


Embarking on the project, the aim is to create a practical solution for virtual fashion try-ons, harnessing the capabilities of generative AI without the need for extensive computational resources. The focus is on developing an efficient model that’s smart and seamlessly operates with the Jetson Orin, specifically targeting the high-performance Jetson AGX Orin Developer Kit. This endeavor is about making advanced fashion technology accessible and practical for everyday use in retail environments.
Jetson Orin's Role in Advancing EdgeStyle: Near Real-Time Efficiency
Incorporating the Jetson AGX Orin Developer Kit, the EdgeStyle project significantly enhances the virtual try-on experience with near real-time processing speeds. The platform’s prowess in rapid inference is essential for a smooth and responsive user interaction. Opting for local processing not only ensures that privacy is maintained, with all data securely handled in-house, but also positions EdgeStyle as a forward-thinking alternative to the common cloud-based solutions. Moreover, the Developer Kit’s modest power requirement, capped at 50W, epitomizes energy-conscious technology use, laying the groundwork for sustainable advancements in AI.
Building the Dataset
Creating a comprehensive dataset from scratch is no small feat, especially when sticking to free-to-use images and videos. But hey, it's all about making something that not only works but can grow with community input. Think of it as a collaborative art project where everyone's invited to add their own touch.
Training, But Make It Clever
Now, let's talk about the brains of the operation. Training a model like this usually requires some heavy-duty computing power. My approach involves getting creative with a consumer-grade GPU and leveraging pre-trained models to jumpstart this process.
Looking Forward
EdgeStyle is my personal leap into the intersection of fashion and tech, with a mission to keep things practical, fun, and open for everyone. As I piece together the dataset and refine the training process, I'm reminded that this is just the beginning. There's a whole world of possibilities out there, and I'm just one person, excited to explore them and share the journey with you.
Demo Quick GuideFor an optimal demo experience, it's recommended to upgrade your setup by installing an M.2 NVMe SSD. This enhancement significantly improves performance, especially when relocating the Docker root directory onto it. Such a setup ensures that you can run the demo smoothly, leveraging the full potential of the technology.
The simplest way to launch the EdgeStyle demo is through Docker, utilizing the Jetson's powerful NVIDIA runtime. Execute the following command in your terminal:
docker run --runtime nvidia -it --rm --network=host --rm andreiciobanu1984/edgestyle:latestThis command pulls the latest version of the EdgeStyle app and runs it on your system, providing immediate access to its features.
Accessing the Application:
Once the app is loaded, it can be accessed via any web browser. Simply navigate to: http://127.0.0.1:7860/
Upload three images: one of your subject and the others of people modeling the clothing you want to try on. The app extracts pose data and isolates the individuals and garments. Normally, 20-25 processing steps suffice. The 'Realistic_Vision_V5.1' model performs optimally with a guidance scale between 3-7. The higher you set this scale, the more creative freedom the EdgeStyle model has in generating the images.
Building Your Own Docker Image:
For those interested in customizing or extending the demo, including integrating your own fine-tuned models, a Dockerfile is provided for building your own image.
Dataset creationChoosing free-to-use images and videos for the dataset is really about keeping things accessible and ethical. I'm sticking with resources that anyone can use because it feels right to build this project on a foundation that respects creators and invites everyone to contribute. It's a small step towards being more inclusive and making sure I'm doing my bit to respect the hard work of others. Plus, it's a way to encourage a spirit of sharing and creativity in the tech world, showing that it's possible to innovate while still being mindful of the rules and respectful of community values.
- Step 1: Image Extraction from Videos
Starting with videos from a free-to-use platform like Pexels, I'll mine them for a series of images. This initial extraction transforms dynamic footage into static snapshots, setting the stage for more focused analysis.
- Step 2: Initial Filtering with YOLOv5
Using YOLOv5, a cutting-edge object detection model, I'll sift through the extracted images to pick out those featuring a person. The focus here is on images where the person is prominent enough, ensuring clarity and relevance for subsequent steps.
