



Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
Hand tools and fabrication machines | ||||||
 |
| |||||
Hand free to choose floor in elevator
2) Features- Voice control
- LCD Display
Follow these instructions to make sure you can record audio on your Raspberry Pi
This is config for Raspi Stretch in this project:
Updating ALSA Config:
sudo nano /usr/share/alsa/alsa.confand look for the following two lines:
defaults.ctl.card 0
defaults.pcm.card 0Change both “0” to “1” and then save the file
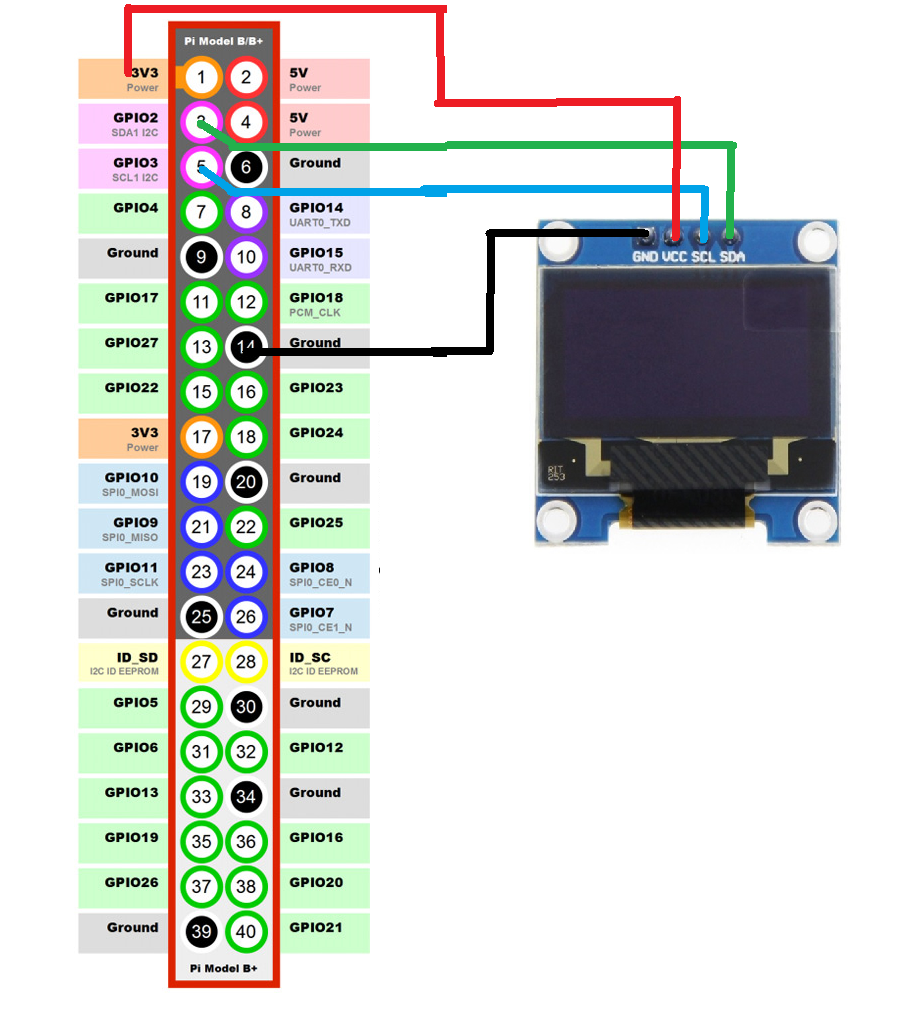
3.2 SchematicRaspi and LCD SSD1306
4.1) Prepair dataset
First, download and unzip the Google Speech Commands dataset on your computer.
Open 1_data_pre.py. Change the dataset_path variable to point to the location of the unzipped Google Speech Commands dataset directory on your computer. Run the entire script.
