




Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
There are hardcore expensive collision detection and avoidance systems available to use for autonomous systems. Such detection and avoidance systems consist of LIDAR, DJI Guidance module, etc. But they tend to work on top of highly sophisticated and expensive hardware and software requiring high power computations, lidar setup, etc. But this setup is not suitable for considerably small robots, especially drones and rovers which rely on limited computational power and resources.
With this project, we try to bridge this gap. By using low cost and immediately available parts, we are developing a robust, yet powerful collision detection system for the purpose of small robots such as drones, rover, etc. This will cost only a fraction of the setup used in sophisticated systems, and without compromising on performance, scalability, and reliability.
Use-caseAn example use case is for swarm robotics. Our implementation allows the participating robots to be connected to an IoT network and communicate with each other for better planning an evasive maneuver.
NoveltyExisting solutions that are similar to this use either low-performance computing modules or a ground station based remote processing system. Both these solutions allow neither an efficient computing nor AI at the edge processing for better performance. The main advantage of our implementation is that it can be scaled up easily to be incorporated on large and advanced autonomous vehicles such as driverless cars, drone transports, etc. It also removes the drawbacks of the existing solutions by implementing at the edge computing without compromising on the performance.
The workflow will be split into two parts:
- StereoDepth based distance sensing using OpenCV
- MonoDepth based distance sensing using OpenVINO toolkit
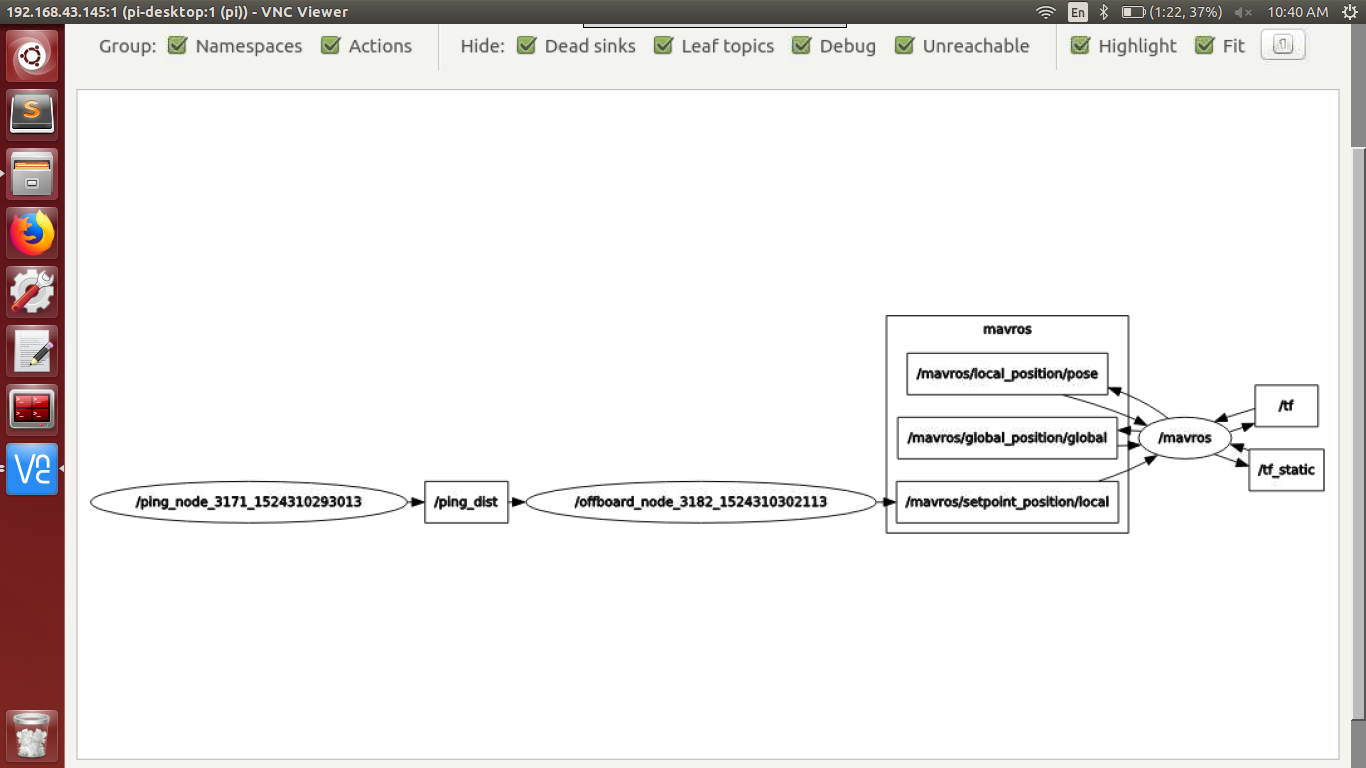
The interface that acts as a link between the hardware and the software is the ROS or Robot Operating System. This interface will take care of the message translations between various internal and external units of the system. ROS provides low-level device control and hardware abstraction. ROS enables us to read data from a variety of sensors to manipulate it and provide a computed output. It comprises of a number of independent nodes, each of which communicates with the other node using the publish /subscribe messaging model.
A node can be considered as the basic unit in ROS. There can be nodes for each task, such as taking images from a camera, processing the image, driving a motor, etc. They are in charge of handling the devices and their interfaces. All the nodes are registered to a master ROS server called as roscore. It is similar to a lookup table where all the nodes go to find where exactly to exchange messages. When a node registers itself to the master, it also tells to what topics it will publish and what topics it will subscribe to.
