
Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
| × | 1 | ||||
 |
| × | 1 | |||
 |
| × | 2 | |||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
| ||||||
 |
| |||||
 |
| |||||
 |
| |||||
| ||||||
| ||||||
 |
| |||||
 |
| |||||
| ||||||
| ||||||
| ||||||
| ||||||
| ||||||
| ||||||
Hand tools and fabrication machines | ||||||
 |
| |||||
| ||||||
| ||||||
| ||||||
| ||||||
Robot Localization, ADAS - Collision Avoidance System, Sensor Fusion, Touch-less Attendance, Indoor Navigation Assist, Gesture Cam, Security Barrier Cam, and Monocular Depth Estimate with OpenVINO, Maths& RPi
Personal Note to Judges:
- All the solutions are done by a single person, not a team
- LIDAR is used to capture depth in all the PoCs, as it is sophisticated enough to cater to most spatial AI requirements. Taken individual use-case, Depth AI hardware, or even proximity sensors may be suitable.
- Humble request not to give less weightage to this project, as it is not ultra-low-power due to RPi & LIDAR. Power considerations are discussed at the bottom. Immense effort has been put in, over the months, to build all the solutions for this challenge, as is hopefully evident from the post below.
Scenarios are countless when artificial intelligence is combined with depth perception on embedded devices. Therefore one solution may not be adequate to demonstrate the wide and immense impact of Spatial AI on human life. This project consciously aims to touch upon multiple domains, by solving different Depth AI use cases on the edge. Owing to low power constraints on the Edge, heavy emphasis has been given to mathematical algorithms, to assist and augment compute and power-intensive neural nets.
Domains & Solutions- Automotive: ADAS - Collision Avoidance System on Indian Cars
- Industrial Automation: Indoor Robot Localization with SLAM
- Safety & Security: Touch-less Attendance & Door Access Control
- Wellness & Fitness: Indoor Navigational Assistance for Blind & Elderly
- Safety & Security: Smart Cam with Gesture Alarm for Women Security
- Industrial Automation: Security Barrier Cam using Shape Context
- Disease Detection: Monocular Social Distance Tracker
- Industrial Safety: Worksite Helmet Monitoring
All the above solutions need depth information for meaningful deployment in real-world scenarios. Let's dive deep into each solution to experience the power and possibilities of Spatial AI on various domains.
India accounts for only 1% of total vehicles in the world. However, World Bank’s survey reports 11% of global road death happens in India, exposing the dire need to enhance road safety. Most of the developing countries like India pose a set of challenges, unique on their own. These include chaotic traffic, outdated vehicles, lack of pedestrian lanes and zebra crossings, animals crossing the road, and the like. Needless to say, most vehicles don't have advanced driver-assist features nor can they afford to upgrade the car for better safety.
Against this backdrop, this solution aims to augment even the least expensive cars in India with an ultra-cheap ADAS Level 0, i.e. collision avoidance and smart surround-view. Modern cars with a forward-collision warning (FCW) system or autonomous emergency braking (AEB) are very expensive, but we can augment such functions on old cars, at a low cost.
The idea is to use a battery-powered Pi connected with a LIDAR, Pi Cam, LED SHIM, and NCS 2, mounted on the car bonnet to perceive frontal objects with their depth and direction. This not only enables a forward-collision warning system but also smart driver assistance that gives alerts about traffic signs or pedestrians, walking along the roadside, or crossing the road.
LIDAR uses laser beams to compute distance based on reflection time.
Cameras generally have higher resolution than LiDAR but cameras have a limited FOV and can't estimate distance. While rotating LIDAR has a 360° field of view, Pi Cam has only 62x48 degrees Horizontal x Vertical FoV. As we deal with multiple sensors here, we need to employ visual fusion techniques to integrate the sensor output, to get the distance and angle of an obstacle in front of the vehicle. Let's first discuss the theoretical foundation of sensor fusion before hands-on implementation.
The Sensor Fusion IdeaEach sensor has its own advantages and disadvantages. Take, for instance, RADARs are low in resolution, but are good at measurement without a line of sight. In an autonomous car, often a combination of LiDARs, RADARs, and Cameras are used to perceive the environment. This way we can compensate for the disadvantages, by combining the advantages of all sensors.
- Camera: excellent to understand a scene or to classify objects
- LIDAR: excellent to estimate distances using pulsed laser waves
- RADAR: can measure the speed of obstacles using Doppler Effect
The camera is a 2D Sensor from which features like bounding boxes, traffic lights, lane divisions can be identified. LIDAR is a 3D Sensor that outputs a set of point clouds. The fusion technique finds a correspondence between points detected by LIDAR and points detected by the camera. To use LiDARs and Cameras in unison to build ADAS, the 3D sensor output needs to be fused with 2D sensor output by doing the following steps.
1. Project the LiDAR point clouds (3D) onto the 2D image.
2. Do object detection using an algorithm like YOLOv4.
3. Match the ROI to find the interested LiDAR projected points.
By doing the 3 steps above, the surrounding objects would be measured and classified using LIDAR-Camera fusion.
LIDAR-Camera Low-Level Sensor Fusion ConsiderationsWhen a raw image from a cam is merged with raw data from RADAR or LIDAR then it's called Low-Level Fusion or Early Fusion. In Late Fusion, detection is done before the fusion. However, there are many challenges to project the 3D LIDAR point cloud on a 2D image. The relative orientation and translation between the two sensors must be considered in performing fusion.
- Rotation: The coordinate system of LIDAR and Camera can be different. Distance on the LIDAR may be on the z-axis, while it is x-axis on the camera. We need to apply rotation on the LIDAR point cloud to make the coordinate system the same, i.e. multiply each LIDAR point with the Rotation matrix.
- Translation: In an autonomous car, the LIDAR can be at the center top and the camera on the sides. The position of LIDAR and camera in each installation can be different. Based on the relative sensor position, we need to translate LIDAR Points by multiplying with a Translation matrix.
- Stereo Rectification: For stereo camera setup, we need to do Stereo Rectification to make the left and right images co-planar. Thus, we need to multiply with matrix R0 to align everything along the horizontal Epipolar line.
- Intrinsic calibration: Calibration is the step where you tell your camera how to convert a point in the 3D world into a pixel. To account for this, we need to multiply with an intrinsic calibration matrix containing factory calibrated values.
To sum it up, we need to multiply LIDAR points with all the 4 matrices to project on the camera image. To project a point X in 3D onto a point Y in 2D,
- P = Camera Intrinsic Calibration matrix
- R0 = Stereo Rectification matrix
- R|t = Rotation & Translation to go from LIDAR to Camera
- X = Point in 3D space
- Y = Point in 2D Image
Note that we have combined both the rigid body transformations, rotation, and translation, in one matrix, R|t. Putting it together, the 3 matrices, P, R0, and R|t account for extrinsic and intrinsic calibration to project LIDAR points onto the camera image. However, the matrix values highly depend on our custom sensor installation.
This is just one piece of the puzzle. Our aim is to augment any cheap car with an end-to-end collision avoidance system and smart surround view. This would include our choice of sensors, sensor positions, data capture, custom visual fusion and object detection, coupled with a data analysis node, to do synchronization across sensors in order to trigger driver-assist warnings to avoid danger.