The script will convert all speech samples (excluding the background_noise set) to their Mel Frequency Cepstral Coefficients (MFCCs), divide them into training, validation, and test sets, and save them as tensors in a file named
all_targets_mfcc_sets.npz.4.2) Train model
Open 02-train.py. Change the dataset_path variable to point to the location of the unzipped Google Speech Commands dataset directory. Also, change the feature_sets_path variable to point to the directory location of the all_targets_mfcc_sets.npz file.
Run the entire script. It will read the MFCCs from the file made in the first script, build a CNN, and train it using the training features we created (MFCCs). The script will then save the model in the
allworld_model.h54.3) Convert to tflite
Open 03-convert_tflite.py and make sure that keras_model_filename points to the location of the.h5 model we created in the previous script.
Run this script to convert the.h5 model into a.tflite model. We will have
allword-model.tflite4.4) Code for Raspi
Copy allword-model.tflite,requirements.txt and 4_ras-voice-cmd.py files to the same directory on your Raspberry Pi. Run requirements.txt to install all requirement packet. Then run the 4_ras-voice-cmd.py script.
If the confidence levels that the last 1 second of captured audio contained the word in this list:
wake_word = ['backward', 'down', '8', '5', 'forward', '4', 'left', '9', 'no', 'off',
'on', '1', 'right','7','6', 'stop','3', '2', 'up','yes','0' ]The program will print out the word in Line 4 LCD.
If you said "YES" next, it will update in Line 3 of LCD, if "NO", it will delete it
If we choose wrong floor, we can choose it again to remove it. In this example, we choose floor 1 - 9 -3, but we don't want go to floor 9, we choose it again to remove it.
Here the video demo:
Because the limit of Raspi so the model run not smooth, it have Input overflow problem, but it work correctly.
from os import listdir
from os.path import isdir, join
import librosa
import random
import numpy as np
import matplotlib.pyplot as plt
import python_speech_features
# Dataset path and view possible targets
dataset_path = './data'
for name in listdir(dataset_path):
if isdir(join(dataset_path, name)):
print(name)
# Create an all targets list
all_targets = [name for name in listdir(dataset_path) if isdir(join(dataset_path, name))]
print(all_targets)
# Leave off background noise set
# all_targets.remove('_background_noise_')
# print(all_targets)
# See how many files are in each
num_samples = 0
for target in all_targets:
print(len(listdir(join(dataset_path, target))))
num_samples += len(listdir(join(dataset_path, target)))
print('Total samples:', num_samples)
# Settings
target_list = all_targets
feature_sets_file = 'all_targets_mfcc_sets.npz'
perc_keep_samples = 1.0 # 1.0 is keep all samples
val_ratio = 0.1
test_ratio = 0.1
sample_rate = 8000
num_mfcc = 16
len_mfcc = 16
# Create list of filenames along with ground truth vector (y)
filenames = []
y = []
for index, target in enumerate(target_list):
print(join(dataset_path, target))
filenames.append(listdir(join(dataset_path, target)))
y.append(np.ones(len(filenames[index])) * index)
# Check ground truth Y vector
print(y)
for item in y:
print(len(item))
# Flatten filename and y vectors
filenames = [item for sublist in filenames for item in sublist]
y = [item for sublist in y for item in sublist]
# Associate filenames with true output and shuffle
filenames_y = list(zip(filenames, y))
random.shuffle(filenames_y)
filenames, y = zip(*filenames_y)
# Only keep the specified number of samples (shorter extraction/training)
# print(len(filenames))
filenames = filenames[:int(len(filenames) * perc_keep_samples)]
