




Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
_ztBMuBhMHo.jpg?auto=compress%2Cformat&w=48&h=48&fit=fill&bg=ffffff) |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
| ||||||
| ||||||
According to World Health Organization, more than 2 billion people are still being affected by contaminated water. And while we think it’s safe in United States, flint, Michigan water crisis has proven to us that even in first world country like US, we still face water safety issues.
Currently the all of the water sensors are chemical based, the most common on being using chemical test strips that are one time use. Making monitoring contamination extremely difficult and exhausting hence events like Flint, MI has happened in the past.
The method of detection
Clean Water AI is IoT device that classifies and detects dangerous bacteria and harmful particles. The system can run continuously in real time. The cities can install IoT devices across different water sources and they will be able to monitor water quality as well as contamination continuously.
What is AI and how to use itDeep learning has been a pretty big trend for machine learning lately, and the recent success has paved the way to build project like this. We are going to focus specifically on computer vision and image classification in this sample. To do this, we will be building nevus, melanoma, and seborrheic keratosis image classifier using deep learning algorithm, the Convolution Neural Network (CNN) through Caffe Framework.
In this article we will focus on Supervised learning, it requires training on the server as well as deploying on the edge. Our goal is to build a machine learning algorithm that can detect contamination images in real time, this way you can build your own AI based contamination classification device.
Our application will include 2 parts, the first part is training, which we will be using different sets of cancer image database to train a machine learning algorithm (model) with their corresponding labels. The second part is deploying on the edge, which uses the same model we've trained and running it on an Edge device, in this case Movidius Neural Computing Stick.
Traditional Machine Learning (ML) vs. Deep Learning
This is probably the most asked question in AI, and it's fairly simple once you learn how to do it. In order to understand this we first have to learn how machine learning image classification works.
Machine learning requires feature extraction and model training. We first have to use domain knowledge to extract features that can be used for our ML algorithm model, some examples includes SIFT and HoG. After that we can use a dataset that has all the image features and labels to train our machine learning model.
The major difference between traditional ML and Deep Learning is in the feature engineering. The traditional ML uses manually programmed features where Deep Learning does it automatically. Feature engineering is relatively difficult since it requires domain expertise and is very time consuming. Deep learning requires no feature engineering and can be more accurate
Convolutional Neural Networks (CNNs)
Convolutional neural network is a class of deep, feed-forward artificial neural networks, most commonly applied to analyzing visual imagery because it is designed to emulate behavior of biological behaviors on animal visual cortex. It consist of convolutional layers and pooling layers so that the network can encode image properties.
The convolutional layer's parameters consists of a set of learnable filters (or kernels) that have a small receptive field. This way the image can convolve across spatially, and computing dot products between the entries of the filter and the input and producing a 2-dimensional activation map of that filter. This way the network learns filters that can activate when it detects special features on the input image's spatial feature.
Neurons of a convolutional layer (blue), connected to their receptive field (red). Source (Wikipedia)
The pooling layer is a form of non-linear down-sampling. It partitions the input image into a set of non-overlapping rectangles and, for each such sub-region, outputs the maximum. The idea is to continuously reduce the spatial size of the input representation to reduce the amount of parameters and computation in the network, so it can also control overfitting. Max pooling is the most common type non-linear pooling. According to wikipedia, "Pooling is often applied with filters of size 2x2 applied with a stride of 2 at every depth slice. A pooling layer of size 2x2 with stride of 2 shrinks the input image to a 1/4 of its original size."
Connecting AI to IoT
In this project we are trying to gather the information from the camera and inferencing it over the edge device, then pass the data using Azure IoT Hub
So we first generate a water flow simulation through Peristaltic Liquid Pump so that we simulate the water flow in our pipes. We can do that via Arduino Uno with a button attached. This will be seen in the later steps
The Arduino code is listed as following.