Real-World Implementation with RPi and RPLIDAR A1First, we need to assemble the Pi with RPLIDAR A1, Pi Cam, LED SHIM, and NCS 2. 2D LIDAR is used instead of 3D LIDAR as we aim to make the gadget, cheapest possible. The unit is powered by a 5V 3A 10, 000 mAH battery. For ease of assembly, a LIDAR mount is 3D printed and attached to the RPi. Part of the mount design is taken from the STL files obtained from here
Connect RPLIDAR A1 with the USB adapter that is connected to the Pi USB using a micro-USB cable. LIDAR's adapter provides power and converts LIDAR's internal UART serial interface to a USB interface. Use an Aux-to-Aux cable to connect RPi to speakers. Due to physical constraints, an LED SHIM is used instead of Blinkt to signal warning messages. While the total cost of the ADAS gadget is just around US$ 150-200, one may have to shell out at least $10-20K more, to get a car model with such advanced features.
Let's imagine, a 3D LIDAR is connected the same way as above. First, we will try to solve 3D LIDAR-Camera Sensor Fusion on the above gadget. Then we will see the variation for 2D LIDAR-Camera Fusion, so as to make it work on RPLIDAR A1.
3D LIDAR-Camera Sensor FusionIt is clear from the above discussion that we need to do rotation, translation, stereo rectification, and intrinsic calibration to project LIDAR points on the image. We will try to apply the above formula based on the custom gadget that we built.
From the above image, you can estimate the Pi Cam is 10 mm below the LIDAR scan plane. i.e. a translation of [0, -10, 0] along the 3D-axis. Consider Velodyne HDL-64E as our 3D LIDAR, which requires 180° rotation to align the coordinate system with Pi Cam. We can compute the R|t matrix now.
As we use a monocular camera here, the stereo rectification matrix will be an identity matrix. We can make the intrinsic calibration matrix based on the hardware spec of Pi Cam V2.
For the RaspberryPi V2 camera,
- Focal Length = 3.04 mm
- Focal Length Pixels = focal length * sx, where sx = real world to pixels ratio
- Focal Length * sx = 3.04mm * (1/ 0.00112 mm per px) = 2714.3 px
Due to a mismatch in shape, the matrices cannot be multiplied. To make it work, we need to transition from Euclidean to Homogeneous coordinates by adding 0's and 1's as the last row or column. After doing the multiplication we need to convert back to Homogeneous coordinates.
You can see the 3DLIDAR-CAM sensor fusion projection output after applying the projection formula on the 3D point cloud. The input sensor data from 360° Velodyne HDL-64E and camera is downloaded [9] and fed in.
However, the 3D LiDAR cost is a barrier to build a cheap solution. We can instead use cheap 2D LiDAR with necessary tweaks, as it only scans a single horizontal line.
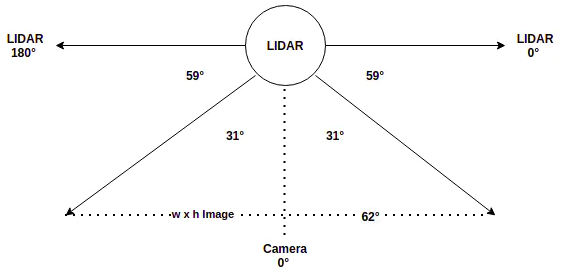
2D LIDAR-Camera Sensor FusionOur gadget is equipped with 2D RP LIDAR A1 to minimize the cost. This LIDAR scans the environment in a 2D plane, orthogonal to the camera plane. The rotating scan will estimate the distance to the obstacle, for each angle from 0° to 360°. Due to the placement of LIDAR w.r.t. Pi Cam in the gadget, the camera is at +90° on the LIDAR geometry. However, note that the Field of View of Pi cam V2 is 62°x48° in horizontal x vertical direction respectively.
The integrated front view of the device is as shown below.
As both the LIDAR and Camera sensor data is available in the frontal 62° arc, we need to fuse the data. In the LIDAR scan plane, the camera data starts from +59° to +59° + 62° = 121°. We can run object detection on the image to get bounding boxes for the objects of interest. Eg: human, car, bike, traffic light, etc. Since 2D LIDAR has only width information, consider only the x_min and x_max of each bounding box.
We need to compute the LIDAR angle corresponding to an image pixel, in order to estimate the distance to the pixel. To find the distance to the object inside the bounding box, compute θ_min and θ_max corresponding to x_min & x_max using the below formula, based on the above diagram,
Now you can find the distance to each angle between θ_min and θ_max based on the latest LIDAR scan data. Then compute the median distance of all LIDAR points that subtends the object bounding box to estimate the object depth. If the distance is below a threshold, then trigger a warning based on the angle. Repeat warning, if the box center shift by a significant distance in subsequent frames.
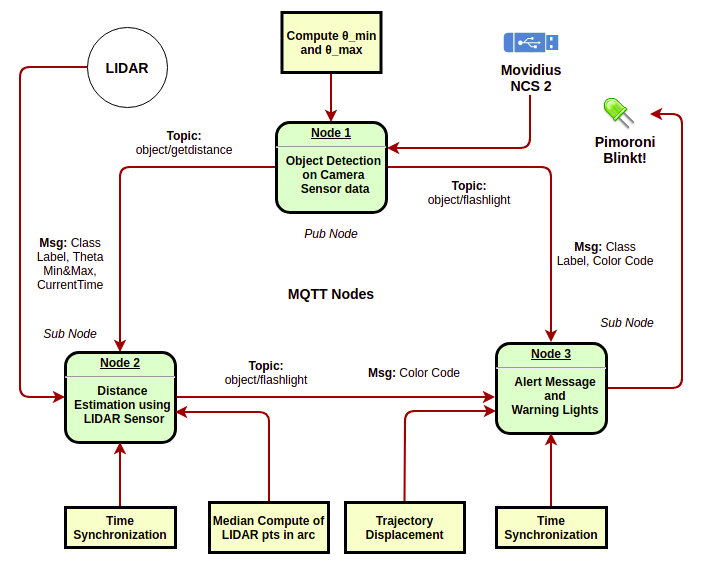
To build a non-blocking system flow, a modular architecture is employed wherein, each independent node is dependent on different hardware components. i.e., the "object detection" node uses Movidius for inference, whereas the "distance estimation" node takes LIDAR data as input, while the "Alert" module signals to Pimoroni Blinkt and the speaker. The modules are communicated via MQTT messages on respective topics.
Architecture DiagramThe time synchronization module takes care of the "data relevance factor" for Sensor Fusion. For ADAS, the location of detected objects by 'Node 1' may change, as the objects move. Thus, the distance estimate to the bounding box could go wrong after 2-3 seconds (while the message can remain in the MQTT queue). In order to synchronize, current time = 60*minutes + seconds is appended to the message (to ignore lagged messages).
Watch the gadget plying the Indian Roads, giving driver-assist alerts after perceiving the surrounding objects, along with their depth and direction.
The speaker is be wired internally or a Bluetooth speaker is to be integrated to make the announcement more audible to the driver.
This ADAS device can be connected to the CAN bus to let it accelerate, steer, or apply the brake. RPi doesn't have a built-in CAN Bus, but its GPIO includes SPI Bus, which is supported by a number of CAN controllers like MCP2515. So, autonomous emergency braking (AEB) and collision avoidance system (CAS) can be done by connecting this device to the CAN bus.
Tweaking for Indian ConditionsThe Indian traffic conundrum is so unique that it demands custom solutions. To start with, we need to train object detection models with Indian vehicles such as trucks, tempos, vans, autos, cycle rickshaws, etc.