- Step 3: Refinement with OpenPose
OpenPose comes into play to refine our selection further, focusing on images where the subject's head, shoulders, and hips are clearly visible. This step is crucial for maintaining consistency in pose analysis. Alongside, I'll generate a corresponding OpenPose image for each, laying the groundwork for understanding body positions.
- Step 4: Background Removal and Subject/Clothes Segmentation
Next, I'll strip the backgrounds from these images, isolating the subject. This process also involves creating variants of the images: one set with the clothes masked (leaving the subject) and another with the subject masked (leaving the clothes). This dual perspective is vital for the model to learn the intricacies of clothing and body interaction.
- Step 5: Quality Filtering with CLIP Image Quality Assessment
The CLIP Image Quality Assessment from the torchmetrics library provides an additional layer of filtering, ensuring only high-quality images proceed. This step guarantees the dataset's integrity, focusing on clarity and composition to aid the model's learning process.
- Step 6: Pairing with Diversity in Mind
Finally, to construct the dataset, I'll use a CLIP-based ViT model to curate pairs of images. The goal is to balance diversity and consistency, ensuring pairs show the same subject in the same clothes but different poses. This step is crucial for teaching the model about various body positions while maintaining garment and subject identity.
The outcome? A dataset featuring pairs of images where subjects, adorned in identical attire, showcase different poses. This dataset is designed to train the model to understand and generate images where it can accurately overlay clothes on a target pose based on a reference pose, clothes, and the OpenPose data.
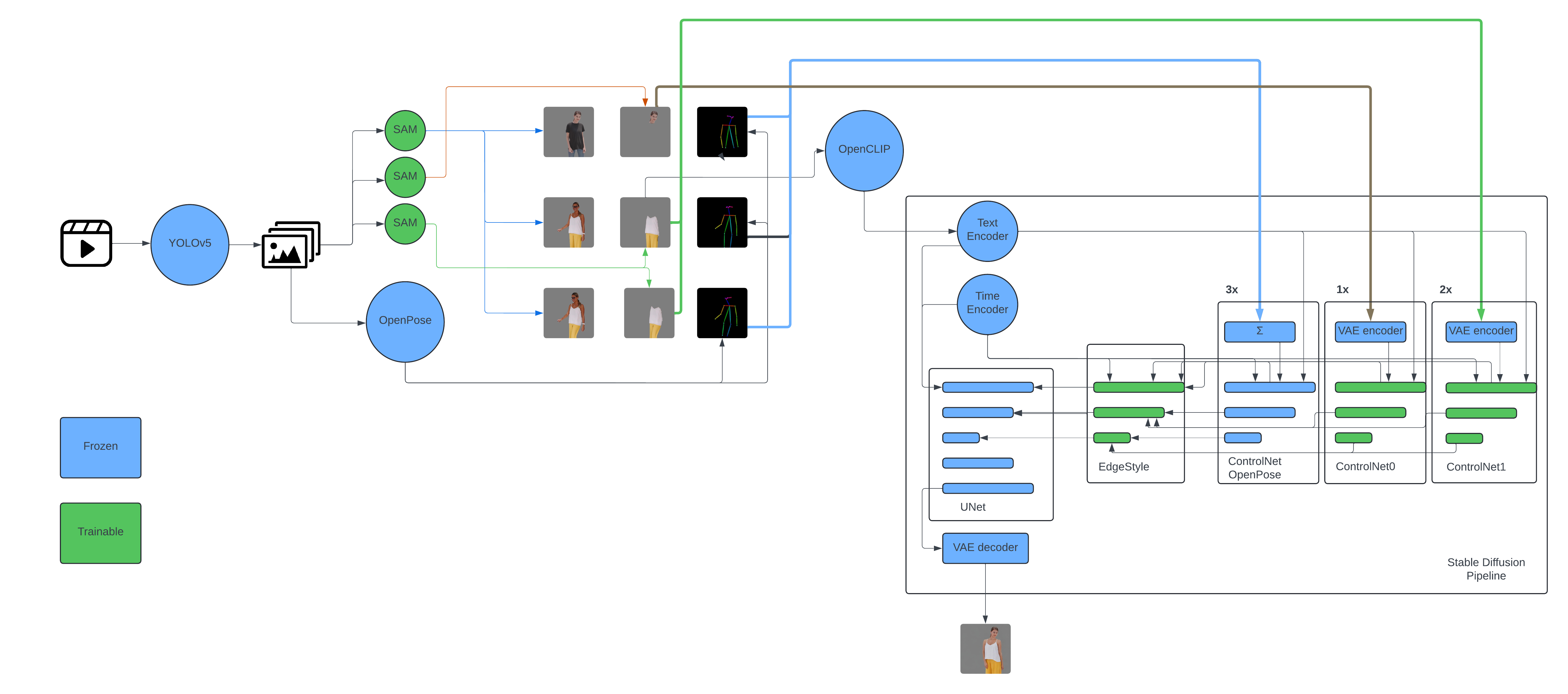
Training the model leverages the strength of multiple ControlNets in conjunction with a frozen U-Net from the Stable Diffusion framework. Here's a more concise rundown:
Training ProcessWithin the Stable Diffusion framework, I train six ControlNets together, using images marked by green squares from the preprocessing pipeline as inputs. These inputs include the subject with clothes, the subject with clothes masked, and the clothes with the subject masked, alongside their OpenPose counterparts. The ControlNets are the trainable part of the equation, tasked with the heavy lifting of learning the mapping between different poses and the associated clothing.
The U-Net in Stable Diffusion acts as a constant in this process. It remains frozen, meaning its parameters do not change during training, ensuring that any improvements in the model's performance are attributable solely to the ControlNets' adjustments.
By iterating over this process and continually adjusting the ControlNets based on their output compared to the ground truth images of fully clothed subjects, the EdgeStyle model hones its ability to predict and generate accurate virtual try-on images.
