one more time setting the output model name to dense_lamp, later, we will use lamp_0.elf and dense_lamp_2.elf when loading the kernels.
5. Running inference
First we need to install dpu-pynq on the Ultra96 board. Open a terminal and run
git clone --recursive --shallow-submodules https://github.com/Xilinx/DPU-PYNQ
cd DPU-PYNQ/upgrade
make
pip3 install pynq-dpuThe build process might take up to an hour. After that, we can run the models on board by executing lamp_dpu.ipynb. The notebook takes a time series dataset as input and writes the predictions in predict.txt file.
The MP has emerged as a revolutionary concept in time series data mining in recent years. The MP can be extended to handle missing data and guarantees no false positives or negatives. Given only the MP, most time series data mining tasks become trivial, as mentioned earlier.
The rationale for this project is that the MP is not compatible with streaming data where sampling rates impose real-time constraints on computation. LAMP solved this problem using machine learning, with initial deployment results reported using a Raspberry Pi [4]. The reason to switch to an FPGA is to improve throughput and reduce energy consumption, while keeping LAMP computation as close to the sensor as possible. This could be beneficial for domains such as seismology, where real-time event prediction can inform hazard response strategies and enhance early warning systems presently deployed.
References[1] Yeh, M., et al. Matrix Profile I: All Pairs Similarity Joins for Time Series: A Unifying View that Includes Motifs, Discords and Shapelets. IEEE ICDM 2016: 1317-1322
[2] Z. Zimmerman et al. Matrix Profile XIV: Scaling Time Series Motif Discovery with GPUs to Break a Quintillion Pairwise Comparisons a Day and Beyond. Proceedings of the ACM Symposium on Cloud Computing. 2019.
[3] Oyekanlu, E. Predictive edge computing for time series of industrial IoT and large scale critical infrastructure based on open-source software analytic of big data. Proc. IEEE Int. Conf. Big Data 2017, pp. 1663–69.
[4] Z. Zimmerman et al. Matrix Profile XVIII: Time Series Mining in the Face of Fast Moving Streams using a Learned Approximate Matrix Profile. IEEE ICDM 2019: 936-945.
[5] A. Abdoli et al. Fitbit for Chickens? Time Series Data Mining Can Increase the Productivity of Poultry Farms. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020






Comments
Please log in or sign up to comment.