Further, to enhance smart surround view, we need to train the model with Indian traffic signs and signboards to give more meaningful driver-assist warnings on Indian roads. It's a common sight in India, the animals like cows, pigs, buffaloes, goats, dogs, etc., cross the roads and highways. Hence, it's beneficial to detect them as well.
For the PoC, see the output of SSD-Mobilenet model trained to classify Indian traffic signs against Indian signboards. You can further classify the traffic sign to decipher the exact meaning of the sign.
The annotated Indian Traffic Sign dataset is provided by Datacluster Labs, India. They are yet to finish the annotation of "Indian Vehicles" database. It's just a matter of training time to make this gadget, tailor-made for India.
To find out the ROI from images, we have used SSD MobileNet trained on COCO filtered by potential objects. To detect only people and vehicles, you can use this model also to get better speed and accuracy. More importantly, the core task of custom object training and its deployment on IoT devices and Android mobiles are handled at depth in Solution #5.
The output of this model is sent from Node 1 to Node 2, where the LiDAR-Camsensor fusion happens, further pushing a message to Node 3. For the system to function, the 3 MQTT nodes should work in tandem, orchestrated by MQTT messages, published, and subscribed on respective topics.
The source code of this solution is available here
Solution #2: Indoor Robot Localization with SLAMRobots replace humans at establishments like hotels and restaurants. But how do they navigate indoors without spatial information about surroundings? If you already have a map, then you know where you are. When there is no map beforehand, then you need to not only generate the map (mapping) but also understand your location on the map (localization). Imagine how hard that can be, even for a human. Then how difficult it can be, for a robot!
SLAM (Simultaneous Localization And Mapping) algorithms use LiDAR and IMU data to simultaneously locate the robot in real-time and generate a coherent map of surrounding landmarks such as buildings, trees, rocks, and other world features, at the same time.
Though a classic chicken and egg problem, it has been approximately solved using methods like Particle Filter, Extended Kalman Filter (EKF), Covariance intersection, and GraphSLAM. SLAM enables accurate mapping where GPS localization is unavailable, such as indoor spaces.
Reasonably so, SLAM is the core algorithm being used in robot navigation, autonomous cars, robotic mapping, virtual reality, augmented reality, etc. If we can do robot localization on RPi then it is easy to make a moving car or walking robot that can ply indoors autonomously.
First, let's discuss GraphSLAM and do a custom implementation. Then we will attempt to integrate RPi with RPLidar A1 M8, running on a 5V 3A battery, and do SLAM along with visualization of the LIDAR point cloud map to assist navigation or even to generate a floor map. Finally, the LIDAR point cloud map is visualized on a remote machine using MQTT.
Assume a robot in the 2D world, tries to move 10 units to the right from x to x'. Due to motion uncertainty, x' = x + 10 may not hold, but it will be a Gaussian centered around x + 10. The Gaussian should peak when x’ approaches x + 10
If x1 is away from x0 by 10 units, the Kalman Filter models the uncertainty using the Gaussian with (x1 – x0 – 10). Hence, there is still a probability associated with locations < 10 and > 10.
There is another similar Gaussian at x2 with a higher spread. The total probability of the entire route is the product of the two Gaussians. We can drop the constants, as we just need to maximize the likelihood of the position x1, given x0. Thus the product of Gaussian becomes the sum of exponent terms, i.e. the constraint has only x’s and sigma.
Graph SLAM models the constraints as System of Linear Equations (SLEs), with a Ω matrix containing the coefficients of the variables and a ξ vector that contains the limiting value of the constraints. Every time an observation is made between 2 poses, a 'local addition' is done on the 4 matrix elements (as the product of gaussian becomes the sum of exponents).
Let's say, the robot moves from x0 to x1 to x2 which are 5 and -4 units apart.
The coefficient of x’s and RHS values are added to corresponding cells. Consider the landmark L0 is at a distance of 9 units from x1.
Once the Ω matrix and ξ vector is filled in like above, compute the equation below to get the best estimates of all the robot locations:
You need to update the values in the 2D Ω matrix and ξ vector, to account for motion and measurement constraints in the x and y directions.
The complete source code and results of Custom SLAM implementation can be found in the IPython notebook here.
Now let's see SLAM in action, deployed on a RaspberryPi with RPLidar A1 M8, running on a 5V 3A battery. As you can see in the video, the portable unit is taken across different rooms of my house and a real-time trajectory is transmitted to the MQTT server and also stored on the SD card of RPi.
You can see the visualization of the LIDAR point cloud map and estimated robot trajectory using PyRoboViz as below.
We can re-route the real-time visualization to a remote machine using MQTT. The robot position, angle, and map can be encoded as a byte array which is decoded at the MQTT client as below.
Note that, the high-dense linear point cloud in the LIDAR maps represents stable obstacles like walls. Hence, we can use algorithms like Hough Transform to find the best fit line on these linear point clouds to generate floor maps.
From 3D LIDAR point cloud, we can even construct a 3D map of surroundings using Structure from Motion techniques,
- Use Detectors such as SIFT, SURF, ORB, Harris to find features like corners, gradients, edges, etc.
- Use Descriptors such as HOG to encode these features.
- Use Matchers such as FLANN to map features across images.
- Use 3D Triangulation to reconstruct a 3D Point Cloud.
We can use the idea of SLAM indoor navigation to deploy an autonomous mobile robot inside closed environments like airports, warehouses, or industrial plants.