# print(len(filenames))
# Calculate validation and test set sizes
val_set_size = int(len(filenames) * val_ratio)
test_set_size = int(len(filenames) * test_ratio)
# Break dataset apart into train, validation, and test sets
filenames_val = filenames[:val_set_size]
filenames_test = filenames[val_set_size:(val_set_size + test_set_size)]
filenames_train = filenames[(val_set_size + test_set_size):]
# Break y apart into train, validation, and test sets
y_orig_val = y[:val_set_size]
y_orig_test = y[val_set_size:(val_set_size + test_set_size)]
y_orig_train = y[(val_set_size + test_set_size):]
# Function: Create MFCC from given path
def calc_mfcc(path):
# Load wavefile
signal, fs = librosa.load(path, sr=sample_rate)
# Create MFCCs from sound clip
mfccs = python_speech_features.base.mfcc(signal,
samplerate=fs,
winlen=0.256,
winstep=0.050,
numcep=num_mfcc,
nfilt=26,
nfft=2048,
preemph=0.0,
ceplifter=0,
appendEnergy=False,
winfunc=np.hanning)
return mfccs.transpose()
# TEST: Construct test set by computing MFCC of each WAV file
prob_cnt = 0
x_test = []
y_test = []
for index, filename in enumerate(filenames_train):
# Stop after 500
if index >= 500:
break
# Create path from given filename and target item
path = join(dataset_path, target_list[int(y_orig_train[index])],
filename)
# Create MFCCs
mfccs = calc_mfcc(path)
if mfccs.shape[1] == len_mfcc:
x_test.append(mfccs)
y_test.append(y_orig_train[index])
else:
print('Dropped:', index, mfccs.shape)
prob_cnt += 1
print('% of problematic samples:', prob_cnt / 500)
# TEST: Test shorter MFCC
# !pip install playsound
from playsound import playsound
idx = 13
# Create path from given filename and target item
path = join(dataset_path, target_list[int(y_orig_train[idx])],
filenames_train[idx])
# Create MFCCs
mfccs = calc_mfcc(path)
print("MFCCs:", mfccs)
# Plot MFCC
fig = plt.figure()
plt.imshow(mfccs, cmap='inferno', origin='lower')
# TEST: Play problem sounds
print(target_list[int(y_orig_train[idx])])
playsound(path)
# Function: Create MFCCs, keeping only ones of desired length
def extract_features(in_files, in_y):
prob_cnt = 0
out_x = []
out_y = []
for index, filename in enumerate(in_files):
# Create path from given filename and target item
path = join(dataset_path, target_list[int(in_y[index])],
filename)
# Check to make sure we're reading a .wav file
if not path.endswith('.wav'):
continue
# Create MFCCs
mfccs = calc_mfcc(path)
# Only keep MFCCs with given length
if mfccs.shape[1] == len_mfcc:
out_x.append(mfccs)
out_y.append(in_y[index])
else:
print('Dropped:', index, mfccs.shape)
prob_cnt += 1
return out_x, out_y, prob_cnt
# Create train, validation, and test sets
x_train, y_train, prob = extract_features(filenames_train,
y_orig_train)
print('Removed percentage:', prob / len(y_orig_train))
x_val, y_val, prob = extract_features(filenames_val, y_orig_val)
print('Removed percentage:', prob / len(y_orig_val))
x_test, y_test, prob = extract_features(filenames_test, y_orig_test)
print('Removed percentage:', prob / len(y_orig_test))
# Save features and truth vector (y) sets to disk
np.savez(feature_sets_file,
x_train=x_train,
y_train=y_train,
x_val=x_val,
y_val=y_val,
x_test=x_test,
y_test=y_test)
# TEST: Load features
feature_sets = np.load(feature_sets_file)
feature_sets.files
print(len(feature_sets['x_train']))
print(feature_sets['y_val'])
import json
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from os import listdir
from os.path import isdir, join
from sklearn.model_selection import train_test_split
feature_sets_path = './'
DATA_PATH = 'all_targets_mfcc_sets.npz'
SAVED_MODEL_PATH = 'allworld_model.h5'
EPOCHS = 40
BATCH_SIZE = 32
PATIENCE = 5
LEARNING_RATE = 0.0001
def prepare_dataset(data_path, test_size=0.2, validation_size=0.2):
"""Creates train, validation and test sets.
:param data_path (str): Path to json file containing data
:param test_size (flaot): Percentage of dataset used for testing
:param validation_size (float): Percentage of train set used for cross-validation
:return X_train (ndarray): Inputs for the train set
:return y_train (ndarray): Targets for the train set
:return X_validation (ndarray): Inputs for the validation set
:return y_validation (ndarray): Targets for the validation set
:return X_test (ndarray): Inputs for the test set
:return X_test (ndarray): Targets for the test set
"""
# load dataset
feature_sets = np.load(join(feature_sets_path, DATA_PATH))
print(feature_sets.files)
# Assign feature sets
X_train = feature_sets['x_train']
y_train = feature_sets['y_train']
X_validation = feature_sets['x_val']
y_validation = feature_sets['y_val']
X_test = feature_sets['x_test']
y_test = feature_sets['y_test']
# # create train, validation, test split
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size)
# X_train, X_validation, y_train, y_validation = train_test_split(X_train, y_train, test_size=validation_size)
# add an axis to nd array
X_train = X_train[..., np.newaxis]
X_test = X_test[..., np.newaxis]
X_validation = X_validation[..., np.newaxis]
return X_train, y_train, X_validation, y_validation, X_test, y_test
def build_model(input_shape, loss="sparse_categorical_crossentropy", learning_rate=0.0001):
"""Build neural network using keras.
:param input_shape (tuple): Shape of array representing a sample train. E.g.: (44, 13, 1)
:param loss (str): Loss function to use
:param learning_rate (float):
:return model: TensorFlow model
"""
# build network architecture using convolutional layers
model = tf.keras.models.Sequential()
# 1st conv layer
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu', input_shape=input_shape,
kernel_regularizer=tf.keras.regularizers.l2(0.001)))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.MaxPooling2D((3, 3), strides=(2,2), padding='same'))
# 2nd conv layer
model.add(tf.keras.layers.Conv2D(32, (3, 3), activation='relu',
kernel_regularizer=tf.keras.regularizers.l2(0.001)))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.MaxPooling2D((3, 3), strides=(2,2), padding='same'))
# 3rd conv layer
model.add(tf.keras.layers.Conv2D(32, (2, 2), activation='relu',
kernel_regularizer=tf.keras.regularizers.l2(0.001)))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.MaxPooling2D((2, 2), strides=(2,2), padding='same'))
# flatten output and feed into dense layer
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(64, activation='relu'))
tf.keras.layers.Dropout(0.3)
# softmax output layer
model.add(tf.keras.layers.Dense(21, activation='softmax'))
optimiser = tf.optimizers.Adam(learning_rate=learning_rate)
# compile model
model.compile(optimizer=optimiser,
loss=loss,
metrics=["accuracy"])
# print model parameters on console
model.summary()
return model
def train(model, epochs, batch_size, patience, X_train, y_train, X_validation, y_validation):
"""Trains model
:param epochs (int): Num training epochs
:param batch_size (int): Samples per batch
:param patience (int): Num epochs to wait before early stop, if there isn't an improvement on accuracy
:param X_train (ndarray): Inputs for the train set
:param y_train (ndarray): Targets for the train set
:param X_validation (ndarray): Inputs for the validation set
:param y_validation (ndarray): Targets for the validation set
:return history: Training history
"""
earlystop_callback = tf.keras.callbacks.EarlyStopping(monitor="accuracy", min_delta=0.001, patience=patience)
# train model
history = model.fit(X_train,
y_train,
epochs=epochs,
batch_size=batch_size,
validation_data=(X_validation, y_validation),
callbacks=[earlystop_callback])
return history
def plot_history(history):
"""Plots accuracy/loss for training/validation set as a function of the epochs
:param history: Training history of model
:return:
"""
fig, axs = plt.subplots(2)
# create accuracy subplot
axs[0].plot(history.history["accuracy"], label="accuracy")
axs[0].plot(history.history['val_accuracy'], label="val_accuracy")
axs[0].set_ylabel("Accuracy")
axs[0].legend(loc="lower right")
axs[0].set_title("Accuracy evaluation")
# create loss subplot
axs[1].plot(history.history["loss"], label="loss")
axs[1].plot(history.history['val_loss'], label="val_loss")
axs[1].set_xlabel("Epoch")
axs[1].set_ylabel("Loss")
axs[1].legend(loc="upper right")
axs[1].set_title("Loss evaluation")
plt.show()
def main():
# generate train, validation and test sets
X_train, y_train, X_validation, y_validation, X_test, y_test = prepare_dataset(DATA_PATH)
# create network
input_shape = (X_train.shape[1], X_train.shape[2], 1)
model = build_model(input_shape, learning_rate=LEARNING_RATE)
# train network
history = train(model, EPOCHS, BATCH_SIZE, PATIENCE, X_train, y_train, X_validation, y_validation)
# plot accuracy/loss for training/validation set as a function of the epochs
plot_history(history)
# evaluate network on test set
test_loss, test_acc = model.evaluate(X_test, y_test)
print("\nTest loss: {}, test accuracy: {}".format(test_loss, 100*test_acc))
# save model
model.save(SAVED_MODEL_PATH)
if __name__ == "__main__":
main()
from tensorflow import lite
from tensorflow.keras import models
# Parameters
keras_model_filename = 'allworld_model.h5'
tflite_filename = 'allword-model.tflite'
# Convert model to TF Lite model
model = models.load_model(keras_model_filename)
converter = lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
open(tflite_filename, 'wb').write(tflite_model)
from datetime import datetime
import sounddevice as sd
import numpy as np
import scipy.signal
import timeit
from python_speech_features import mfcc
import Adafruit_SSD1306
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
import time
from tflite_runtime.interpreter import Interpreter
import RPi.GPIO as GPIO
# Parameters
debug_time = 0
debug_acc = 0
word_threshold = 0.75
rec_duration = 0.5
window_stride = 0.5
sample_rate = 48000
resample_rate = 8000
num_channels = 1
num_mfcc = 16
led_pin_up = 8 #led UP
led_pin_down = 10 #led DOWN
show_floor_yes =[]
number_floor = 0
#----------------------------------------------------------------------#
# GPIO
#----------------------------------------------------------------------#
GPIO.setwarnings(False)
GPIO.setmode(GPIO.BCM)
GPIO.setup(8, GPIO.OUT, initial=GPIO.LOW)
GPIO.setup(10, GPIO.OUT, initial=GPIO.LOW)
#----------------------------------------------------------------------#
model_path = 'allword-model.tflite'
wake_word = ['backward', 'down', '8', '5', 'forward', '4', 'left', '9', 'no', 'off',
'on', '1', 'right','7','6', 'stop','3', '2', 'up','yes','0' ]
# Sliding window
window = np.zeros(int(rec_duration * resample_rate) * 2)
#----------------------------------------------------------------------#
#set up lcd
#----------------------------------------------------------------------#
disp = Adafruit_SSD1306.SSD1306_128_32(rst = None)
# Initialize library.
disp.begin()
# Clear display.
disp.clear()
disp.display()
# Create blank image for drawing.
# Make sure to create image with mode '1' for 1-bit color.
width = disp.width
height = disp.height
image = Image.new('1', (width, height))
# Get drawing object to draw on image.
draw = ImageDraw.Draw(image)
# Draw a black filled box to clear the image.
draw.rectangle((0,0,width,height), outline=0, fill=0)
# Draw some shapes.
# First define some constants to allow easy resizing of shapes.
padding = -2
top_lcd = padding
bottom = height-padding
# Move left to right keeping track of the current x position for drawing shapes.
x = 0
# Load default font.
font = ImageFont.load_default()
# Display image
now = datetime.now()
d3 = now.strftime("%d/%m/%Y %H:%M")
draw.text((x, top_lcd), str(d3) , font=font, fill=255)
# draw.line()
draw.text((x, top_lcd+8), "GO UP - 10", font=font, fill=255)
# draw.line()
draw.text((x,top_lcd+16), "NEXT: ", font=font, fill= 255)
draw.text((x, top_lcd + 24), "FlOOR: ", font=font, fill=255)
disp.image(image)
disp.display()
time.sleep(1)
#----------------------------------------------------------------------#
# Load model (interpreter)
#----------------------------------------------------------------------#
interpreter = Interpreter(model_path)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
#print(input_details)
print("model loaded")
#----------------------------------------------------------------------#
# LCD
#----------------------------------------------------------------------#
def lcd_print_line1():
now = datetime.now()
d3 = now.strftime("%d/%m/%Y %H:%M")
# clear line 1 + 2
draw.rectangle((0, 0, 128, 7), outline=0, fill=0)
# draw Hour
draw.text((x, top_lcd), str(d3), font=font, fill=255)
disp.image(image)
disp.display()
time.sleep(.1)
def lcd_print_line2(line): # show : "UP - 8 ": going up, on 8th floor
#clear line 2
draw.rectangle((0, top_lcd + 8, 128, 15), outline=0, fill=0)
#draw go up/down line 2
draw.text((x, top_lcd + 8),"GO UP - " + str(line), font=font, fill=255)
# disp.image(image)
# disp.display()
# time.sleep(.1)
def lcd_print_line3(line): #show: "Next: 2 - 5 - 8": floor will go to
#clear line 3
draw.rectangle((x, top_lcd + 17, 128, 23), outline=0, fill=0)
# draw line 3
draw.text((x, top_lcd + 16), "NEXT: " + str(line), font=font, fill=255)
# disp.image(image)
# disp.display()
# time.sleep(.1)
def lcd_print_line4(line): # show: "Choose Floor: 1" :after speech number, it will show here
#clear
draw.rectangle((x, top_lcd + 25, 128, 32), outline=0, fill=0)
#draw line 1 #show number floor
draw.text((x, top_lcd + 24), "FlOOR: " + str(line), font=font, fill=255)
# disp.image(image)
# disp.display()
# time.sleep(.1)
def lcd_clear_line4():
draw.rectangle((x, top_lcd + 25, 128, 32), outline=0, fill=0)
draw.text((x, top_lcd + 24), "FlOOR: ", font=font, fill=255)
# disp.image(image)
# disp.display()
# time.sleep(.1)
def lcd_yes(num_floor, array_floor):
if num_floor in array_floor:
array_floor.remove(num_floor)
else:
array_floor.append(num_floor)
def show_lcd(label):
label = wake_word[label]
global number_floor, flag_no
#check lable = 0 ->9, yes, no, up, down
wake_word_work = ['0','1','2','3','4','5', '6','7','8','9',
'stop', 'up', 'down','no','yes']
if label in wake_word_work:
continue_show = True
else:
continue_show = False
if continue_show:
if label == 'up': #up - down : on led
GPIO.output(led_pin_up, GPIO.HIGH)
GPIO.output(led_pin_down, GPIO.LOW)
elif label == 'down':
GPIO.output(led_pin_up, GPIO.LOW)
GPIO.output(led_pin_down, GPIO.HIGH)
elif label == 'stop':
#stop
GPIO.output(led_pin_up, GPIO.HIGH)
GPIO.output(led_pin_down, GPIO.HIGH)
elif label == 'yes':
lcd_yes(number_floor, show_floor_yes)
arraytostr = '-'.join(map(str, show_floor_yes))
#up to line 3, if already in line 3, delete it
lcd_print_line3(arraytostr)
#clear line 4
lcd_clear_line4()
elif label == 'no': # , no: delete
#delete line 4
lcd_clear_line4()
else: #number: show in line 4 of LCD,
#show line 4
lcd_print_line4(label)
number_floor = label
# ----------------------------------------------------------------------#
# Call back + process input audio
# ----------------------------------------------------------------------#
# Decimate (filter and downsample)
def decimate(signal, old_fs, new_fs):
# Check to make sure we're downsampling
if new_fs > old_fs:
print("Error: target sample rate higher than original")
return signal, old_fs
# We can only downsample by an integer factor
dec_factor = old_fs / new_fs
if not dec_factor.is_integer():
print("Error: can only decimate by integer factor")
return signal, old_fs
# Do decimation
resampled_signal = scipy.signal.decimate(signal, int(dec_factor))
return resampled_signal, new_fs
# This gets called every 0.5 seconds
def sd_callback(rec, frames, time, status):
# Start timing for testing
start = timeit.default_timer()
# Notify if errors
if status:
print('Error:', status)
# Remove 2nd dimension from recording sample
rec = np.squeeze(rec)
# Resample
rec, new_fs = decimate(rec, sample_rate, resample_rate)
# Save recording onto sliding window
window[:len(window) // 2] = window[len(window) // 2:]
window[len(window) // 2:] = rec
# if debug_time:
# print("t1 =",timeit.default_timer() - start)
# Compute features
mfccs = mfcc(window,
samplerate=new_fs,
winlen=0.256,
winstep=0.050,
numcep=num_mfcc,
nfilt=26,
nfft=2048,
preemph=0.0,
ceplifter=0,
appendEnergy=False,
winfunc=np.hanning)
mfccs = mfccs.transpose()
# Make prediction from model
in_tensor = np.float32(mfccs.reshape(1, mfccs.shape[0], mfccs.shape[1], 1))
interpreter.set_tensor(input_details[0]['index'], in_tensor)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
prediction = output_data.argmax(axis=1)
val = np.max(output_data)
tes= wake_word[prediction[0]]
# print(output_data)
if val > word_threshold:
print(tes)
show_lcd(prediction[0])
if debug_acc:
print("val = " , val)
if debug_time:
print("t2=",timeit.default_timer() - start)
# ----------------------------------------------------------------------#
# Start streaming from microphone
# ----------------------------------------------------------------------#
with sd.InputStream(channels=num_channels,
samplerate=sample_rate,
blocksize=int(sample_rate * rec_duration),
callback=sd_callback):
#print(sd.query_devices())
while True:
lcd_print_line1()
Adafruit-GPIO==1.0.3
Adafruit-PureIO==1.1.5
Adafruit-SSD1306==1.6.2
attrs==19.3.0
backcall==0.2.0
bleach==3.1.5
cffi==1.14.0
cycler==0.10.0
decorator==4.4.2
defusedxml==0.6.0
entrypoints==0.3
importlib-metadata==1.7.0
ipykernel==5.3.0
ipython==7.16.1
ipython-genutils==0.2.0
ipywidgets==7.5.1
jedi==0.17.1
Jinja2==2.11.2
jsonschema==3.2.0
jupyter==1.0.0
jupyter-client==6.1.5
jupyter-console==6.1.0
jupyter-core==4.6.3
kiwisolver==1.2.0
MarkupSafe==1.1.1
matplotlib==3.2.2
mistune==0.8.4
mpmath==1.1.0
nbconvert==5.6.1
nbformat==5.0.7
nose==1.3.7
notebook==6.0.3
numpy==1.19.0
packaging==20.4
pandas==1.0.5
pandocfilters==1.4.2
parso==0.7.0
pexpect==4.8.0
pickleshare==0.7.5
Pillow==7.2.0
pkg-resources==0.0.0
prometheus-client==0.8.0
prompt-toolkit==3.0.5
ptyprocess==0.6.0
pycparser==2.20
Pygments==2.6.1
pyparsing==2.4.7
pyrsistent==0.16.0
python-dateutil==2.8.1
python-speech-features==0.6
pytz==2020.1
pyzmq==19.0.1
qtconsole==4.7.5
QtPy==1.9.0
RPi.GPIO==0.7.0
scipy @ file:///home/pi/Desktop/Voice_elevator/scipy-1.5.0rc1-cp37-cp37m-linux_armv7l.whl
Send2Trash==1.5.0
six==1.15.0
sounddevice==0.3.15
spidev==3.5
sympy==1.6
terminado==0.8.3
testpath==0.4.4
tflite-runtime==2.1.0.post1
tornado==6.0.4
traitlets==4.3.3
wcwidth==0.2.5
webencodings==0.5.1
widgetsnbextension==3.5.1
zipp==3.1.0





{kind=link}
Comments
Please log in or sign up to comment.