The aim is a model that can be efficiently executed on edge devices, with the ability to seamlessly render realistic virtual try-ons, adapting clothing to various body poses as interpreted by OpenPose.
EdgeStyle Model OptimizationsInstead of managing separate ControlNets for each type of input image, I've consolidated the approach to use three distinct types of ControlNets:
- OpenPose ControlNet: Utilized in triplicate, this single ControlNet type processes the OpenPose data. For these, I've adopted a pretrained model from Hugging Face's model repository, which is specifically tuned for OpenPose input handling within the Stable Diffusion framework. By using this pretrained ControlNet, I capitalize on its pre-existing knowledge, significantly speeding up the training process for these components.
- Clothing ControlNet: I employ two copies of another ControlNet dedicated to handling images of clothing. These networks are tasked with understanding the clothing's texture, shape, and form, independent of the body.
- Subject ControlNet: A single ControlNet is used to process images of the subject with the clothing masked. This network is essential for learning the nuances of the human form without the distraction of clothing.
For the OpenPose ControlNets, leveraging a pretrained model not only saves time but also resources, as it avoids the need to learn from scratch what has already been efficiently encoded. On the other hand, the remaining ControlNets for clothing and the subject are trained from the ground up to ensure they're closely tailored to the specificities of the dataset and task at hand.
Through this targeted approach, employing both pretrained and fresh ControlNets, I aim to create an efficient training workflow that maximizes the EdgeStyle model's ability to accurately generate virtual try-on images, minimizing the computational load where possible.
Feature Combination with CNNIn the EdgeStyle project, the standard approach of simply adding features from multiple ControlNets at each layer of the U-Net—typical in Hugging Face's diffusers library—needed a rework. Due to the utilization of pretrained OpenPoseControlNets, a more nuanced method was necessary to combine the extracted features effectively.
To address this, I incorporated a small, trainable convolutional neural network (CNN) with the following characteristics:
- Layer Structure: The CNN comprises three layers, adding depth to the feature processing and allowing for more complex interactions between the features.
- Kernel Size: I employed a 1x1 convolution kernel size. This choice is significant because it means that the convolution operates on each point independently across the depth of the feature map.
- Grouping: A key optimization is the use of grouped convolutions. The grouping parameter is set to match the number of channels in each layer, which has an intriguing effect: the first layer effectively performs a weighted sum of the features for each channel.
- Introducing Non-linearity: The subsequent layers introduce non-linearity, an essential aspect of deep learning models that allows them to capture complex patterns and relationships in the data.
Significance of This Approach
By passing the features through this tailored CNN, the model gains several advantages:
- Differentiated Feature Treatment: Even if some ControlNets are identical, such as the pretrained OpenPose ones, their outputs can be processed distinctly, ensuring a more diverse and rich set of features for the U-Net to work with.
- Weighted Feature Integration: The first CNN layer's behavior as a weighted sum means that each channel's contribution can be adjusted, fine-tuning how features from different ControlNets influence the final output.
- Enhanced Learning Capacity: The additional layers provide the model with the ability to learn more complex, non-linear combinations of features, which is vital for the detailed task of virtual try-on image generation.
Incorporating this CNN allows for a more sophisticated merging of features from multiple ControlNets, which is particularly beneficial given the similarities between the copies of the pretrained networks. This innovation ensures that the EdgeStyle model can effectively learn from and differentiate between the nuances of each ControlNet's output, paving the way for generating more accurate and realistic virtual try-on images.
Modifications to Trainable ControlNetsBefore diving into the application of LoRA in EdgeStyle, let me explain what LoRA, or Low-Rank Adaptation, actually is. Essentially, is a technique that fine-tunes pre-trained deep learning models in a more efficient manner. By making minor, strategic tweaks to a small subset of the model's weights, LoRA allows for significant improvements without the need for extensive retraining. This method is especially useful because it updates the model's parameters in a way that enhances its performance while keeping the computational demands manageable. In the context of EdgeStyle, applying LoRA means we can refine our models to better handle the complexities of virtual try-ons without bogging down the system with heavy computational loads. It's like giving the model a quick but effective tune-up, ensuring it runs smoothly and efficiently for its specific task.
- Implementation of LoRA:LoRA, which stands for Low-Rank Adaptation, is a technique used to adapt pre-trained deep learning models while minimizing additional computational costs. In EdgeStyle's ControlNets, LoRA with a rank of 32 is applied. This method effectively updates a small subset of the model's weights, which dramatically reduces the memory footprint without compromising the learning capacity. By confining the adjustments to low-rank matrices, the model retains its performance efficacy while being more memory-efficient.
- Removal of Initial CNN Layers: Typically, a ControlNet would contain initial convolutional layers that downsample the input image to a lower-resolution latent space. However, in EdgeStyle, these layers are omitted. Instead of constructing new downsampling layers from scratch, the encoder from Stable Diffusion's Variational Autoencoder (VAE) is repurposed.
- Integration with VAE Encoder: By harnessing the encoder of the VAE, the ControlNets benefit in two significant ways. First, they save on the memory and computational expense of training additional convolutional layers. Second, and more importantly, they utilize the VAE's proficiency in compressing high-resolution images into a rich latent space that retains a significant amount of detail. This allows the ControlNets to operate on a more detailed representation of the image, capturing nuances that would otherwise be lost in a traditional downsampling process.
Impact on Training and Performance
The integration of LoRA and the reuse of the VAE encoder enables the trainable ControlNets to operate with greater efficiency and a finer understanding of image details. These optimizations are expected to:
- Reduce the computational load, allowing for training on hardware with limited memory, like consumer-grade GPUs.
- Enhance the model's ability to learn detailed representations, potentially leading to more accurate and higher-quality virtual try-ons.
By implementing these changes, EdgeStyle's trainable ControlNets are optimized for performance, enabling the learning of intricate details within the constraints of available hardware. This tailored approach underscores the project's commitment to innovation and practicality in developing accessible virtual fashion technology.
Gradient Accumulation with Accelerate and DiffusersUtilizing the accelerate and diffusers libraries from Hugging Face, I implement gradient accumulation to overcome the VRAM constraints. Although the GPU can only physically handle a batch size of two, gradient accumulation allows me to virtually extend this batch size to 64. This is done by running multiple forward and backward passes without updating the model parameters, and then, after these passes accumulate gradients equivalent to a batch size of 64, updating the model. This technique is essential for simulating the effects of larger batch sizes, which can lead to more stable and robust training.
Switching to Prodigy Optimizer
Instead of the commonly used AdamW optimizer, I opt for Prodigy, an adaptive optimizer. Prodigy is particularly known for its efficient convergence. This choice is critical in a resource-constrained environment as it significantly reduces the time required to reach optimal model performance.
Training Efficiency Gains
By leveraging both gradient accumulation and Prodigy, the training process for EdgeStyle becomes more feasible and efficient on the available hardware. This approach provides the following advantages:
- Simulation of Larger Batch Sizes: The use of gradient accumulation makes it possible to reap the benefits of larger batch sizes, such as improved gradient estimates, without needing the corresponding VRAM that would typically be required.
- Enhanced Convergence: With Prodigy's adaptive optimization, the training script capitalizes on faster convergence, meaning that the model can learn and adapt more quickly to the dataset, enhancing the overall training efficiency.
- Resource Optimization: These techniques combined ensure that the training process is both time-efficient and resource-optimized, making the best use of the available 24 GB of VRAM on a consumer GPU.
For the EdgeStyle project, instead of starting with the base Stable Diffusion model weights, we're taking a different approach by leveraging a community-developed model, SG161222/Realistic_Vision_V5.1_noVAE. This particular model has been fine-tuned to generate realistic images of people, making it an ideal foundation for our virtual try-on system. Its enhanced capabilities for creating lifelike representations of human subjects promise to significantly improve the quality and realism of the virtual try-ons produced by EdgeStyle.
SAMFor EdgeStyle, the segmentation task is crucial for distinguishing between the subject, clothes, and the subject with clothes masked. To achieve this, I utilized multiple fine-tuned versions of the Segment Anything Model (SAM). Specifically, the fine-tuning was applied to the mask decoder part of SAM, tailored for each of the segmentation needs: extracting the subject, the clothes, and the subject with clothes masked. This precise segmentation is vital for the subsequent steps in the virtual try-on process.
Rather than relying on the larger, standard SAM model, I opted for an optimized version known as efficientvit, available from MIT Han Lab's EfficientViT. This choice was driven by the need for speed and efficiency, particularly given the computational constraints of the Jetson Orin device. EfficientViT is designed to offer faster performance without compromising the quality of the segmentation results, making it an ideal fit for EdgeStyle's requirements.
For the training data necessary to fine-tune the SAM models, I turned to the "mattmdjaga/human_parsing_dataset" from Hugging Face. This dataset provides a comprehensive collection of images suitable for training models to understand and segment human subjects and their clothing, supporting the development of finely-tuned SAM models for EdgeStyle. This strategic selection of tools and resources ensures that EdgeStyle can efficiently and accurately process images for virtual try-on applications, even on hardware with limited computational power.
Source CodeSAM
The EdgeStyle project includes a series of SAM (Segment Anything Model) training scripts aimed at fine-tuning the model for specific segmentation tasks. Each script is tailored to a particular aspect of the segmentation process, crucial for the virtual try-on application. Here's a brief overview of each script and its purpose:
- segmenter_training_subject.py: This script fine-tunes the SAM model to focus on segmenting the subject from the background. This is fundamental for accurately identifying the person in the image, which is the first step in the virtual try-on process.
- segmenter_training_head.py: Dedicated to the segmentation of the head, this script fine-tunes the SAM model to recognize and isolate the head portion of the subject. Precise head segmentation is essential for applications that might require adjusting or adding accessories in virtual try-ons.
- segmenter_training_clothes.py: This script specializes in the segmentation of clothes on the subject. By fine-tuning the SAM model to distinguish different clothing items, it lays the groundwork for virtual garment fitting and swapping.
- segmenter_training_body.py: Focuses on the body segmentation excluding the clothes, this script is crucial for understanding the subject's body shape and posture, which is vital for accurately overlaying clothes in virtual try-ons.
The source code for EfficientViT, utilized across these scripts for its optimized performance on segmentation tasks, was adapted and integrated into the EdgeStyle project. It's available in the project directory here. Modifications were made to ensure compatibility with Python 3.8, aligning with the requirements of JetPack 5.1 - the version running on the Jetson Orin device I have. These adaptations were crucial for leveraging EfficientViT's capabilities within the computational constraints and specific software environment of the Jetson Orin.
Dataset Extraction
The script located at extract_dataset.pyis responsible for extracting images from the videos to form the base of the dataset. This involves selecting frames that are suitable for training, including those that clearly show the subject, the clothes, and the necessary poses for the virtual try-on. This step is foundational, as it sets up the raw material from which the virtual try-on model learns.
Creation of Image Pairs
After the initial dataset is extracted, the next critical step is organizing this data into a structured form that is conducive to training the virtual try-on model. This is where dataset_local.pycomes into play. This script takes the segmented images and organizes them into pairs according to the requirements outlined for training. This includes pairing images of the subject in different poses with corresponding clothing items, ensuring that there is a consistent reference for the model to learn from. This step is vital for training the model to understand how different clothing items should look on different poses.
These two scripts, extract_dataset.py and dataset_local.py, work together to convert raw video data into a structured dataset optimized for training the EdgeStyle model. By carefully extracting, segmenting, and pairing images, they lay the groundwork for a model that can accurately perform virtual try-ons, ensuring the system has a solid foundation of data to learn from.
Training script
The training of the ControlNets for EdgeStyle is orchestrated through a specialized script, train_text2image_pretrained_openpose.py. This script is set up to utilize a combination of pretrained models and specific training parameters to fine-tune the ControlNets for the task of generating realistic virtual try-on images.
To initiate the training process, run:
accelerate launch train_text2image_pretrained_openpose.py \
--pretrained_model_name_or_path="SG161222/Realistic_Vision_V5.1_noVAE" \
--pretrained_vae_name_or_path="stabilityai/sd-vae-ft-mse" \
--pretrained_openpose_name_or_path="lllyasviel/control_v11p_sd15_openpose" \
--output_dir="models/output_text2image_pretrained_openpose" \
--resolution=512 \
--train_batch_size=2 \
--gradient_accumulation_steps 32 \
--mixed_precision fp16 \
--controllora_use_vae \
--seed=42 \
--resume_from_checkpoint latest \
--num_validation_images 4 \
--checkpoints_total_limit 3 \
--dataloader_num_workers 2 \
--snr_gamma=5.0 \
--optimizer="prodigy" \
--learning_rate=1.0 \
--prodigy_safeguard_warmup=True \
--prodigy_use_bias_correction=True \
--adam_beta1=0.9 \
--adam_beta2=0.99 \
--adam_weight_decay=0.01 \
--proportion_empty_prompts=0.1 \
--proportion_empty_images=0.1 \
--proportion_cutout_images=0.1 \
--proportion_patchworked_images=0.1 \
--proportion_patchworks=0.1 \
--validation_steps 100 \
--checkpointing_steps 100 \
--max_train_steps=50000- --pretrained_model_name_or_path: Identifies the base model from which training begins, ensuring the model benefits from prior knowledge.
- --pretrained_vae_name_or_path: Specifies the Variational AutoEncoder (VAE) model used, a cornerstone for generating high-quality images.
- --pretrained_openpose_name_or_path: Points to a specialized ControlNet model pre-trained with OpenPose data, crucial for generating images that accurately mimic human poses.
- --output_dir: Directs where the training output, including models and logs, is stored.
Training and Optimization
- --resolution, --train_batch_size, and --gradient_accumulation_steps manage the basic setup for training, focusing on image resolution and batch processing sizes. The use of gradient accumulation is a smart trick to handle larger batches than the hardware might directly support, improving efficiency.
- --mixed_precision: Employs mixed precision training, balancing speed and memory efficiency without compromising the model's performance.
- --optimizer: Chooses "Prodigy" an optimizer known for its efficient convergence.
Data Augmentation
Data augmentation parameters represent a nuanced approach to expanding the variety and quality of training data without physically increasing its volume:
- --proportion_empty_prompts: By introducing a portion of empty prompts, the model learns to generate content in the absence of textual guidance, enhancing its versatility.
