



Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
FPGA has an advantage of low latency and powerful computing speed, but FPGA DPU has a specific protocol and can not apply a machine learning model directly. This problem prevents the application of FPGA AI. This project is showing the procedure how to convert a new machine learning model, then train, quantize and compile the model, then run it on ultra96 for the new models of enet, darknet and yolo. The procedure will tell people how to apply a new machine learning model on xilinx FPGA.
Step One: Modifying training modelEnet model:
- Replacing the un-pooling layer with deconvolution layer in the decoder module
- Replacing all PReLU with ReLU
- Removing spatial dropout layers
- Replacing Batchnorm layers with a merged Batchnorm + Scale layer
- Position Batchnorm layers in parallel with ReLU
In UNet-full/Unet-lite models Batchnorm/scale layer combinations were inserted before relu layers (after d0c, d1c, d2c, and d3c) as the DPU doesn't support the data flow from Convolution to both the Concat and relu simultaneously
Densenet model:
- Replacing Stochastic Gradient Descent (SGD) optimizer with RMSProp optimizer
- Using a 3x3 kernel with a stride length of 1 and the first max pooling layer is ommitted due to dataset CIFAR-10
- Replacing GlobalAveragePooling2D with AveragePooling2D + Flatten
Darknet Project directory
Enet Project directory
chkpt_call=ModelCheckpoint(filepath=keras_hdf5+"epoch.{epoch:03d}.val_acc.{val_acc:.2f}.h5", monitor='val_acc',verbose=1,save_best_only=True)
tb_call=TensorBoard(log_dir=tboard,batch_size=batchsize,update_freq='epoch')
lr_scheduler_call=LearningRateScheduler(schedule=step_decay, verbose=1)
lr_plateau_call=ReduceLROnPlateau(factor=np.sqrt(0.1),cooldown=0,patience=5, min_lr=0.5e-6)
callbacks_list = [tb_call, lr_scheduler_call, lr_plateau_call, chkpt_call]Saving and Keeping Training Program
model_path=keras_hdf5
listfile = [i for i in os.listdir(model_path) if i.endswith("h5")]
print("listfile = {}".format(listfile))
# model sorting
listfile.sort()
# model reversing sorting
listfile=listfile[::-1]
print("listfile = {}".format(listfile))
if len(listfile) != 0:
# taking the latest model
model_path = model_path + listfile[0]
model = load_model(model_path)
initial_epoch=int(listfile[0].split(".")[1])
print("initial_epoch = %d"%int(initial_epoch))
else:
# if there is not any trained model, producing new model and setting epoch = 0
model = densenetx(input_shape=(input_height,input_width,input_chan),classes=10,theta=0.5,drop_rate=0.2,k=12,convlayers=[16,16,16])
initial_epoch = 0Entering VITIS-AI GPU Image
Starting Training
(vitis-ai-tensorflow)john@john-wang:/workspace/DenseNet3/trainrestore/trainrestore$source setenv.sh
(vitis-ai-tensorflow)john@john-wang:/workspace/DenseNet3/trainrestore/trainrestore$./trainrestore.shNote: The first command is source setenv.sh rather than ./setenv.sh,because ./ command is only valid in the temperate shell created. Here Batchsize is 50, which should be set by your computer RAM.
Tensorboard Result
john@john-wang:~/Vitis-AI_1.2/DenseNet3/trainrestore/trainrestore/build$ tensorboard --logdir=tb_logstb_logs is the saving directory of tensorboard data and this command is run in the upper directory, otherwise request full directory.
Accuracy:
Loss:
Vitis AI tool can not recept Keras checkpoints,and need to convert to the frozen model compatible with TensorFlow.
Two Steps:
1. Convert HDF5 file to TensorFlow checkpoint.
2. Frozen TensorFlow checkpoint.
./2_keras2tf.sh'frozen_graph.pb' will be put in ./files/build/freeze.