#define ROTARY_ANGLE_SENSOR A0
#define LED 3 //the Grove - LED is connected to PWM pin D3 of Arduino
#define ADC_REF 5 //reference voltage of ADC is 5v.If the Vcc switch on the seeeduino
//board switches to 3V3, the ADC_REF should be 3.3
#define GROVE_VCC 5 //VCC of the grove interface is normally 5v
#define FULL_ANGLE 300 //full value of the rotary angle is 300 degrees
const int ledPin = 6; // the number of the LED pin
const int ledPin2 = 5; // the number of the LED pin
int incomingByte = 0; // for incoming serial data
const int buttonPin = 2; // the number of the pushbutton pin
int buttonState = 0; // variable for reading the pushbutton status
void setup() {
// initialize the LED pin as an output:
pinMode(ledPin, OUTPUT);
pinMode(ledPin2, OUTPUT);
// initialize the LED pin as an output:
// initialize the pushbutton pin as an input:
pinMode(buttonPin, INPUT);
Serial.begin(9600); // opens serial port, sets data rate to 9600 bps
pinMode(ROTARY_ANGLE_SENSOR, INPUT);
pinMode(LED,OUTPUT);
}
void loop() {
/*
buttonState = digitalRead(buttonPin);
if (buttonState == HIGH) {
// turn LED on:
digitalWrite(ledPin, HIGH);
Serial.println("on");
} else {
// turn LED off:
digitalWrite(ledPin, LOW);
Serial.println("off");
}*/
float voltage;
int sensor_value = analogRead(ROTARY_ANGLE_SENSOR);
voltage = (float)sensor_value*ADC_REF/1023;
float degrees = (voltage*FULL_ANGLE)/GROVE_VCC;
//Serial.println("The angle between the mark and the starting position:");
//Serial.println(degrees);
if(degrees < 100)
{
digitalWrite(ledPin, HIGH);
digitalWrite(ledPin2, HIGH);
Serial.println("on");
}
else
{
digitalWrite(ledPin, LOW);
digitalWrite(ledPin2, LOW);
Serial.println("off");
}
delay(100);
}
When it's all built, it should look something like this
Step 2: Component list for the IoTSince we are planning to We'd need following items
- Up2 board
- Movidius PCIe card (or Movidius NCS) for AI on the Edge (picture showing both)
- Helium Atom Module and Helium Access Point
- Microscope
First, we'll need a computer to train the data, there are many options here since our dataset is relatively small. Intel DevCloud currently offers 3 month for free utilizing Intel Caffe through Intel AI Academy. In this guide we will be utilizing GPU Training from Azure's Data Science Virtual Machine for long term usage. Azure offers $200 credit for signing up, and we can utilize it's Virtual Machine which uses K80.
we can easily go into our server via normal ssh
ssh instance_name_here
Deep learning has been a pretty big trend for machine learning lately, and the recent success has paved the way to build project like this. We are going to focus specifically on computer vision and image classification in this sample. To do this, we will be building contamination/clean image classifier using deep learning algorithm, the Convolution Neural Network (CNN) through Caffe Framework.
But first, we need to gather data, in this particular guide we will be training yeast, you can extend it to ecoli, cholera, and many others dangerous bacteria in the future. Yeast is rather safe to use. The bacteria data are a bit difficult to find on the internet, we can do it for classification after the initial PoC is done. The image data looks like below.
Once we take take a photo, we can collect our own dataset by taking about 500 images of clean water and 500 images of yeast contaminated water from microscope camera.
Convolutional neural networks are feedforward neural network. They model same as of a visual cortex of human beings. This way it does extremely well on visual recognition and image classification tasks. The convolutional layers and pooling layers inside CNNs allow the network to encode images properties and extract features. For the current guide, we will be using Caffe Framework for the easily deployment on Movidius NCS.
Once data is collected, we need to copy them into our server
ssh instance_name_here
This part can be a bit more complicated, you can either follow this instruction to create everything or simply copy the open source directory in the github repo attached to this giude.
After collecting the image data from Step 4, we need create an input/train folder and move all the images inside there. After that create a /code/folder and run the following code.