The source code of this solution is available here
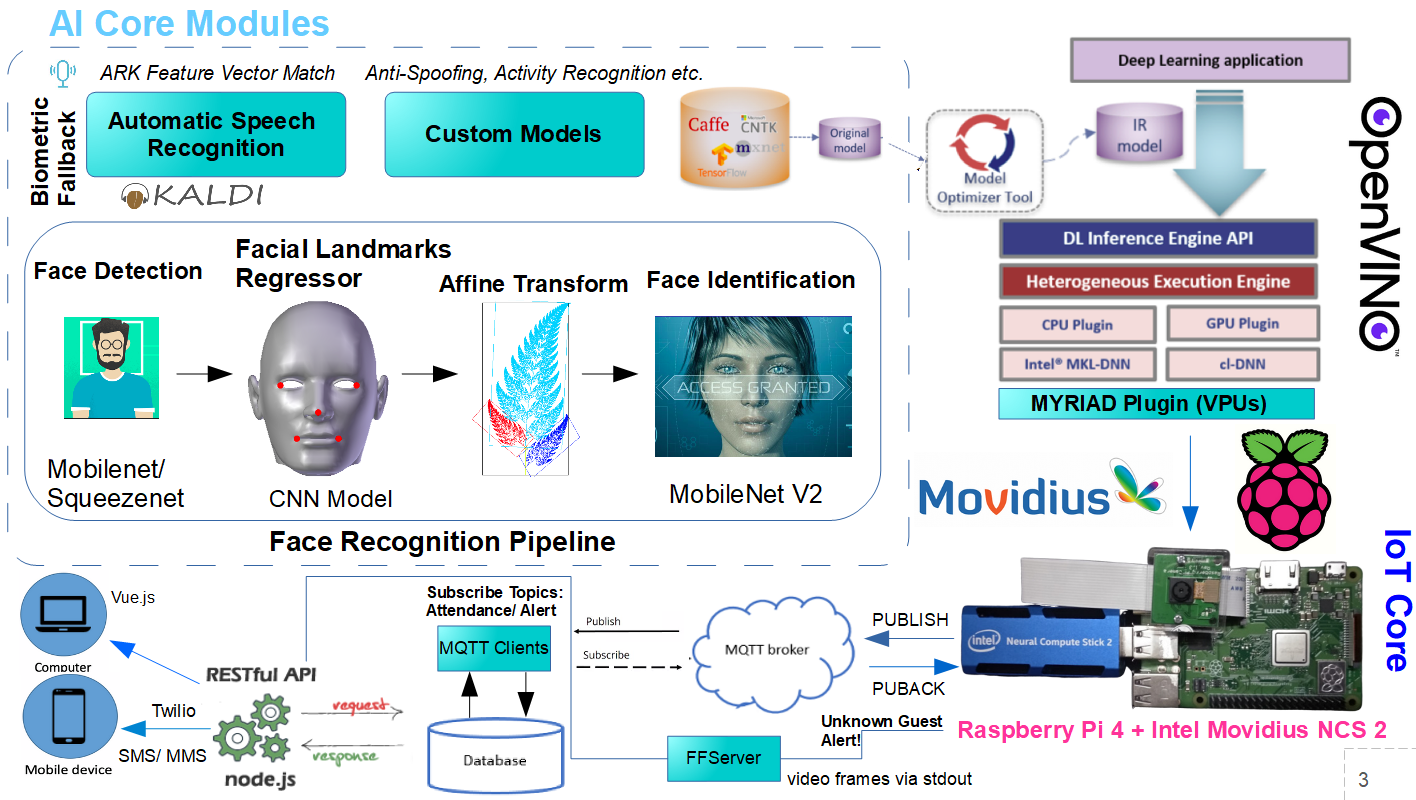
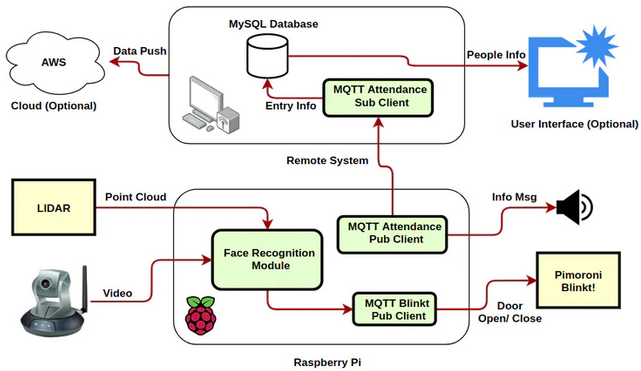
Solution #3: Touch-less Facial Attendance SystemTouch-free interaction of all public devices has become an imperative post-Corona. No wonder, facial recognition-based entry, and attendance gadgets are in much demand to replace attendance registers and bio-metric access control. These embedded devices can be used in big companies, flats, institutions, or even to take class attendance.
Face recognition can be used to identify the person while depth information is required to open the door only to those near the door. Face Recognition based on Deep Learning gives better accuracy than Haar Cascade, LBPH, HOG, or SVM. Depth can be estimated by LIDAR or DepthAI platforms like LUX-OAK-D that can combine depth perception, object detection, and tracking in one SoM. Ultrasonic sensor HC-SR04 can also be used to detect persons near the door.
Four major steps involved in this project are,
1. Localize and identify face (Raspberry Pi + Pi Cam + OpenVINO + Movidius)
2. Publish Identity to the server (Use MQTT Pub-Sub for IoT communication)
3. Persist identity and register attendance (MySQL or AWS)
4. Alert security if the person is unidentified (SMS), else open the door.
We can choose to enhance the alert mechanism by pushing the footage of unidentified persons notified to security via FFmpeg. The SMS messages are pushed via Twilio integration.
During the initial setup, the system should build an image database of known persons. During the registration process, an affine transformation is applied after detecting the facial landmarks of the person, to get the frontal view. These images are saved and later compared, to identify the person.
The face recognition models done in OpenVINO are deployed to RPi, which is integrated with a Pi Cam and LIDAR. If the person is identified and is near to the door, then the 'door open' event is triggered. If someone is near the door but not recognized then a message should be pushed to the security's mobile. This is simulated by flashing 'green' and 'red' lights respectively, on a Pimoroni Blinkt! controlled using MQTT messages.
In order to avoid repeated triggers, the message gets published only when the same person is not found in the last 'n' frames (managed with a double-ended queue). If the person is identified, then the greeting message is pushed via the eSpeak text-to-speech synthesizer. Make sure the voice is properly set up in Pi.
Now let's see the system in action.
Note that the performance is optimal with 20 FPS (no face in frame) and 10-12 FPS (with faces) on a Raspberry Pi 4 with Intel Movidius NCS 2.
We need to find out the distance to the person from the door. This can be estimated by computing the median distance of LIDAR points between two subtending angles, based on LIDAR - Picam position (triangulation)
See the auto-generated entry register database on the MQTT reception side.
We can easily extend the system by pushing the data to the cloud or by building a front end to track or analyze the above data.
Anti-Spoofing Methods:Any access control or attendance system needs to be fake-proof. It's possible to cheat the above system by showing a photo of a registered person. How can we differentiate a real human vs a photo?
We can treat "liveness detection" as a binary classification problem and train a CNN to distinguish real faces from fake ones. But this would be expensive on the edge. Alternatively, we can detect spoofing,
1. In 3D: Using light reflections on the face. Might be overkill on edge devices.
2. In 2D: We can do eyewink detection in 2D images. Feasible on edge devices.
To detect eye winks, it's most efficient to monitor the change in white pixel count around the eye region. But it's not as reliable as monitoring the EAR (Eye Aspect Ratio). If the Eye Aspect Ratio rises and falls periodically then it's a real human, otherwise fake. The rise and fall can be detected by fitting a sigmoid or inverse sigmoid curve.
Instead, we can always use Deep Learning or ML techniques to classify an eye image as open or closed. But it's advisable, in the interest of efficiency, to use a numerical solution when you code for edge devices. See how the spread of non-zero pixels in the histogram takes a sudden dip when an eye is closed.
We can use a parametric curve fit algorithm to fit a sigmoid or inverse sigmoid function at the tail end of the above curve to detect eye open or close events. The person is a real human if any such event occurred.
This project can be used in multiple scenarios driven by a person, event, or custom objects. To explicate, a customized video doorbell can be made to identify a person, event, or vehicle waiting at the door to invoke an SMS, send video or audio message, or even to give an automated response.
The source code of this solution is available here
Solution #4: Smart Cam with Gesture Alarm for SecurityNotwithstanding notable advancements in technology, the developing economies are still trapped in the clutches of patriarchal evils like molestation, rape, or crime against women, in general. Women are often not allowed to stay back in their professional workspaces during late hours, nor are considered safe alone even during day time, especially in the developing world. Imperative, it has become, to enable the other half of population to be more safe & productive. Why not use advancements in technology to arm them with more power?
Imagine a lady who is sitting alone in a clinic, shop, company, or isolated elsewhere needs urgent rescue. She may not have the opportunity or liberty to make a call. The surveillance camera should be smart enough to detect her gestures, be it with hand or objects, as an SOS signal. Based on the object depth, a scaling factor can be computed to magnify the gesture.
Let's evaluate our choices, whether to use image processing, deep learning, or arithmetic algorithms to analyze the incoming video frames from an SoC with a camera, to trigger an alert.
There are 3 main modules for this project,
a) Localize the object, used to trigger the event.
b) Analyze the motion of the object to recognize the signal
c) Deployment on an SoC to install the gadget in the environment.