A topic is a stream of data in a particular structure that is used to exchange messages or information between the nodes. Example of the topic is String, Float32, PoseStamped, etc. Each topic will have a unique name and a particular message structure. A node can subscribe and publish to a number of unique topics. However, it cannot subscribe and publish on the same topic.
The two-way communication between the nodes takes place via services. It resembles a client-server model where one node will register to the service of another node. The client node will request some data to the server node and the server node will respond to the request by providing the required information to the client node.
- Concept and background
A normal camera uses the pinhole concept. There the points in 3D are transformed and converted into points in 2D. This causes a loss of depth information from the scenes. Say, if we have x,y, and z coordinate points in space, where z being the depth, the pinhole or 2D camera only registers the x and y information and discards z.
The concept of stereo vision is originated for the vision of human eyes. The human eyes are placed at an average distance of 6cm apart. Each of our eyes receives a 2D image of the scene. Each of this 2D image is different and varies at an angle according to the eye that receives the scene. These 2D images are sent to our brain who interprets these images through fusion. The disparity information is then extracted which gives us a perspective of the scene in 3D. Multiview geometry is closely linked to epipolar geometry.
Stereo processing involves the processing of a calibrated pair of pictures obtained from a stereo camera. Since the stereo images are taken at different angles, the information contained in both the images associated with a particular scene in 3D can be used to produce a depth map.
The images that we get from the cameras are just unrectified images. They are not compensated for the horizontal and vertical alignment. Rectification is done to making the image streams from both the cameras to be aligned horizontally and vertically. It involves the transformation of the projected image into a common plane.
The fundamental matrix (F) and Essential matrix (E) are formed to rectify the image. The fundamental matrix relate the two cameras in their pixel coordinates. By matching points from both the images, a point in one image is mapped to the epiline in the other image. The essential matrix gives information relating to the position of the second camera with respect to the first one in real 3D coordinates. Image rectification ultimately warps both the images in such a way that they appear as if they have been taken with only a horizontal displacement. This process makes all the epilines to be perfectly horizontal. After the rectification, each of the cameras has to be calibrated for use as a stereo pair.
A custom stereo camera was made from two Microsoft HD webcams and was calibrated.