import os
import glob
import random
import numpy as np
import cv2
import caffe
from caffe.proto import caffe_pb2
import lmdb
#Size of images
IMAGE_WIDTH = 227
IMAGE_HEIGHT = 227
def transform_img(img, img_width=IMAGE_WIDTH, img_height=IMAGE_HEIGHT):
#Histogram Equalization
img[:, :, 0] = cv2.equalizeHist(img[:, :, 0])
img[:, :, 1] = cv2.equalizeHist(img[:, :, 1])
img[:, :, 2] = cv2.equalizeHist(img[:, :, 2])
#Image Resizing
img = cv2.resize(img, (img_width, img_height), interpolation = cv2.INTER_CUBIC)
return img
def make_datum(img, label):
#image is numpy.ndarray format. BGR instead of RGB
return caffe_pb2.Datum(
channels=3,
width=IMAGE_WIDTH,
height=IMAGE_HEIGHT,
label=label,
data=np.rollaxis(img, 2).tostring())
train_lmdb = '/home/ubuntu/face_training/input/train_lmdb'
validation_lmdb = '/home/ubuntu/face_training/input/validation_lmdb'
os.system('rm -rf ' + train_lmdb)
os.system('rm -rf ' + validation_lmdb)
train_data = [img for img in glob.glob("../input/train/*jpg")]
test_data = [img for img in glob.glob("../input/test1/*jpg")]
#Shuffle train_data
random.shuffle(train_data)
print 'Creating train_lmdb'
in_db = lmdb.open(train_lmdb, map_size=int(1e12))
with in_db.begin(write=True) as in_txn:
for in_idx, img_path in enumerate(train_data):
if in_idx % 6 == 0:
continue
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
img = transform_img(img, img_width=IMAGE_WIDTH, img_height=IMAGE_HEIGHT)
if 'yeast' in img_path:
label = 0
else:
label = 1
datum = make_datum(img, label)
in_txn.put('{:0>5d}'.format(in_idx), datum.SerializeToString())
print '{:0>5d}'.format(in_idx) + ':' + img_path
in_db.close()
print '\nCreating validation_lmdb'
in_db = lmdb.open(validation_lmdb, map_size=int(1e12))
with in_db.begin(write=True) as in_txn:
for in_idx, img_path in enumerate(train_data):
if in_idx % 6 != 0:
continue
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
img = transform_img(img, img_width=IMAGE_WIDTH, img_height=IMAGE_HEIGHT)
if 'yeast' in img_path:
label = 0
else:
label = 1
datum = make_datum(img, label)
in_txn.put('{:0>5d}'.format(in_idx), datum.SerializeToString())
print '{:0>5d}'.format(in_idx) + ':' + img_path
in_db.close()
print '\nFinished processing all images'
- 5/6 of the data set will be used for training, 1/6 is being used for validation so we can calculate the accuracy of the model
- We are resizing all images to 227x227 to follow the same standard as BVLC
- Histogram equalization is being applied to all the training images to adjust the contrast.
- And store them among train_lmdb and validation_lmdb
- Use make_datum to label all the image dataset inside lmdb
Run the following
python2 code.py
This would generate both training_lmdb as well as validation_lmdb for classifying contamination through yeast vs. clean water.
Following that we need to calculate the mean by running following command
cd ../input
{path to caffe}/build/tools/compute_image_mean -backend=lmdb /train_lmdb mean.binaryproto
We can train our caffe model using a lot of different types of neural network, but let's keep this guide simple by using the CaffeNet framework and build our model based on that. We can name it caffenet_train.prototxt.
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "{your_app_folder}/input/mean.binaryproto"
}
data_param {
source: "{your_app_folder}/input/train_lmdb"
batch_size: 128
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "{your_app_folder}/input/mean.binaryproto"
}
data_param {
source: "{your_app_folder}/input/validation_lmdb"
batch_size: 15
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc8"
bottom: "label"
top: "loss"
}
After seeing up the model we can use the solver, name it solver.prototxt
net: "{your_app_folder}/caffe_model/
test_iter: 50
test_interval: 50
base_lr: 0.001
lr_policy: "step"
gamma: 0.1
stepsize: 100
display: 50
max_iter: 2000
momentum: 0.9
weight_decay: 0.0005
snapshot: 500
snapshot_prefix: "{your_app_folder}/caffe_model/WaterNet"
solver_mode: GPU
We can now start training
caffe train --solver {your_app_folder}/caffe_model/solver.prototxt
This should finish in 10 minutes, if any parameter has problem you can simply do it again. After everything you should have WaterNet_iter_2000.caffemodel inside your caffe_model shoulder. To test out the accuracy simply create a label.txt file
Contaminated
Clean
And run following command to test out the result:
classification.bin {your_app_folder}/caffe_model/deploy.prototxt {your_app_folder}/caffe_model/WaterNet_iter_2000.caffemodel {your_app_folder}/input/mean.binaryproto {your_app_folder}/caffe_model/labels.txt {your_app_folder}/input/train/yeast-200.jpg
For this article we are using Up2 Board so that we can have an offline device which we can carry around everywhere. The Up2 Board is already installed with Ubuntu 16.04, making things a bit more easier. On the device we can first create a folder copying everything we trained on the server.