This is a tricky problem, as we need a cheap solution for easy adoption, but not at the cost of accuracy, as we deal with emergencies here. Similarly, it is easier to detect a custom object but it is more useful to use your own body to signal the emergency. Bearing all this in mind, let's discuss solutions for Localization & Gesture Detection.
A) Object Localization Methods
i) Object Detection
We can use hardware optimized YOLO to detect, say a cell phone, and easily get 5-6 FPS on 4GB Raspberry Pi 4B with Movidius NCS 2. We can train YOLO to detect a custom object such as a hand. But the solution is not ideal as NCS stick will hike up the product price (vanilla YOLO gives hardly 1 FPS on 4GB RPi 4B).
ii) Multi-scale Template Matching
Template Matching is a 2D-convolution-based method for searching and finding the location of a template image, in a larger image. We can make template matching translation-invariant and scale-invariant as well.
- Generate binary mask of template image, using adaptive thresholding. Template image contains objects to be detected.
- Grab the frame from the cam and generate its binary mask
- Generate linearly spaced points between 0 and 1 in a list, x.
- Iteratively resize the input frame by a factor of elements in x.
- Do match template using cv2.matchTemplate.
- Find the location of the matched area and draw a rectangle.
But to detect gesture, which is a sequence of movements of an object, we need stable detection across all frames. Experiments proved hand template multi-scale matching is not so consistent to detect an object in every frame. Moreover, template matching is not ideal if you are trying to match rotated objects or objects that exhibit non-affine transformations.
iii) Object Color Masking using Computer Vision
It is very compute-efficient to create a mask for a particular color to identify the object based on its color. We can then check the size and shape of the contour to confirm the find. It would be prudent to use an object with a distinct color to avoid false positives.
This method is not only highly efficient and accurate but it also paves the way to do gesture recognition using pure mathematical models, making it an ideal solution on the Edge. The demonstration of this method along with mathematical gesture recognition is given down below.
B) Gesture Recognition Techniques
We can define a simple gesture so that is efficient to detect. Let's define the gesture to be circular motion and now we try to detect the same.
i) Auto-Correlated Slope Matching
- Generate ’n’ points along the circumference of a circle, with radius = r
- Compute slopes of the line connecting each point in the sequence,
- Generate point cloud using any of the object localization Methods above. For each frame, add the center of the localized object to the point cloud.
- Compute slopes of the line connecting each point in the sequence.
- Compute correlation of slope curves generated in the above steps.
- Find the index of the maxima of the correlation curve using np.argmax()
- Rotate the point cloud queue by index value for the best match
- Compute circle similarity = 1- cosine distance between point clouds
- If correlation > threshold, then the circle is detected and alert triggered.
Upon implementation, the above algorithm is found working. But in practice, the distance between the localized points varies based on rotation speed and FPS. Another neat and simpler solution would be to use Linear Algebra to check whether the movement of points is convex or concave.
ii) Concavity Estimation using Vector Algebra
If all the vectors in the point cloud are concave, then it represents circular motion.
- Compute the vectors by differencing adjacent points.
- Compute vector length using np.linalg.norm
- Exclude the outlier vectors by defining boundary distribution
- If the distance between points < threshold, then ignore the motion
- Take the cross product of vectors to detect left or right turns.
- If any consecutive value has a different sign, then the direction is changing. Hence, compute a rolling multiplication.
- Find out the location of direction change (where ever indices are negative)
- Compute the variance of negative indices
- If all rolling multiplication values > 0, then motion is circular
- If the variance of negative indices > threshold, then motion is non-circular
- If % of negative values > threshold, then motion is non-circular
- Based on the 3 conditions above, the circular gesture is detected.
From the above discussion, it is clear that we can use Object Color Masking (to detect an object) and use efficient algebra-based concavity estimation (to detect a gesture). If the object is far, then only a small circle would be seen. So we need to scale up the vectors based on object depth, not to miss the gesture. For the purpose of the demo, we will deploy these algorithms on an RPi with a camera and see how it performs.
Now let's see the gesture detection mathematical hack as code.
If a circular motion is detected, then messages are pushed to people concerned and an alarm is triggered. The event trigger is demonstrated by flashing a 'red' light on a Pimoroni Blinkt! signaled using MQTT messages and SMS to mobile using Twilio integration. Watch the project in action.
Above is an efficient and practical solution for gesture detection on edge devices. Please note that you can use any object in place of tennis ball or any gesture other than circular motion. Just that you need to tweak the mathematical formula accordingly. Probably the only downside may be, sensitivity to extreme lighting conditions or the need for an external object (not your body), to trigger the alarm.
To address this drawback, we can also use gesture recognition models optimized by OpenVINOto recognize sign languages and trigger alerts. You can also train a custom gesture of your own, as explained here.
However, some layers of such OpenVINO models are not supported by MYRIAD device as given in the table here. Hence, this module needs to be hosted on a remote server as an API.
Alternatively, we can train the hand gesture classification model and convert it to OpenVINO IR format to deploy on an SoC, as given in "Solution 4". Another trained hand gesture classification model was deployed on Jetson Nano which gave nearly 5 FPS. To conclude, we can consider the vector algebra model to be an efficient, cheap, and generic solution to detect gestures.
The source code of this solution is available here
Solution #5: Indoor Navigation Assist for Blind & ElderlyIt is quite challenging for the blind or elderly to move around, even inside their own house. We can use SLAM techniques demonstrated in Solution #2 to perceive the indoor boundaries or to generate a static floor map to give navigational directions.
However, they need to know more about the things around them in the room. In order to do this, we may have to do custom training with the potential objects and deploy the model on an SoC or SoM. You can even deploy on a mobile, to make the solution most handy. Training can be done with images taken from the same house to maximize detection accuracy.
The hand-held gadget can be made half the size, by directly connecting the NCS2 to Pi and using a USB sound card instead of an external speaker. Nevertheless, it is very handy to use it on your own mobile.
Custom Object DetectionYou can train the object detection model on your local if you have GPU. If not, you can do in EdgeImpulse or Roboflow to host the dataset to Colab. Data cleansing and augmentation are easier done with Roboflow, and you can export the data in multiple formats. Implementation of some object detection models is also given here in roboflow models. Alternatively, you can extend the pre-trained models in OpenVINO model zoo by following the steps here.
Custom Object Detection on PiIt is possible to train an object detection model with your custom annotated data and do hardware optimization using OpenVINO and deploy on Pi, as long as the layers are supported by OpenVINO. By doing so, we can deploy an object detection model on RPi, to locate custom objects.
1. First, choose an efficient object detection model such as SSD-Mobilenet, Efficientdet, Tiny-YOLO, YOLOX, etc which are targeted for low power hardware. I have experimented with all the mentioned models on RPi 4B and SSD-Mobilenet fetched maximum FPS.