This stereo camera employs two cameras of the same model for taking the 2D image of the scene from different angles and perspectives. It simulates the binocular vision. The distance between the cameras in a stereo camera will be approximately the same as that of the distance between the human eyes. These stereo cameras are then connected to Raspberry Pi via USB ports. The cameras will be assigned names /dev/video0 and /dev/video1 by the Raspberry pi.
Camera calibration involves obtaining the intrinsic and extrinsic parameters of the cameras done using the pinhole camera concept. A pinhole camera is a small camera with a small hole installed in place of the lens. The aperture hole allows the light rays to pass through, producing an inverted image on the opposite side of the camera. This effectively converts the 3D image into a 2D image.
A camera matrix of size 4x3 represents the camera parameters. This matrix maps the 3D scene on to the 2D surface. The calibration program calculates the camera matrix using the intrinsic and extrinsic parameters. The intrinsic parameters involve the determination of the optic center, skew coefficient, and the focal length of the camera. Extrinsic parameters deal with the location of the camera in the 3D environment, giving the relative position and orientation of the two cameras.
The intrinsic camera matrix, K is defined as:
The extrinsic parameter consists of a rotation parameter, R, and a translation parameter, t. The optic center is always considered as the origin of the camera coordinates. This transforms the 3D coordinate system in real-world to the 3D coordinate system of the camera.
The intrinsic parameters then finally transform the projected camera 3D coordinates into 2D image coordinates.
Due to the use of the pinhole camera concept, various types of distortions like radial and tangential distortion 50 are skipped. However, in a real-world camera, due to the use of the lens, these distortions are also considered while calibration. Radial distortion is caused by more bending of light rays at the edge of the lens than at the optic center. Tangential distortion usually occurs if the image plane and the lens are not parallel to each other.
The camera image parameters are set using the flags CAP_PROP_FRAME_WIDTH and CAP_PROP_FRAME_HEIGHT. The figure below shows the sample test images that were taken for calibration. The images were taken with a chessboard of 8x6 size.
These chessboard picture pairs will be used to detect the corners and use these corners to calibrate the two cameras. findChessboardCorners() and calibrateCamera() methods will be used in this process. A maximum of 64 image pairs containing the chessboard in the scene is chosen at random taken for the calibration. The determination of rotation and vertical offset between the two cameras is computed by the function stereoCalibrate().
After the calibration, the calibration data is stored as a NumPy array for future reference and calculation of a depth map.
- Depth calculation / Obstacle detection
For depth calculation, we take the help of epipolar geometry. Disparity, the distance between the cameras and focal length of the cameras needs to obtained in order to calculate the depth. The disparity can also be defined as the distance between the corresponding points when two images are superimposed. The disparity map generates the disparity of all the points in the scene.
The disparity between the two images are usually calculated via a block matching algorithm. These stereo images have to be rectified to account for the horizontal alignment. Simply saying, block matching is the process of taking a test portion (pixels bounded by a region, known as a template) in either of the image (reference image) and searching for the closest match among pixels bounded by similar region (block) in the other image (target image). Initially, the search starts at the same coordinates on the target image, like that on the reference image. Since the images are rectified in the previous steps, the corresponding pixels of both images lie in the same horizontal levels. The matching algorithm will swipe through the target image towards the left or right until it finds an appropriate match. For ease of computation, the images are converted into their corresponding greyscale, which limits the search to a range of (0,255) in the pixel values.
When it finds a match, the disparity will be the difference in the values of the centroids of the search boxes used. The closest matching block is computed using the method called Sum of Absolute Differences or SAD. In this method, each pixel value of the template is subtracted from the corresponding pixel value of the block. The absolute value of this difference is taken and it is summed up with the differences calculated between the rest of the pixels from template and block.