mkdir ~/workspace
cd ~/workspace
mkdir cleanwaterai
cd cleanwaterai
mkdir WaterNet
cd WaterNet
scp --recurse {your_instance}:/{your_app_folder}/caffe_model/* ./
Afterwards we need to install Movidius NCS SDK via https://developer.movidius.com/start. This is to ensure that we can run our programs on the edge. Simple command would be
cd ~/workspace
git clone https://github.com/movidius/ncsdk.git
cd ~/workspace/ncsdk
make install
For full instruction, you can simply go through this guide
Next we need to download all the sample apps ncappzoo, which is also created by Movidius, and the specific app we need is stream inference, which can be gotten from the example file
cd ~/workspace
git clone https://github.com/movidius/ncappzoo.git
cd ~/cleanwaterai
cp ~/workspace/ncappzoo/apps/stream_infer/* ./
Change the file into WaterNet we've just created
NETWORK_IMAGE_WIDTH = 227 # the width of images the network requires
NETWORK_IMAGE_HEIGHT = 227 # the height of images the network requires
NETWORK_IMAGE_FORMAT = "BGR" # the format of the images the network requires
NETWORK_DIRECTORY = "/WaterNet/" # directory of the network
NETWORK_STAT_TXT = "./squeezenet_stat.txt" # stat.txt for network
NETWORK_CATEGORIES_TXT = "/WaterNet/label.txt" # categories.txt for network
Last and final part, we need to compile a graph file for Movidius NCS SDK
cd ~/workspace/cleanwaterai/WaterNet/
mvNCCompile deploy.prototxt -w WaterNet_iter_2000.caffemodel
cd ..
mv stream_infer.py cleanwaterai.py
python3 cleanwaterai.py
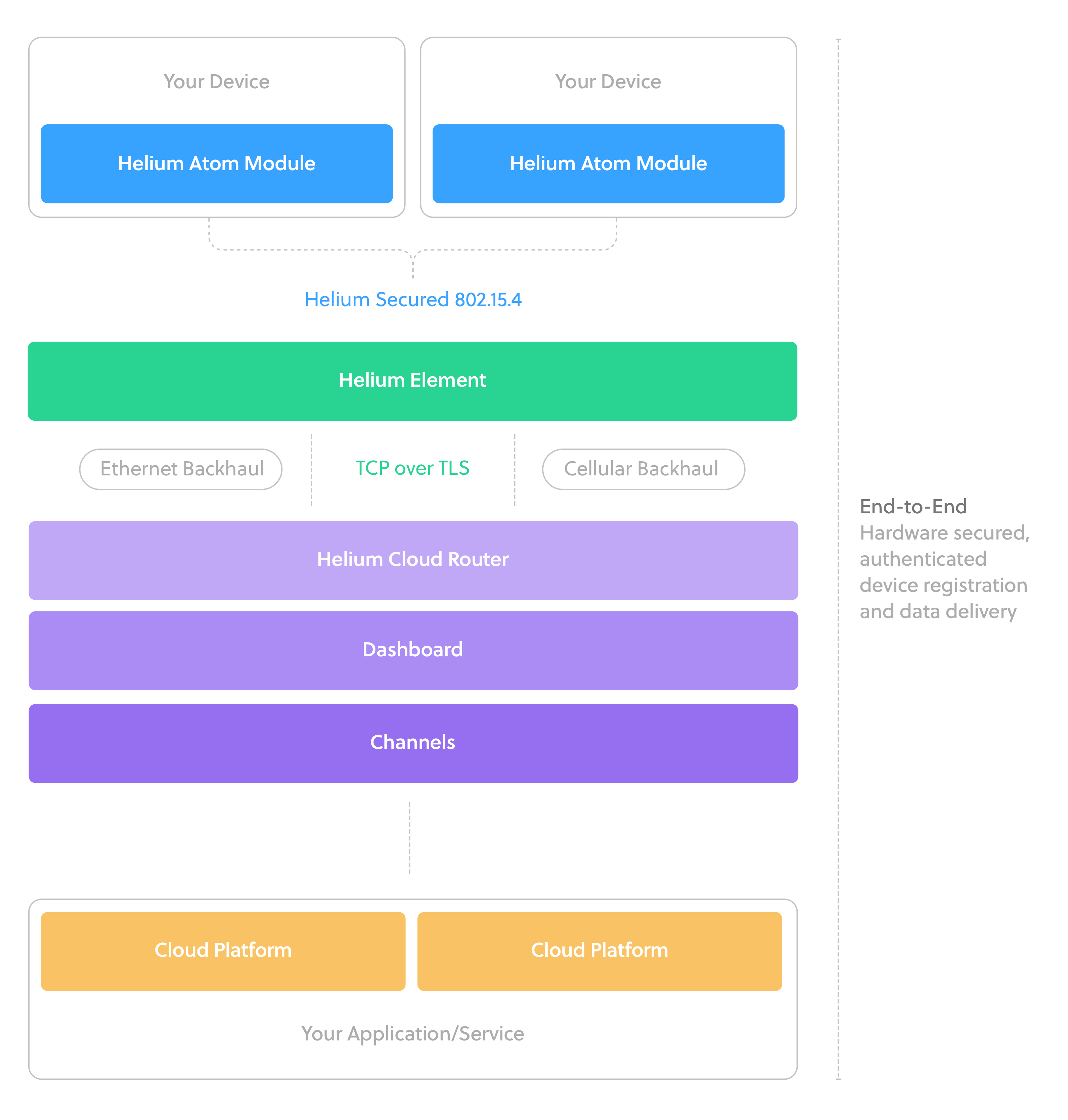
From this point, the application would pretty much work off line, the Deep Learning is capable of running offline in real time. Next we want to connect the information to the internet via Helium IoT.
After that, install the Helium SDK from the Rasperry Pi guide, the Up2 board has Rasperry Pi pin output, making it perfect to run the Rasperry Pi module. After installing the Movidius PCIe addon and Helium Pi Add on, the Up2 Board should now perfectly fit into it's box like Below
Afterwards, we will install the board.
https://www.helium.com/dev/hardware-libraries/raspberry-pi
For up2 board, there is a little difference here that we need to address. We will be using "/dev/ttyS5", and we need to be in dialout permission setting in terminal, otherwise we'd have to use sudo
sudo adduser up2 dialout
cd ~/workspace/
