



Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
 |
| |||||
 |
| |||||
More than 300 million people in the world suffer from depression[1]. Journaling has been suggested as a potential help to manage stress, reduce anxiety and, in general, cope with depression[2]. Journaling has been demonstrated positive also in the cases of stressful events and symptoms that can accompany trauma[3]. In general, we can say that journaling can have very positive outcomes for the quality of life of millions of people suffering from such mental health conditions. Smart Journal is focused on this, in providing a proof of concept of a digitally enabled solution for journaling.
ObjectiveStarting from the idea mentioned above, the objective is twofold: on the one hand, the objective is to try to develop a proof of concept of the components that could be included in a smart journal. On the other hand, to test the AI Kit, demonstrate its features and show its possibilities.
This, among other things, means to use the AI Studio, check the Thundercomm AI Kit Face Detection & Face Recognition capabilities, do Speech-to-Text recognition, perform a sentiment analysis (using Tensorflow), and even use the Text-to-Speech capabilities of the Android operating system included in the Ai Kit.
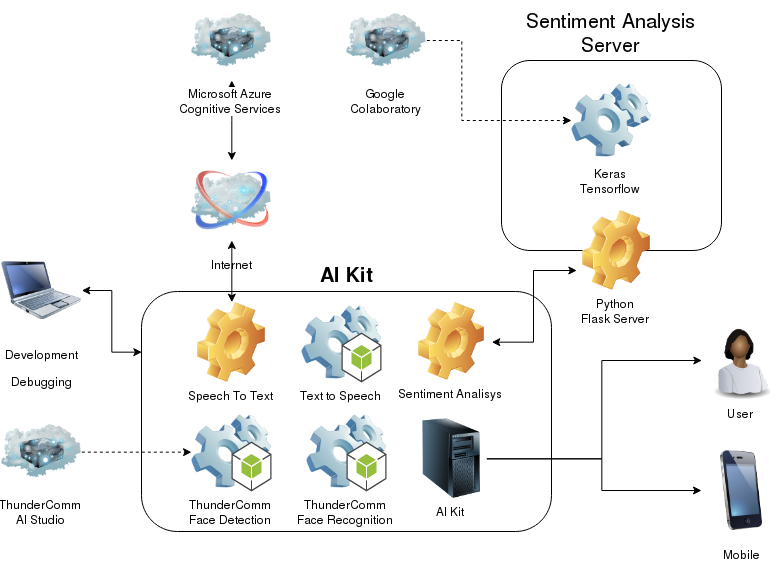
Architecture and componentsThe next picture summarizes the architecture of the proof of concept. Each component will be detailed in its respective step.
First things first. Thundercomm provides a Cloud development platform customized for AI Kit (called AI Studio). Since I wanted to use their Face Detection and Face Recognition algorithms, having a look to the AI Studio sounded like good approach to learn a bit.
In the design above, I've included both available face detectors, one using Thundercomm AI algorithms (called "Face detect(s)") and the other one using a Cloud API (called "Face detect"). The results are shown in the right side of the image and also in the code box below. The first result (name: "lr1InJjbQc") is from CloudAPI and the second result (name: "yfkbXhqJPJ") is ThunderAPI.
[
[
{
"name": "lr1InJjbQc",
"attribute": {
"expression": {
"probability": 1,
"type": "smile"
},
"gender": {
"probability": 1,
"type": "female"
},
"angle": {
"roll": 13.05,
"pitch": 5.25,
"yaw": 22.22
},
"face_token": "dbcc76a9958dc6ff04bb935cef88c781",
"location": {
"top": 379.18,
"left": 915.51,
"rotation": 15,
"width": 483,
"height": 482
},
"face_probability": 1,
"age": 30
}
}
],
[
{
"name": "yfkbXhqJPJ",
"attribute": {
"emotion": "happy",
"stream_id": -1,
"gender": "female",
"frame_w": 0.2574999928474426,
"frame_h": 0.46361589431762695,
"frame_y": 0.1950487643480301,
"frame_x": 0.4154999852180481,
"age": 24
}
}
]
]
Note: You can do some filtering of the values adding JavaScript code to the "Logic Config" box. For example:
var gender = self.ctx[0]['result'][0]['attribute']['gender'];
var emotion = self.ctx[0]['result'][0]['attribute']['emotion'];
var age = self.ctx[0]['result'][0]['attribute']['age'];
alert("Gender: "+ gender + " | Age: "+ age + " | Emotion: "+ emotion);
return true
As mentioned before, I wanted to use Thundercomm AI Kit's Face Detection & Face Recognition capabilities, so first step was to find a way to detect and save the faces.
Thundercomm provides, together the development manual, the source code and info of an Android application demonstrating some of its algorithms. I will use it for the face detection and the enrollment of users in the application.
This are the steps followed to build the app:
- Unzip the "Algo Sample" package from Thundercomm (More info in the Thunder AI Application Development Guide).
- Open the folder in Android Studio and let it to build.
Depending on you Gradle version you could get an error saying "No toolchains found in the NDK toolchains folder for ABI with prefix: mips64el-linux-android". In order to solve this issue open build.gradle and replace the Gradle version to 3.1.0 . Save the file and make the project again (Build >> Make Project) (you may get other Gradle related errors that can be fixed using Android Studio fix suggestions).
#classpath 'com.android.tools.build:gradle:3.0.1'
classpath 'com.android.tools.build:gradle:3.1.0'
- Build the APK (Build >> Build Bundle(s)/APK(s) >> Build APK(s) ). You will probably get an error related to some missing headers in Cmake. Open "External Build Files >> CMakeLists.txt" and replace (at the botton of the file)
SET(CMAKE_CXX_FLAGS "-std=c++0x -DSNPE_ENV" )
with
SET(CMAKE_CXX_FLAGS "-std=c++0x -DSNPE_ENV -isystem <YOUR_PATH_TO_ANDROID_SDK>/AndroidSDK/ndk-bundle/sysroot/usr/include/arm-linux-androideabi" )
- Now, when building the APK again, you probably will get an error saying:
...AlgoSample/app/src/main/cpp/native-lib.cpp:52:20: error: use of undeclared identifier 'write'
int res = write(fd_data, "1", 1);
- This is because a missing header in the file: AlgoSample/app/src/main/cpp/native-lib.cpp . Just open the file and add
#include <unistd.h>
to the include list.
- Now, you should be able to build the Algo Sample project and launch the APK in your AI Kit device.
- Select Enroll/Face Registration on the left of the screen.
and you will be able to detect faces and add then to the face database (see the video below).
Step 3: Speech to TextIn order to do the sentiment analysis, first we need to convert the user speech to text. There were a few possibilities for this:
- Cloud based: Google Cloud Speech-to-Text - Speech Recognition, Microsoft Azure Speech to Text API, ...
- Offline: Android RecognizerIntent, PocketSphinx, ...
This time I wanted to try Microsoft Azure Cognitive Services so I chose Azure Speech to Text.
These are the steps I followed to add Azure's Speech to Text support to the Smart Journal:
- Sing up for the Free trial of the Microsoft Azure Cognitive Services here in order to get the speechSubscriptionKey and serviceRegion.
- In Android Studio >> File >> Project Structure, select project and append 'https://csspeechstorage.blob.core.windows.net/maven/' to the "Default Library Repository".
- In Android Studio >> File >> Project Structure, select "app" and then dependencies and add (+) library dependency: com.microsoft.cognitiveservices.speech:client-sdk:1.1.0
- In Android Studio >> File >> Project Structure, select "app", then "Properties" and select "Source Compatibility: 1.8" and "Target Compatibility: 1.8".
- With this you should be able to run a code like this one below (don't forget to add <YOUR_SUBSCRIPTION_KEY> and <YOUR_SERVICE_REGION> ).
private void doSpeechRecognition(){
try {
Log.d("SJournal","Starting Speech Reco");
SpeechConfig config = SpeechConfig.fromSubscription(<YOUR_SUBSCRIPTION_KEY>, <YOUR_SERVICE_REGION>);
SpeechRecognizer reco = new SpeechRecognizer(config);
Future<SpeechRecognitionResult> task = reco.recognizeOnceAsync();
SpeechRecognitionResult result = task.get();
if (result.getReason() == ResultReason.RecognizedSpeech) {
Log.d("SJournal", result.toString());
/*
Here goes the Sentiment analysis of the result.getText()
*/
}
else {
Log.e("SJournal","Error recognizing: " + result.toString());
}
reco.close();
} catch (Exception e) {
Log.e("SJournal", "Error: " + e.getMessage());
}
}
- This code will provide you with the text representation of the user's speech and you will be able to analyse it in the next step.
Note: Request audio recording and Internet access permissions:
requestPermissions(new String[]{Manifest.permission.RECORD_AUDIO, Manifest.permission.INTERNET},0)
Next step was to build and train the model for the sentiment analysis. I took advantage of Keras/Tensorflow and the IMDB review dataset shipped with Keras for training the model and used Google Colaboratory to run a Jupyter notebook and make different tests there (find the notebook in the attachments section).
The code is summarized in the next steps:
- Loading data: using only the top 10,000 most common words in the IMDB dataset.
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=10000)
x_train_orig = x_train
x_test_orig = x_test
- Preparing the data (ensuring all sequences have same length) with pad_sequences: i) padding with zeros reviews shorter than a predefined amount and ii) truncating reviews longer than that amount
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=words_limit)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=words_limit)
- Creating the Model: Using Word Embedding to capture similarities among words, and 2 densely connected (Dense) neural layers
model = Sequential()
model.add(Embedding(10000, 32, input_length=words_limit))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
- Training the model
history = model.fit(partial_x_train,
partial_y_train,
epochs=7,
batch_size=512,
validation_data=(x_val, y_val))
This is the training/validation accuracy and loss chart for the model above trained 7 epochs.
This model was first saved
model.save("simple_imdb_sa_model_embedding_2x32dense_adam.h5")
and then downloaded to be used in the sentiment analysis server.
from google.colab import files
files.download('simple_imdb_sa_model_embedding_2x32dense_adam.h5')
Note: Deep Learning with Python by François Chollet is a very interesting introduction to Keras and deep learning in general.
Step 4b: Sentiment analysis - Python Flask ServerOnce the model was ready I needed to set up a server to receive the sentences to be analized and use the model to predict the sentiment of the text.
I used Flask to develop a very simple server for responding POST requests.
""" Module for serving sentiment analysis """
from flask import Flask, jsonify, request
from simple_sa import SimpleSA
APP = Flask(__name__, static_url_path='')
SA = SimpleSA()
@APP.route('/sa', methods=['POST'])
def analyse():
""" Return the sentiment analisis of a given sentence """
ret = {}
if not request.json or not "sentence" in request.json:
ret['result'] = "Error: Missing sentence to analyse"
return jsonify(ret)
sentence = request.json['sentence']
ret["sentence"] = sentence
ret["prediction"] = str(SA.get_prediction(sentence))
return jsonify(ret)
if __name__ == '__main__':
APP.run(debug=True, host='0.0.0.0')
Basically it receives a POST request including a JSON with the sentence, calls the class performing the simple sentiment analysis (SimpleSA) and returns the prediction.
Note: you can test easily the server using curl:
curl -i -H "Content-Type: application/json" -X POST -d '{"sentence" : "Worst movie ever"}' 127.0.0.1:5000/sa
For the prediction, I created the SimpleSA class. This class does 3 things:
- 1) Load and initialize the model
self.model = tf.keras.models.load_model("./simple_imdb_sa_model_embedding_2x32dense_adam.h5")
self.graph = tf.get_default_graph()
self.word_index = imdb.get_word_index()
self.words_limit = 331
- 2) Prepare the sentence to make it compatible with the model
words = text.replace("\n", " ").split(" ")
text_indexed = [1,] # 1 == Start
for word in words:
word = word.lower()
if word in self.word_index:
if self.word_index[word] > 1000:
text_indexed.append(2) # 2 == Unknown
else:
text_indexed.append(self.word_index[word] + 3)
else:
text_indexed.append(2) # 2 == Unknown
return text_indexed
- 3) Return the prediction
text_indexed = self.__prepare_sentence(text)
text_padded = keras.preprocessing.sequence.pad_sequences([text_indexed], maxlen=self.words_limit)
with self.graph.as_default():
text_prediction = self.model.predict(text_padded)
return text_prediction[0][0]
For this step I followed a similar approach to "Step 2: Face detection - Enrollment" and relied in Thundercomm Face Recognition. Basically the idea of this step was: detect a face, compare it to the database of faces, extract the emotion related values and save all the info in a Comma-separated values (CSV) format. This CSV info could be later used to generate a graph (or even to populate a time series database (like InfluxDB) and connect it to Grafana for analytics and monitoring).
This is a summary of the steps:
- Add support and configure the FileWriter to write the CSV file in the SD card of the AI Kit (don't forget to request permission for WRITE_EXTERNAL_STORAGE first)
try {
fwriter = new FileWriter("/sdcard/sjournal.csv");
} catch (IOException e) {
e.printStackTrace();
}
- Create an onFaceInfoReceiver and wait for the faces
@Override
public void onFaceInfoReceiver(com.android.thundersoft.facesdk.FaceInfo[] infos) {
for (FaceInfo info : infos){
Log.i("SJournal", ">>> " + info.toString());
}
}
- Go through all detected faces, get the face features and check the enrollment database for getting the name
name = FaceDbManager.getInstance().getRegisteredName(info.features, mFaceStream);
- Get the emotion types (I am only using happiness and sadness in this PoC) and get a value based on the emotion and the recognition confidence
if (info.getEmotion() == FaceInfo.Emotion.Happy) {
value = 1 - ((1 - info.emotion_conf)/2);
}
else if (info.getEmotion() == FaceInfo.Emotion.Sad){
value = 0 + (1 - info.emotion_conf/2);
}
- Save the info in the CSV file
fwriter.write(System.currentTimeMillis()+";video;"+name+";"+emo+";"+value+";"+"confidence: "+info.emotion_conf+"\n");
- The code below shows an extract of the OnFaceInfoReceiver (including all the steps above)
@Override
public void onFaceInfoReceiver(com.android.thundersoft.facesdk.FaceInfo[] faceInfos) {
for (FaceInfo info : faceInfos){
String name = "unknown";
if(vamType == FR){
if(info.features != null){
user = name;
name = FaceDbManager.getInstance().getRegisteredName(info.features,mFaceStream);
Log.i("SJournal", ">>> "+ System.currentTimeMillis() +" " + info.getEmotion().ordinal() + " " + info.getEmotion().name());
try {
float value = 0.5f;
String emo = "neutral";
if (info.getEmotion() == FaceInfo.Emotion.Happy)
{
value = 1 - ((1 - info.emotion_conf)/2);
emo = "happy";
}
else if (info.getEmotion() == FaceInfo.Emotion.Sad)
{
value = 0 + (1 - info.emotion_conf/2);
emo = "sad";
}
fwriter.write(System.currentTimeMillis()+";video;"+name+";"+emo+";"+value+";"+"confidence: "+info.emotion_conf+"\n");
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
The further analysis of the timestamp and emotion/confidence values in the CSV will produce something similar to the chart below ( 1.0 = happy and 0.0 = sad).
The last step was to add support for text-to-speech in order to make the AI KIT produce some audio messages for the user (e.g: some motivational/inspiration quotes).
This was a bit tricky, since I wasn't able to use the PicoTTS included with the AI KIT. I decided to install Flite (festival-lite) using their Android application available at the F-Droid project.
So first step after installing was to change the AI KIT's Text-to-speech output settings (in the accessibility section of the Android settings), and select "Flite TTS Engine" instead of PicoTTS.
Once this was done the TTS worked without any problem.
Below a sample of the code used for the TextoSpeech is shown (TextToSpeech class is shipped with Android, see here for more details) . The idea was to produce some audio messages when the Smart Journal session ended, so I added the TTS to the finish method.
private TextToSpeech tts;
//[...]
public void finish() {
tts = new TextToSpeech(getApplicationContext(), new TextToSpeech.OnInitListener() {
@Override
public void onInit(int status) {
String message = "Thank you for using Smart Journal. Have a great day.";
int res = tts.speak(message, TextToSpeech.QUEUE_ADD, null, null);
if (res == TextToSpeech.ERROR) {
Toast.makeText(getApplicationContext(), "TTS failed! " + res, Toast.LENGTH_LONG).show();
}
}
});
try {
fwriter.flush();
fwriter.close();
} catch (IOException e) {
e.printStackTrace();
}
super.finish();
}
I still needed to do one last thing to integrate all the steps above. It was to make use of the Python Sentiment Analysis server from Java. For this I created a class called Speech_SA and made use of okhttp3 to make the POST requests to the Flask server.
import java.io.IOException;
import okhttp3.MediaType;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.RequestBody;
import okhttp3.Response;
public class Speech_SA
{
public static final MediaType JSON = MediaType.get("application/json; charset=utf-8");
OkHttpClient client = new OkHttpClient();
public String do_speech_sa(String sentence) throws IOException {
String json = "{ \"sentence\" : \""+ sentence + "\"}";
RequestBody body = RequestBody.create(JSON, json);
Request request = new Request.Builder()
.url("http://192.168.0.160:5000/sa")
.post(body)
.build();
try (Response response = client.newCall(request).execute()) {
return response.body().string();
}
}
}
Note: In order to use OkHTTP in your app you need to include "com.squareup.okhttp3:okhttp:3.12.0" in File >> Project Structure >> app >> dependencies.
The prediction got from the audio analysis is also stored in the CVS file for further analysis.
double prediction = Double.parseDouble(get_speech_sa(result.getText().replace("\'","")));
String emo = "neutral";
if (prediction < 0.4)
{
emo = "sad";
}
if (prediction > 0.6)
{
emo = "happy";
}
/* TS, source, user, emotion, value, optional_info */
fwriter.write(System.currentTimeMillis()+";audio;"+user+";"+emo+";"+prediction+";"+result.getText()+"\n");
The final result of the proof of concept is shown in the video below.
- The top right window shows the AI KIT (I used scrcpy to display the AI KIT device).
- Bottom left quadrant shows the logcat, including the info of the detections.
- Bottom right terminal shows the Python Sentiment Analysis server, the requests it gets and the predictions.
- Finally, top left window show the CSV obtained from the analysis.
In summary I could say that the project covered my initial objectives. I was able to test the device and implement a proof of concept of the main elements of the Smart Journal. Probably the next steps will be to play a little with debootstrap to create a Debian system in a chroot and potentially try to play with Tensorflow there.
{kind=link}

Comments