- --proportion_empty_images: Introduces scenarios where the model must deal with empty visual information.
- --proportion_cutout_images: This simulates partial occlusions or missing sections in source images, further challenging the model to understand and reconstruct the full context.
- --proportion_patchworked_images and --proportion_patchworks: These parameters introduce complexity by adding or modifying image parts with patchworks, teaching the model to maintain consistency and coherence in diverse and challenging conditions.
Training Details
tensorboard --logdir models/output_text2image_pretrained_openpose/logs/The first row displays the ground truth alongside three images utilized by the ControlNets, with the OpenPose data not shown for clarity. The second row unveils four predictions generated at varying guidance scales.
- Total steps: 50, 000.
- Approximate time to complete on a single GPU (RTX 3090): 330 hours.
- Approximate halved time if run on a RTX 4090: 165 hours.
Cost Analysis (cheapest rate found on runpod.io)
- RTX 3090 cost per hour: $0.26.
- RTX 4090 cost per hour: $0.54.
- Total training cost on RTX 3090: ~$85.
Additional Time
- Dataset extraction duration: 10 hours.
docker run --runtime nvidia -it --rm --network=host --rm andreiciobanu1984/edgestyle:latest- Download EfficientViT-L2-SAM Checkpoints
Obtain the EfficientViT-L2-SAM checkpoint file from one of the following sources: Directly from Hugging Face: EfficientViT-L2-SAM or from project's repository on Hugging Face: EdgeStyle SAM
File structure:
efficientvit/assets/checkpoints/sam/l2.pt
efficientvit/assets/checkpoints/sam/trained_model_subject.pt
efficientvit/assets/checkpoints/sam/trained_model_body.pt
efficientvit/assets/checkpoints/sam/trained_model_clothes.pt
efficientvit/assets/checkpoints/sam/trained_model_head.pt- Check the L4T Version
To ensure compatibility, confirm the L4T version by running:
cat /etc/nv_tegra_release
# R35 (release), REVISION: 2.1- Install PyTorch and Torchvision
Follow the instructions from the NVIDIA Developer Forums to install PyTorch and Torchvision suitable for the Jetson platform. This typically includes finding the pre-built wheels that match your Jetson's CUDA version.
- Install CMake
The updated version of CMake is required for various building processes:
sudo apt-get install libssl-dev
wget https://github.com/Kitware/CMake/releases/download/v3.28.3/cmake-3.28.3.tar.gz
tar zxf cmake-3.28.3.tar.gz
cd cmake-3.28.3/
./bootstrap
make -j$(nproc)
sudo make install- Upgrade setuptools and Install Dependencies
Some Python packages may require the latest setuptools, and other dependencies can be installed from a requirements file:
pip3 install --upgrade setuptools
pip3 install -r requirements-jetson.txt- Install Git LFS
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash sudo apt-get install
git-lfs git lfs install- Download the Models
Clone the necessary model repositories from Hugging Face:
mkdir -p models
cd models
git clone https://huggingface.co/andrei-ace/EdgeStyle
git clone https://huggingface.co/SG161222/Realistic_Vision_V5.1_noVAE
git clone https://huggingface.co/stabilityai/sd-vae-ft-mse
git clone https://huggingface.co/lllyasviel/control_v11p_sd15_openpose
git clone https://huggingface.co/openai/clip-vit-large-patch14- Run the Demo Application
python3 app.pyTo get started with ONNX on your Jetson Orin, install the ONNX runtime with GPU support by following the instructions on the Jetson Zoo. This involves downloading the pre-built wheel and installing it using pip:
wget https://nvidia.box.com/shared/static/mvdcltm9ewdy2d5nurkiqorofz1s53ww.whl -O onnxruntime_gpu-1.15.1-cp38-cp38-linux_aarch64.whl
pip3 install onnxruntime_gpu-1.15.1-cp38-cp38-linux_aarch64.whl
python3 -m pip install onnx_graphsurgeon --index-url https://pypi.ngc.nvidia.comExporting Models to ONNX
When it comes to exporting models to ONNX format, the optimum-cli tool can be used for models that are compatible with the Optimum library. Additionally, custom script export_onnx.py:
cd models
optimum-cli export onnx -m ./clip-vit-large-patch14/ --task image-to-text clip-vit-large-patch14-onnx
optimum-cli export onnx -m ./Realistic_Vision_V5.1_noVAE/ --task stable-diffusion Realistic_Vision_V5.1_noVAE-onnx
python3 export_onnx.pyChallenges with LayerNorm and Accuracy Loss
After dedicating two weeks to training the model, I decided against proceeding with the ONNX transformation. The primary issue appeared to be the torch.nn.LayerNorm layers, which not only contributed to significant accuracy losses during the conversion process but also encountered problems when interfaced with TensorrtExecutionProvider, as the shape could not be accurately inferred by the onnxruntime.tools.symbolic_shape_infer script. Given these challenges and the considerable time already invested in training, I opted not to pursue further efforts in exporting to ONNX.
