


Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
In this project performs how to run Keras model to modus toolbox ML library for simple voice command recognition. The keras output model will be synthesized using Modus toolbox ML to get the compatible model library as described in the image below.
Our simple voice command model are generated using tensorflow - keras for machine learning, the default example on how to do training for voice command is described in this article.
Collecting the DatasetThis training required dataset to be trained to create the ML model for the hardware. The dataset can be collected easily from several sources. For this project, simple voice command dataset from google is required.
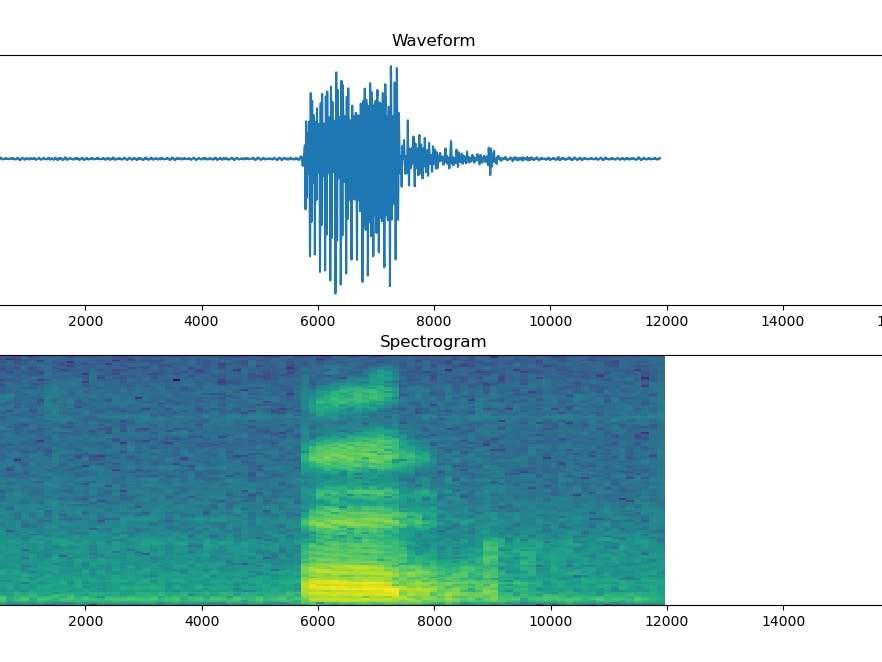
Picture below shown how to represent the waveform of dateset audio. we can represent the audio voice into waveform using tf.audio.decode_wav. then save data into a waveform. The data then plotted into graph using matplotlib.
audio_binary = tf.io.read_file(file_path) # read dataset file
waveform = decode_audio(audio_binary) # decode audio wave
#plot the waveform
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()After dataset collected, it need a preprocessing before trained, it used this code below. The dataset are divided into three parts, for training, evaluation and test. need to notice that the supported version of keras/tensorflow is below 2.5.0. The Modus toolbox did not support keras above 2.5.0.
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(get_waveform_and_label, num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
get_spectrogram_and_label_id, num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)Since it run on microcontroller with small size of RAM, it requires model size as small as possible and not oversizing the RAM. otherwise, it will showing error. The suitable model training setting is shown on code below.
model = models.Sequential([
layers.Input(shape=input_shape),
#preprocessing.Resizing(32, 32),
#norm_layer,
layers.Conv2D(4, 3, activation='relu'),
layers.Conv2D(4, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.10),
layers.Flatten(),
layers.Dense(4, activation='relu'),
layers.Dropout(0.20),
layers.Dense(num_labels),
])Result of training our model shown in figure below, training graph result of loss vs epoch.
The result for evaluation and test of the model shown in this figure below. In prediction, since the trained model must be small as possible, it is almost impossible to create model with high prediction.
The test result show for the prediction of command "no" showing the highest value of prediction, but the other words also showing a significant prediction value.
The trained keras model that has been created, need to be converted into ML Library, So the MCU can syntesized the model. Converting the model need ML Configurator. Filesize of model is less than 1 Mb ( ~700kb) is able to work with converter. Due to limited size of memory, over than 1 Mb might be showing memory overflow.
Since our model converted to MCU, it needs to be called in the program using mtb_ml_stream_init() function. And we can use the instant library to call the AI inferencing function.
mtb_ml_model_bin_t model_bin = {MTB_ML_MODEL_BIN_DATA(MODEL_NAME)};
mtb_ml_stream_interface_t interface = {CY_ML_INTERFACE_UART, &cy_retarget_io_uart_obj};
result = mtb_ml_stream_init(&interface, PROFILE_CONFIGURATION, &model_bin);
////////// Call the AI Inferencing task
result = mtb_ml_stream_task();To be able to detect if implemented model run accordingly, we can perform validation on target, where the Modus toolbox will send random value to MCU and get the respond.
The hardware successfully running trained voice recognition model that build using tensorflow-keras (version below 2.5.0). The functional of hardware is also validated using validation on ML Configurator and it shows PASS on several validation option (16x8 and 16x16).
Future WorksThe voice input from digital mic sensor can't be processed directly using the hardware library since the ML Configurator did not support WAV data to be processed. This project is halfway through, since the sound input (WAV) can't be read. Reading voice input data, convert into WAV file, and processing the audio data need to be held in future project.
https://infineon.github.io/ml-inference/html/group__API.html
https://github.com/mkvenkit/simple_audio_pi/blob/main/simple_audio_train_numpy.ipynb




Comments
Please log in or sign up to comment.