2. Do transfer learning of object detection models with your custom data
3. Convert the trained *.pb file to Intermediate representation - *.xml and *.bin using Model Optimizer.
export PATH="<OMZ_dir>/deployment_tools/inference_engine/demos/common/python/:$PATH"
python3 <OMZ_dir>/deployment_tools/model_optimizer/mo_tf.py --input_model <frozen_graph.pb> --reverse_input_channels --output_dir <output_dir> --tensorflow_object_detection_api_pipeline_config <location to ssd_mobilenet_v2_coco.config> --tensorflow_use_custom_operations_config <OMZ_dir>/deployment_tools/model_optimizer/extensions/front/tf/ssd_support_api_v1.14.json
python3 object_detection_demo.py -d CPU -i <input_video> --labels labels.txt -m <location of frozen_inference_graph.xml> -at ssd
4. Finally, deploy the hardware optimized models on Pi.
Custom Object Detection on MobileTo detect a custom object on mobile, we need to follow these steps:
- Data Generation: click images of your object
- Image Annotation: draw bounding boxes manually
- Train & Validate Model: uses transfer learning
- Freeze the Model: for mobile deployment
- Deploy and Run: in mobile
To freeze the model, execute
python models/research/object_detection/export_inference_graph.py -input_type image_tensor -pipeline_config_path data/ssd_mobilenet_v1_custom.config -trained_checkpoint_prefix <model ckpt path> -output_directory object_detection_graph
To deploy the model on mobile,
- Use Android Studio to open this project and update the workspace file with the location and API version of the SDK and NDK.
- Set “def nativeBuildSystem” in build.gradle to ‘none’
- Download quantized Mobilenet-SSD TF Lite model from here and unzip mobilenet_ssd.tflite to assets folder,
- Copy frozen_inference_graph.pb and label_map.pbtxt to the “assets” folder above. Edit the label file to reflect the classes to be identified.
- Update the variables TF_OD_API_MODEL_FILE and TF_OD_API_LABELS_FILE in DetectorActivity.java to the above filenames with prefix “file:///android_asset/”
- Build the bundle as an APK file using Android Studio and install it on your Android mobile. Execute TF-Detect app to start object detection. The mobile camera would turn on and detect objects in real-time.
I have taken 300 images of household chairs, annotated them, and did the above steps to deploy on Android mobile to prove the concept. See the mobile is able to detect generic chairs in real-time.
More classes can be trained to detect using your own mobile and announce via the mobile speaker. In brief, custom object detection on edge devices, along with Solution #2 forms the basis of indoor navigational assistance for the needy. To augment distance alert, it's ideal to use Depth AI platforms like OAK-D by Luxonis, as LIDAR is not so handy.
The source code of this project is available here
Solution #6: Mathematical Hacks for Edge CasesWe can employ clever mathematical hacks to assist or partially replace AI/ML models to make it feasible to run on the Edge. Let me explicate the idea with two useful Edge use-cases.
Soln #6A: Security Barrier Cam using Shape ContextThis idea is not limited to the Security Barrier use case. In an ample number of machine vision problems, we need the robot or gadget to be able to read and behave based on it. But how does a robot read from images?
We can use deep learning techniques like EAST, CRAFT, and PyTesseract to do OCR. But can we do it more efficiently? Yeah, we can do around 15-20x faster using a mathematical descriptor known as Shape Context, which uses log-polar histograms to encode relative shape information.
- Log-polar histogram bins are used to compute & compare shape contexts using Pearson’s chi-squared test [12]
- It captures the angle and distance to randomly sampled (n-1) points of a shape, from the reference point
- To identify an alphabet, find the pointwise correspondences between edges of an alphabet shape and stored base image alphabets. [12]
- To identify an alphabet or numeral, find character contours in an image. Filter out the contours based on size and shape to keep the relevant ones.
- Compare contours with each shape inside the base image. The base image contains all the potential characters, both alphabets, and numerals.
- Find the character with the lowest histogram match score
- Do the above for all character contours, to extract the whole text.
We can use this mathematical technique to efficiently do OCR on machine vision problems. Take the case of a security barrier cam, where the device has to identify the vehicle, from its number plate, when it comes near, to decide whether to open the barrier or not. The proximity of the vehicle can be sensed using an ultrasonic sensor or from the image itself, using a Depth AI device such as OAK-D by Luxonis.
We can use a combination of Deep Learning & Shape Context for this. DL to detect the vehicle and corners of the license plate and Shape Context to recognize the alpha numerals in the license plate. See the OpenVINO model is able to detect the vehicle and license plate as shown below.
- After finding the corners of the license plate, compute the perspective transform matrix and warp the license plate to get a frontal projection.
- Preprocess the frontal image to get ROI and run contour detection. Filter unnecessary contours based on shape and size.
- Apply shape context matching on each contour to identify the alphabets and numerals in the license plate.
See the output of shape context detection on different Indian license plates:
Note that the solution is particularly suitable on the hardware to efficiently read from images. See a real-world implementation of security barrier cam use-case powered by shape context.
Use computer vision to detect the license plate of the approaching car.
However, every solution has pros and cons. While this solution is very fast, it can be error-prone if lighting is not proper. However, given proper conditions, you can even build a multi-lingual OCR on the Edge using Shape Context. The appealing features of this approach are simplicity, speed, and language-agnosticism.
The source code of this project is available here
Soln #6B: Monocular Depth - Social Distance TrackerMonocular Depth Estimation is the idea of estimating scene depth using a single image. We can exploit subtle, visual cues in the image and prior knowledge using deep learning-based techniques.
Inspired from a paper, titled 'Towards Robust Monocular Depth Estimation' [16], a "midasnet" model can be trained to produce a disparity map for a given input image. This is an interesting idea, as we can solve Depth AI use cases by using existing monocular camera installations or where stereo cams are not feasible. This opens up avenues to augment existing camera installations with smart features without any additional cost.
To demonstrate, let's solve a Depth AI use case - Social Distance Monitoring - using monocular images.
a) Feed the input image frames every couple of seconds
b) Fuse the disparity map with the object detection output, similar to visual sensor fusion. More concretely, find the depth of those pixels inside each object bounding box to compute the median to estimate the object depth.
c) Find the centroid of each object bounding box and map the corresponding depth to the object.
d) Across each object in the image, find the depth difference and also (x, y) axis difference. Multiply depth difference with a scaling factor.
e)Use the Pythagoras theorem to compute the Euclidean distance between each bounding box considering depth difference as one axis. The scaling factor for depth needs to be estimated during the initial camera calibration.
Input Image:The people who don't adhere to minimum threshold distance are identified to be violating the social distancing norm, using a monocular camera image.
Since the MYRIAD device doesn't support some layers of the monocular depth estimation model, it needs to be hosted on a remote server as an API. However, as no hardware change is required, this is an ultra-cheap way to augment depth smartness on existing vision installations on the Edge.
Summary: Industry-Grade Problems & SolutionsMany more industry-grade problems can be solved using a combination of the solutions demonstrated above. We can measure the performance of the driver based on feedback from the ADAS-CAS device. This is useful in e-scooter & micro-mobility, not to allow folks to ride rented e-scooters like jerks. Further, the workers in big industrial plants can send commands or request help using the mathematical gesture model and Twilio integration.
More generally, we can use custom object detection to detect any object and automate tasks. For instance, a door access solution to open the door only to in-house pets. Or detect people without a face mask and not open the door. Depth-based collision avoidance is useful to alert workers in the worksite. A very useful industrial solution could be the detection of people not wearing helmets in worksites and give warnings for their safety.
To demonstrate, see the output of YOLOX model trained with this dataset.
YOLOX is a high-performance YOLO, particularly suited for edge as it supports ONNX, TensorRT, and OpenVINO. Hardware optimization of the trained model to OpenVINO model is discussed in Solution #5.
Scores of use cases are there, where we need a machine vision solution to read alphabets and numbers to do a task. We have solved it efficiently with the idea of Shape Context. You can use SLAM indoor navigation to deploy an autonomous buggy inside closed environments like airports, warehouses, or industrial plants. It remains to your creativity to solve more meaningful industrial use cases using the Depth AI solutions demonstrated above.