AssertionError:
Not equal to tolerance rtol=0.001, atol=1e-05
Mismatched elements: 5841 / 32768 (17.8%)
Max absolute difference: 0.00092185
Max relative difference: 103.04526
x: array([[[[ 1.31208 , -1.244555, 1.00645 , ..., 0.53056 , -0.263657,
0.577149],
[-0.548291, 0.613406, 0.165211, ..., 0.237761, -0.388499,...
y: array([[[[ 1.311924, -1.244697, 1.006474, ..., 0.530382, -0.263636,
0.577266],
[-0.548179, 0.613441, 0.165163, ..., 0.237911, -0.388577,...- Dataset: https://huggingface.co/datasets/andrei-ace/EdgeStyle
- Models: https://huggingface.co/andrei-ace/EdgeStyle
- GitHub repository: https://github.com/andrei-ace/EdgeStyle/
- Docker registry: https://hub.docker.com/r/andreiciobanu1984/edgestyle
Reflecting on the journey of developing EdgeStyle, several key insights and learnings stand out. Each decision and challenge faced along the way has not only shaped the project but also provided valuable lessons for future endeavors.
- Reconsidering LayerNorm: The choice to use torch.nn.LayerNorm in the model architecture, while beneficial for training dynamics, ultimately posed significant challenges during the ONNX export process. In hindsight, exploring alternative normalization techniques that align more closely with ONNX compatibility would have likely smoothed the path to deployment without compromising model performance.
- Adaptive Learning Rate Adjustments: The implementation of an adaptive learning rate, though intended to optimize the training process, introduced unexpected artifacts in the model's outputs. This experience underscores the delicate balance required in tuning learning rates—too high, and the model may fail to converge on the most accurate representations. Future projects would benefit from a more cautious approach to adjusting learning rates, potentially incorporating more dynamic or conditional scaling mechanisms.
- The Importance of Data: As with many machine learning endeavors, the quantity and quality of data play a crucial role in the success of the model. The EdgeStyle project further confirmed this, highlighting areas where additional data could have enriched the training process and led to more robust outcomes. Expanding the dataset, either through augmentation or the incorporation of more diverse sources, remains a priority for enhancing the model's accuracy and generalizability.
In sum, the development of EdgeStyle has been a journey filled with both accomplishments and areas for growth. Each challenge encountered along the way has provided valuable lessons, shaping the direction of future projects.
Acknowledgments- https://www.pexels.com/
- https://github.com/mit-han-lab/efficientvit
- https://github.com/ultralytics/yolov5
- https://huggingface.co/docs/diffusers/en/index
- https://www.jetson-ai-lab.com/
- https://github.com/dusty-nv/jetson-containers
- https://github.com/HighCWu/control-lora-v2
- https://huggingface.co/SG161222/Realistic_Vision_V5.1_noVAE
- https://github.com/lllyasviel/ControlNet
- https://huggingface.co/datasets/mattmdjaga/human_parsing_dataset
- https://github.com/konstmish/prodigy







{kind=link}
Comments