./3_eval_frozen.shjohn@john-wang:~/Vitis-AI_1.2/YOLOv3/example_yolov3$ bash 0_convert.sh
$ python ../yolo_convert.py \
0_model_darknet/yolov3.cfg 0_model_darknet/yolov3.weights
1_model_caffe/v3.prototxt 1_model_caffe/v3.caffemodel
$ python ../yolo.py
0_model_darknet/yolov3-tiny.cfg 0_model_darknet/yolov3-tiny.weights
1_model_caffe/v3-tiny.prototxt 1_model_caffe/v3-tiny.caffemodelPrj_config文件
Ultra96.json
DPU Utilization
Densenet Kernel:
BOARD=Ultra96
MODEL_NAME=tf_densenet_imagenet_30_30_7.7G
MODEL_UNZIP=${MODEL_NAME}
vai_c_tensorflow \
--frozen_pb ${MODEL_UNZIP}/quantized/deploy_model.pb \
--arch /opt/vitis_ai/compiler/arch/dpuv2/${BOARD}/${BOARD}.json \
--output_dir ./model \
--net_name tf_${MODEL}Prepare compilation
$ cd example_yolov3
$ cp 1_model_caffe/v3.caffemodel ./2_model_for_quantize/Quantizing Yolov3 Kernel
(vitis-ai-caffe) john@john-virtual-machine:/workspace/YOLOv3/example_yolov3$vai_q_caffe quantize -model 2_model_for_quantize/v3.prototxt -weights 2_model_for_quantize/v3.caffemodel -sigmoided_layers layer81-conv,layer93-conv,layer105-conv -output_dir 3_model_after_quantizeQuantizing Yolov3-tiny Kernel
(vitis-ai-caffe) john@john-virtual-machine:/workspace/YOLOv3/example_yolov3$ vai_q_caffe quantize -model 2_model_for_quantize/v3-tiny.prototxt -weights 2_model_for_quantize/v3-tiny.caffemodel -sigmoided_layers layer15-conv,layer22-conv -output_dir 3_model_after_quantize
BOARD=Ultra96
MODEL_NAME=tf_yolov3_voc_416_416_65.63G
MODEL_UNZIP=${MODEL_NAME}
vai_c_tensorflow \
--frozen_pb ${MODEL_UNZIP}/quantized/deploy_model.pb \
--arch /opt/vitis_ai/compiler/arch/dpuv2/${BOARD}/${BOARD}.json \
--output_dir ./model \
--net_name tf_${MODEL}
BOARD=Ultra96
MODEL_NAME=tf_yolov3_voc_416_416_65.63G
MODEL_UNZIP=${MODEL_NAME}
vai_c_tensorflow \
--frozen_pb ${MODEL_UNZIP}/quantized/deploy_model.pb \
--arch /opt/vitis_ai/compiler/arch/dpuv2/${BOARD}/${BOARD}.json \
--output_dir ./model \
--net_name tf_${MODEL}Ultra96 Densenet Project Directory
Ultra96 Yolo Project Directory
Running Densenet Model
Ultra96 Integrated System
Image Target Detection
Yolov3 Target Dectection on Spot
Running Enet Model on Ultra96
Debugging on Ultra96
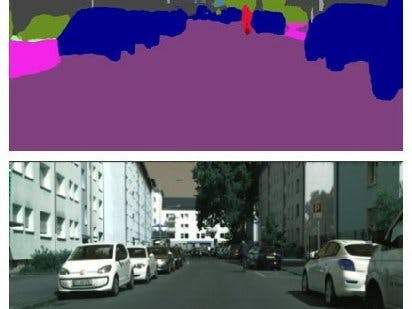
Segmentation Picture 1
Segmentation Picture 2
Segmentation Picture 3
PYNQ Design Flow
https://www.bilibili.com/video/BV1NX4y1u775/
If you can not open the video below, pls double click the link above.



Comments
Please log in or sign up to comment.