git clone --recursive https://github.com/helium/helium-cli.git
cd helium-cli
make
./helium -p /dev/ttyS5 info
This would show you whether your Helium is running correctly. On Helium Dashboard, make sure that you activate Atom
After Atom, make sure to add Hub to Helium Element as well
Once brought online, we can actually see the device being online
After this is all set, we can simply add in the code, first we need to install the library on up2 board for python3 since NCS SDK is running on python3
sudo pip3 install helium-client
Afterwards we need to add to our cleanwaterai.py. Currently there is a bug on running this, as we need 'ttyS5' on Up2 board, and 'Serial0' if you were to use Raspberry Pi. Also, the python3 code needs byte array rather than String, so we need to add b'{string}' format to make this work.
from helium_client import Helium
helium = Helium(b'/dev/
helium.connect()
channel = helium.create_channel("Clean Water AI")
def postprocess(output):
""" postprocess an inference result
input - in the format produced by the graph
output - in a human readable format
"""
order = output.argsort()
last = len(gNetworkCategories)-1
text = gNetworkCategories[order[last-0]] + ' (' + '{0:.2f}'.format(output[order[last-0]]*100) + '%) '
channel.send(b'confidence=' '{0:.2f}'.format(output[order[last-0]]*100) + '&detection=' + gNetworkCategories[order[last-0]])
return text
Now the data should be able to upload upstream without any problem, we will need to store it so that we can run track the result as well do additional logic.
Step 8: Connect Azure IoT Hub to Helium DashboardWe first create IoT Hub under all services, it would be wise to move IoT Hub into favorite so it would be accessed much more easier. We can use standard tier since the Free Trial $200 trial credit can cover it. You can also choose to use the Free Tier as well.
After selection the name you can move to Size and Scale.
Size and Scale
After it's created we need to go to Shared Access Policies ->RegistryReadWrite entry -> Connection String -- Primary Key, also make sure Registry Read and Registry Write is checked, although they should be default
After getting that primary connection string, go to Helium Dashboard and create a Helium Connection, after pasting the connection string into the connection field, everything else should be automatically filled.
After setting this up, we would be able to get all the MQTT strings being automatically generated in Helium Hub. This can be easily accessed through the channel.
Since Azure requires device to publish and subscribe to a fixed MQTT topic, this will allow Helium Atom to do that as well as letting IoT Hub to push messages to Helium Atom. We can do following to test out the sending to Azure.
git clone https://github.com/helium/helium-cli.gitcd helium-climake./helium -p /dev/
That will check whether Helium is installed correctly
./helium -p /dev/serial0 channel create "Azure IoT App"
./helium -p /dev/serial0 channel send 1 "Hello Azure"
And on Azure IoT Hub below we should see the same result
Device is authenticated through X509, and Helium platform handles all of it. Making it simple and clean.
Step 9: Setup Azure SQL DatabaseNext we need to be able to store the data coming from IoT device. There is a great guide about this written in detail on https://blogs.msdn.microsoft.com/sqlserverstorageengine/2018/01/23/working-with-azure-iot-data-in-azure-sql-database/ In this article we will focus on quick integration of how that happens. We first go to SQL databases to create a database as image below, we can select Basic Tier as we are only starting the app, the free trial credit should be able to cover it. This is the cheapest optionfor prototyping, as you scale, you might want to move to Azure Cosmos in the future since the minimum on Cosmos is $25.
Afterwards we can use Query editor to create following table, for starter we are just gona use Clean Water AI's simple data structure to get started
CREATE TABLE IoTData (
id bigint IDENTITY (1,1) NOT NULL,
Type nvarchar(max) NOT NULL,
Confidence int NOT NULL,
DateCreated datetime default CURRENT_TIMESTAMP
)
Now we have a table to store the data to, we need to connect this to an eventhub so that data can be stored in. Go to Connection Strings and grab the connection string for the next step.
In order to connect to function we will use Event Hub. We first need to create an Azure Function App, which allows serverless structure, which is great for IoT applications since we no longer have to maintain. To start we first need to create a function App under compute.
We can create Function under these settings
Just take about a couple of minutes and we will have it under our notifications.
Now that we have functions, Next we will create a function under IoT Hub (Event Hub) trigger so we can get the event hub running. Go to function->platform features->Application settings
In here we are going to add the connection string we've created in the previous step. Save it after created
Next step is create a Event Hub function, for this example we will use C#. After clicking new connection things should be auto populated.
Change the Function to following, this is to to insert data directly into Azure SQL Database.
using System.Configuration;
using System.Data.SqlClient;
using System.Threading.Tasks;
public static async Task Run(string myIoTHubMessage, TraceWriter log)
{
var map = myIoTHubMessage.Split('&').Select(x => x.Split('=')).ToDictionary(x => x[0], x => x[1]);
String Type = map["Type"];
String Confidence = map["Confidence"];
log.Info(Type);
log.Info(Confidence);
var str = ConfigurationManager.ConnectionStrings["sqldb_connection"].ConnectionString;
using (SqlConnection conn = new SqlConnection(str))
{
conn.Open();
var text = "INSERT INTO dbo.IoTData (Type, Confidence) VALUES ('" + Type + "', " + Confidence + ");";
using (SqlCommand cmd = new SqlCommand(text, conn))
{
// Execute the command and log the # rows affected.
var rows = await cmd.ExecuteNonQueryAsync();
log.Info($"{rows} rows were updated");
}
}
log.Info($"C# IoT Hub trigger function processed a message: {myIoTHubMessage}");
}
When successful, you should be able to see
At this point we have the entire end to end data sending from Helium to Azure SQL via Azure IoT Hub. Next we need to retrieve the data, which we need to create an HTTP Trigger via Azure Function API.
We will change couple of values, routing to be /data so we can access /api/data, and Authorization level to be anonymous, and HTTP method for GET only
As for the code, we can test it out by accessing address
http://<yourapp>.azurewebsites.net/api/data?name=foobar&code=<functionkey>
This would test out the result and return "hello foobar". When this is finished, we can use following code to return the actual data. Next we can use following code to test out the entire app. This is the simplest query, which additional information can be gathered by writing more complex queries, but for prototype we will just focus on getting one record.