Power Considerations: Use Case Specific TweaksTo curtail personal cost, it was decided to use the hardware already available at hand, to build solutions. LIDAR was the only device that I had, which can cater to all the above solutions, to add spatial or depth estimates. Moreover, the aim here was to demonstrate the power of Depth AI, with as many use cases as possible.
However, taking an individual use case, proximity sensors may be enough, or Depth AI hardware like Luxonis Oak-D maybe even better, as it can perceive depth as well as do neural inference, at low power. The above solutions can easily be ported to minimize power consumption. Let's discuss the power consumption of the above solutions under various settings.
a) Power Specification of ComponentsFirst, lets look at the power specification of each component used. Based on the measurements by RaspiTV and Pidramble [15] [16], here are some estimates:
- Raspberry Pi Zero (Idle) = 80mA * 5V = 0.4 W[Watts = Voltage x Current]
- Raspberry Pi 2B (Idle) = 220mA * 5V = 1.1 W
- Raspberry Pi 3B (Idle) = 260 mA * 5V = 1.4 W
- Raspberry Pi 4B (Idle) = 540 mA * 5V = 2.7 W
- RPi Zero 1.3 & Pi cam = 180 - 230 mA = 0.9 - 1.1 W (For 720p - 1080p)
- Raspberry Pi 3B and Pi cam = 460 mA * 5 = 2.3 W (To shoot 1080p video)
- Raspberry Pi 4B and Pi cam = 640 mA * 5 = 3.2 W (To shoot 1080p video)
You can drop the frame resolution of Pi Cam to save some power. RPi Cam draws 260 mA to shoot 1080p while only 180 mA for 720p. Raspberry Pi Zero 1.3 with Pi Cam draws only 0.9 W power while 720p video is being shot.
Now consider Movidius NCS and LIDAR,
- Movidius NCS 2 = 180 mA On 5V USB = 0.9 W
Based on RPLIDAR A1 Power Supply Specification [17],
- RPLIDAR A1 M8 = Scanner system + Motor system = 300 + 100 (Work Mode) * Voltage = 400 mA * 5V = 2W
For Door Access Control and Indoor Navigational Assistance use cases, you can usea Proximity Sensor instead of LIDAR.
- HC-SR04 Ultrasonic sensor = 15 mA * 5 = 75mW
- Grove Ultrasonic sensor = 8mA * 5 = 40 mW
For Luxonis OAK-D DepthAI Hardware, the total power consumption usually stays around 800-900ma, with cameras and the DepthAI SoM. The power expense of OpenMV Cam H7 is less than 150 ma andPico4ML is 40 ma in idle mode and 60 ma while running ML models.
b) Power Requirement of SolutionsThe solutions with mathematical hacks are feasible to execute on Raspberry Pi Zero 1.3 at least power cost. It is trivial to port the above solutions across various models of Pi or OAK-D, as it supports OpenVINO and MYRIAD. Even to Depth AI hardware like OpenMV Cam H7 or Pico4ML, it is easy to port some use-cases with serious power gains.
The power requirement of ported, OAK-D, OpenMV Cam & Pico4ML are given under "Ported", "OAK-D", "Open MV", and "Pico4ML" heads respectively.
1) ADAS - Collision Avoidance System on Indian Cars
Better run this on a recent RPi model, as response time is critical here.
- Current: RPi 4B + Cam + Movidius + LIDAR = 3.2 + 0.9 + 2 = 6.1W
- Ported: RPi 3B + Cam + Movidius + LIDAR = 2.3 + 0.9 + 2 = 5.2 W
- OAK-D: RPi 3B + OAK-D = (260 + 800) * 5 = 5.3 W
2) Indoor Robot Localization with SLAM
If no point cloud visualization, it is enough to use Raspberry Pi 2B or 3B.
- Current: RPi 4B + LIDAR = 2.7 + 2 = 4.7W
- Ported: RPi 2B + LIDAR = 1.1 + 2 = 3.2W
3)Touch-less Attendance & Door Access Control
This solution can run on Raspberry Pi Zero 1.3with Movidius, though the frame rate can fall from 12-20 to 4-8 FPS which is decent enough. LIDAR can be replaced with an ultrasonic sensor for depth perception.
OpenMV Cam H7 has Haar Cascade Face Detection, but better to use DL for Face Recognition in a security use case. However, OpenMV Cam is a good alternative as eye-tracking & optical flow is handled in the hardware.
- Current: RPi 3B + Cam + NCS + LIDAR = 2.3 + 0.9 + 2 = 5.2W
- Ported: RPi 0 + Cam + NCS + U-sonic sensor = 80 + 180 + 180 + 8 =2.24 W
- OAK-D: RPi 3B + OAK-D = (260 + 800) * 5 = 5.3 W
4) Indoor Navigational Assistance for Blind & Elderly
This solution can easily be ported to Raspberry Pi 2B but it's ideal to use OAK-D here as it can do depth sensing, object detection, and tracking as well.
- Current: RPi 3B + Cam + Movidius = 2.3 + 0.9 = 3.2W
- OAK-D: RPi 2B + OAK-D = (220 + 800) * 5 = 5 W
5) Smart Cam with Gesture Alarm for Women Security
Our efficient solution based on linear algebra can be executed on Raspberry Pi Zero. However, OpenMV Cam is ideal for this use case, as it can do circle detection, and blob centroid detection based on color, in the hardware. However, you can fetch a huge power gain, if you use Pico4ML itself as the gesture object, as it has an IMU onboard.
- Current: RPi 3B + Cam = 460 mA * 5V = 2.3 W
- Ported: Raspberry Pi Zero 1.3 + Cam = 0.9W
- OpenMV: Less than 150 mA * 5V = 0.75 W
- Pico4ML: 50 mA * 5V = 0.25 W
6) Security Barrier Cam using Shape Context
The mathematical hack based on Shape Context can be executed on Raspberry Pi Zero, by replacing Pearson's chi-squared test with cosine distance to compare log-bin histograms.
- Current: RPi 3B + Cam = 460 mA * 5V = 2.3 W
- Ported: Raspberry Pi Zero 1.3 + Cam = 0.9W
- OAK-D: RPi 2B + OAK-D = (220 + 800) * 5 = 5 W
7) Monocular Social Distance Tracker
The depth inference and distance compute runs on another remote machine.
- Current: RPi 3B + Cam = 460 mA * 5V = 2.3 W
- Ported: Raspberry Pi Zero 1.3 + Cam = 0.9W
8) Worksite Helmet Monitoring
More industrial situations can be handled by adding Depth AI to this solution.
- Current: RPi 3B + Cam + Movidius = 2.3 + 0.9 = 3.2W
- OAK-D: RPi 2B + OAK-D = (220 + 800) * 5 = 5 W
WiFi may be required for some of the solutions above. Note that the Pi further consumes 170 mA when the wifi is turned on. To compensate, you can drop the frame resolution from 1080p to 720p to save nearly 100 mA. So the power expense remains more or less the same.
The speaker is an optional component in most of the use cases, even otherwise you can use a low-power USB speaker or audio HAT like this for sound. The Blinkt and LED SHIM are also optional components. Hence, they are not accounted for in the power expense computations.
c) Uptime Estimation on BatteryLet's try to estimate the uptime of the above implementations on battery, based on the power estimate under "Current" and "Ported" (considered same, as we can use the same code in another Pi model).