The resulting single value determines the similarity between the template and the block. If the SAD value is low (minimum cost), the mages are more similar. Else, they may be dissimilar. For computing the best similarity, after computing the SAD, the block with the lowest SAD value is chosen. The maximum disparity will determine how far we need to search horizontally until a match is found. In addition, the template size will determine the amount of matching and SAD calculation being done on the image pair. The larger the template, the less noise will be present while generating the disparity map. For accurate subpixel measurements, minimum cost, as well as neighboring cost values, will be considered for the match.
The noise can be further reduced by tuning the parameters numDisparities and blockSize. An example of a disparity image obtained from left and right stereo images.
Disparity mapping was carried out to formulate the depth from the scene and thus detect obstacles.
From Intel, The OpenVINO™ toolkit is a comprehensive toolkit for quickly developing applications and solutions that emulate human vision. Based on Convolutional Neural Networks (CNNs), the toolkit extends CV workloads across Intel® hardware, maximizing performance. Install the Linux version from here or the Rpi version from this tutorial. I won't be able to repeat all the installation and setup steps to avoid repetition and since it is well documented in the Intel OpenVINO docs.
MonoDepth produces a disparity map for a given input image with edge processing done at an Intel Movidius Compute Stick. As a start, I am using the MonoDepth application from the Intel VINO toolkit.
To be able to build the MonoDepth program, you need to source InferenceEngine and OpenCV environment from a binary package that is available as proprietary distribution.
Please run the following command before the demos build (assuming that the binary package was installed to <INSTALL_DIR>):
source <INSTALL_DIR>/deployment_tools/bin/setupvars.shGo to the directory with the build_demos.sh script and run it:
build_demos.shOr do it manually as:
Navigate to a directory that you have write access to and create a build directory.
mkdir buildGo to the created directory:
cd buildRun CMake to generate the Make files for release or debug configuration:
cmake -DCMAKE_BUILD_TYPE=Debug <open_model_zoo>/demosRun make to build the demos:
makeThe application binaries are in <path_to_build_directory>/intel64/Debug/.
Find and download your required model files here. Weights were additionally uploaded to https://download.01.org/opencv/public_models, OpenVINO Model Downloader uses this location for downloading.
Now we need to optimize the model by converting the Model into an Intermediate Representation (IR). Use the mo.py script from the <INSTALL_DIR>/deployment_tools/model_optimizer directory to run the Model Optimizer and convert the model to the Intermediate Representation (IR). The simplest way to convert a model is to run mo.py with a path to the input model file.
python3 mo.py --input_model INPUT_MODELThe mo.py script is the universal entry point that can deduce the framework that has produced the input model by a standard extension of the model file:
.caffemodel- Caffe* models.pb- TensorFlow* models.params- MXNet* models.onnx- ONNX* models.nnet- Kaldi* models.
I have rented an NCS 2 from a friend to try out the inferences.
For achieving this we use the monodepth program which is already included in as part of the OpenVINO kit. Additional optimization and upgradations are currently in progress. The application outputs are the floating disparity map (PFM) as well as a color-coded version (PNG) and take advantage of the Zero-shot Cross-dataset Transfer principle as described in this paper.
Now let's test our implementation:
First of all, source the Intel workspace.
source /opt/intel/openvino/bin/setupvars.shNow execute the following to run our implementation.
python <path_to_build_directory>/intel64/Debug/monodepth_demo.py -m <path_to_model> -i <input_image> -d <MYRIAD>Here is a snapshot of me holding an Intel NCS2 on a mono camera.
And voila, here is our disparity map of the image taken from a mono camera.
The Intel OpenVINO toolkit can just do wonders like that.
This disparity information is then converted to depth (perception distance) data and fed into the ROS topic for the evasion algorithm.
depth = baseline * focal_length / disparityThe evasion algorithm is carried out in the ROS environment. Here the use case is a drone and appropriate drone maneuver commands are passed for evading the obstacle. MAVROS plugins were used here so that it can be extended to any autonomous vehicle.
{kind=link}


Comments
Please log in or sign up to comment.