#r "System.Configuration"
#r "System.Data"
#r "Newtonsoft.Json"
using System;
using System.Net;
using System.Configuration;
using System.Data.SqlClient;
using System.Threading.Tasks;
using System.Text;
using Newtonsoft.Json;
public static async Task<HttpResponseMessage> Run(HttpRequestMessage req, TraceWriter log)
{
log.Info("C# HTTP trigger function processed a request.");
var str = ConfigurationManager.ConnectionStrings["sqldb_connection"].ConnectionString;
using (SqlConnection conn = new SqlConnection(str))
{
conn.Open();
var text = "SELECT Top 1 Type, Confidence from dbo.IoTData Order by DateCreated DESC";
EventData ret = new EventData();
using (SqlCommand cmd = new SqlCommand(text, conn))
{
SqlDataReader reader = await cmd.ExecuteReaderAsync();
try
{
while (reader.Read())
{
log.Info(String.Format("{0}, {1}",
reader[0], reader[1]));
ret.Type = (string)reader[0];
ret.Confidence = (int)reader[1];
}
}
finally
{
// Always call Close when done reading.
reader.Close();
}
var json = JsonConvert.SerializeObject(ret, Formatting.Indented);
return new HttpResponseMessage(HttpStatusCode.OK)
{
Content = new StringContent(json, Encoding.UTF8, "application/json")
};
}
}
}
public class EventData
{
public String Type { get; set; }
public int Confidence { get; set; }
}
When all done, it should yield result for the latest record
We now have IoT inside Azure from end to end, only thing left is display the data, use following code to get the latest data which can be displayed over the webpages on Azure Map.
You can easily access the data via
http://<yourapp>.azurewebsites.net/api/data?code=<functionkey>
<html>
<link rel="stylesheet" href="https://atlas.microsoft.com/sdk/css/atlas.min.css?api-version=1" type="text/css" />
<script src="https://atlas.microsoft.com/sdk/js/atlas.min.js?api-version=1"></script>
<link rel="stylesheet" href="style.css" type="text/css" />
<script src="jquery-3.2.1.js"></script>
<body>
<div id="map"></div>
<script type="text/javascript">
/* Instantiate map to the div with id "map" */
var mapCenterPosition = [-122.492393, 37.7265926];
var map = new atlas.Map("map", {
"subscription-key": "tTk1JVEaeNvDkxxnxHm9cYaCvqlOq1u-fXTvyXn2XkA",
center: mapCenterPosition,
zoom: 13
});
/* Create a custom html*/
var waterpin1 = document.createElement('div');
waterpin1.classList.add("ms-pin");
var location1 = [-122.4900376, 37.7355901];
/* Add the custom html to the map*/
map.addHtml(waterpin1, location1);
var waterpin2 = document.createElement('div');
waterpin2.classList.add("ms-pin");
var location2 = [-122.492393, 37.7265926];
/* Add the custom html to the map*/
map.addHtml(waterpin2, location2);
function checkResult() {
var url = "http://<yourapp>.azurewebsites.net/api/data?code=<functionkey>";
var data = {};
function success(data) {
console.log("result: ", data);
if ("contaminated" == data) {
waterpin1.style.backgroundImage = "url('contaminated.png')";
}
else
{
waterpin1.style.backgroundImage = "url('water.png')";
}
}
$.ajax({
url: url,
success: success,
});
}
setInterval(checkResult, 5000);
</script>
</body>
</html>
From that, we can get the data and use html to display the data as needed. Using Azure Maps or other maps, we can easily display the following through calling the API. the code for index.html will be in our github repo. In the future we can classify more bacteria and display them across the map, and use pattern recognition to figure out where the contamination starts.
NASA World Wind
If you are interested in a bit more map features, we can use NASA's World Wind which is built using React Native.
Within the file, we can use the exact same Microsoft Azure Function API that we've built to grab the data in sync. A copy of the source code is being stored inside nasa_arcgis under clean_water_ai repo.
You can do it by going through
git clone https://github.com/Nyceane/clean_water_ai.git
cd clean_water_ai/nasa_arcgis
npm install
npm start
A preview of the system can be seen at https://cleanwaterai.github.io can be seen like the image below.
Since building of the project, we've been invited to give demos at AIDC, CVPR and Intel DevJam, we plan to classify more bacteria through Single Shot Detection as well as build microscopic camera within the IoT in the near future. If you are interested please feel free to sign up at http://www.cleanwaterai.com








{kind=link}
Comments