Battery uptime depends on the current draw. For 1000 mA current draw, a 10 Ah battery can last 10 hours.
Uptime in Hours = Battery Capacity (mAh) ÷ Current (mA)
Thus, on a 10 Ah battery, the above implementations,
- ADAS - Collision Avoidance System: can run 10 hours
- Indoor Robot Localization with SLAM: can run 15 hours
- Touch-less Attendance & Door Access Control: can run 22 hours
- Indoor Navigational Assistance for Blind & Elderly: can run 15 hours
- Smart Cam with Gesture Alarm for Women Security: can run 55 hours
- Security Barrier Cam using Shape Context: can run 55 hours
- MonocularSocial Distance Tracker: can run 15 hours
For some use cases, the actual up-time can be slightly lesser, as RPi draws more power under work mode. The OAK-D solution variant can last longer in real, as it draws only around 700-800 ma in work mode and much lesser in idle mode. Moreover, neural inference runs on OAK-D, freeing the host device resources.
However, note that both Gesture Cam and Security Barrier solutions qualify for always-on use cases, as they draw the least power, despite doing on-device sensor data analytics. Moreover, Gesture Cam can run 66 hours on OpenMV Cam H7, and around 200 hours on Pico4ML.
However, Pico4ML requires itself to be used to signal gestures, which may not be practical. Hence, OpenMV is the most ideal choice for Gesture Cam because it can do circle detection, and color mask on the hardware itself.
d) Bottomline: Power Considerations- All the above solutions are done as portable battery-operated devices.
- We have replaced ML with Math models to minimize power consumption, thereby fetching 50+ hours for Gesture Cam & Security Barrier solutions.
- For the purpose of integration, the ADAS gadget can be connected to the car battery also, without any noticeable impact on load (5W). But this is not required as the device can run around 10 hours on a single charge.
- We have even seen the deployment of an indoor navigational assistance solution on an Android mobile. The mobile device can last a minimum of 12-24 hours or higher, depending upon the mobile battery.
- We can utilize the low power mode on devices like OpenMVCam, controlled by proximity sensors, to minimize power consumption.
- In terms of power efficiency and ease of use, Depth AI platforms are an awesome device of choice, especially for specific use-cases.
- In the Gesture Cam use case, we have seen Pico4MLachieving the least power usage while OpenMV Cam balances out power efficiency and real-world usage. For security applications also, OpenMV Cam is a suitable choice as it supports frame differencing in hardware
In this project, we have seen the potential of Depth AI, its application across multiple domains along with the solutions, and also the power-efficient tweaks and variations. A unique contribution of this project is the emphasis on mathematical models to assist and augment AI/ML models to efficiently execute on resource and power-constrained environments.
Impact on Sustainable Development Goals (SDGs)- Touch-less Attendance solution has a direct impact on SDG 3 (Good Health and Well Being) as it helps to curb Covid spread. It has an indirect impact on SDG 1 (No Poverty), SDG 2 (No Hunger) &SDG 8 (Economic Growth) as well.
- Indoor Navigational Assistance caters to the well-being of the visually challenged and the elderly. Hence it directly addresses SDG 10 (ReducedInequalities) and SDG 3 (Good Health and Well Being)
- Smart Cam with Gesture Alarm for women security has a direct impact on SDG 5 (Gender Equality) and equality in employment.
- MonocularSocial Distance Tracker also has a direct impact on SDG 3 (Good Health and Well Being) as it helps to prevent Covid spread.
- Both the projects, Indoor Robot Localization and Security Barrier Cam are a contribution towards SDG 9 (Industry and Innovation)
- ADAS: Collision Avoidance System solution is another important contribution to SDG 9 (Industry and Innovation) as it has a direct impact on traffic safety in developing countries.
The source code of the above solutions are spread across 6 repositories:
- ADAS - Collision Avoidance System on Indian Cars: https://github.com/AdroitAnandAI/ADAS-Collision-Avoidance-System-on-Indian-Roads
- Indoor Robot Localization with SLAM: https://github.com/AdroitAnandAI/SLAM-on-Raspberry-Pi
- Touch-less Attendance & Door Access Control: https://github.com/AdroitAnandAI/Facial-Attendance-on-Pi-with-LIDAR
- Indoor Navigational Assistance for Blind & Elderly: https://github.com/AdroitAnandAI/Indoor-Navigational-Assistance-with-RPi-and-Mobile
- Smart Cam with Gesture Alarm: https://github.com/AdroitAnandAI/Gesture-Triggered-Alarm-on-Pi-or-Jetson-Nano
- Security Barrier Cam using Shape Context: https://github.com/AdroitAnandAI/Multilingual-Text-Inversion-Detection-of-Scanned-Images
1. Breezy Implementation of SLAM: https://github.com/simondlevy/BreezySLAM
Note: Have contacted the author, Prof. Simon D. Levy, CSE Dept., Washington and Lee University for LIDAR scan data error in his code, during visualization. I have fixed the code by separating lidar scan code as a separate thread and implemented inter-thread communication and he acknowledged the fix.2. LIDAR Point Cloud Visualization:https://github.com/simondlevy/PyRoboViz
3. Udacity ComputerVision Nanodegree:https://www.udacity.com/course/computer-vision-nanodegree--nd891
4. LIDAR-Camera Sensor Fusion High Level: https://www.thinkautonomous.ai/blog/?p=lidar-and-camera-sensor-fusion-in-self-driving-cars
5. OpenVINO Face Recognition Module:https://docs.openvinotoolkit.org/latest/omz_demos_face_recognition_demo_python.html
6. LIDAR data scan code stub by Adafruit:https://learn.adafruit.com/remote-iot-environmental-sensor/code
7. Book: University Physics I - Classical Mechanics. The Cross Product and Rotational Quantities. https://phys.libretexts.org.
8. Camera Calibration and Intrinsic Matrix Estimation: https://www.cc.gatech.edu/classes/AY2016/cs4476_fall/results/proj3/html/agartia3/index.html
9. Visual Fusion For Autonomous Cars Course at PyImageSearch University: https://www.pyimagesearch.com/pyimagesearch-university/
10. LIDAR Distance Estimation:https://en.wikipedia.org/wiki/Lidar
11. Anand P. V, Karthik K. "Multilingual Text Inversion Detection using Shape Context" IEEE Region 10 Symposium (TENSYMP) 2021
12. Belongie, Serge, Jitendra Malik, and Jan Puzicha. "Shape matching and object recognition using shape contexts." IEEE transactions on pattern analysis and machine intelligence 24.4 (2002): 509-522.
13. RPLIDAR A1 M8 Hardware Specification:https://www.generationrobots.com/media/rplidar-a1m8-360-degree-laser-scanner-development-kit-datasheet-1.pdf
14. Model Training, Data Cleansing & Augmentation:www.roboflow.com
15. Power Consumption: Raspberry Pi, Pi Models & Pi Cam. https://raspi.tv/2019/how-much-power-does-the-pi4b-use-power-measurementshttps://www.pidramble.com/wiki/benchmarks/power-consumption
16. Ranftl, René, et al. "Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer." arXiv:1907.01341 (2019).
Note: The Indian traffic sign model has been trained using the Traffic dataset offered by Datacluster Labs, India.
Touchless Attendance - High Level Diagram
Touchless Attendance - Architecture Diagram
LIDAR-Camera Sensor Fusion


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments