


Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
.png?auto=compress%2Cformat&w=48&h=48&fit=fill&bg=ffffff) |
| |||||
- 🎉 What's New
- 📚 Introduction
- ⚙️ Installation
- 🔖 Docker
- 💡 Prerequisites
- 🛠️ Buil
- ✏️ Tutorial🧨 Quick Start1. Data Preparation2. Model Preparation3. Building the Engine4. DeepStream
- 🪄 Applications
- 💻 Overview of Benchmark and Model Zoo
- 📖 Document
- ❓ FAQ
- 🧾 License
- 🎯 Reference
✨v0.1.0 First release on March 10, 2024:
- JetYOLO is born!
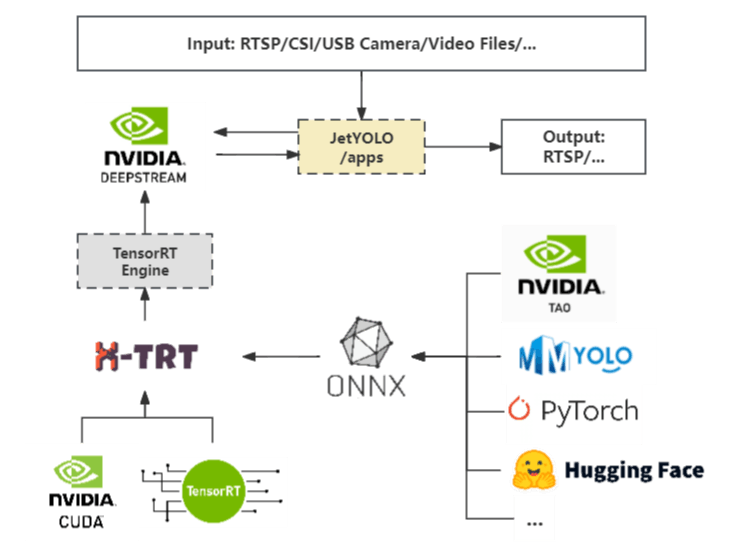
This project leverages the DeepStream toolkit along with NVIDIA's CUDA and TensorRT to effortlessly create real-time streaming analytics applications for a broad range of scenarios. Aimed at lowering the barrier to entry for developers, it offers a lightweight, intuitive platform that simplifies the entire development cycle of DeepStream applications, encompassing model deployment, inference, and TensorRT optimization. Key features include:
- Ease of Use: Reduces project complexity, enabling quick startup and rapid development. Each component follows a modular design for further decoupling, allowing every tool and application to be independently utilized, meeting specific project requirements.
- Comprehensive Toolkit: Includes all necessary tools for developing high-performance inference applications in edge computing, offering a suite from model export to modification, quantization, deployment, and optimization, ensuring a smooth development process and efficient model operation.
- High-Performance Inference: We've also developed a high-efficiency inference framework, xtrt, based on NVIDIA TensorRT and CUDA, integrated with NVIDIA Polygraph,ONNX GraphSurgeon, and the PPQ quantization tool, among others. This framework features comprehensive model modification, quantization, and performance analysis tools for easy and quick debugging and optimization.
- Practical Case Studies: Provides multiple real-world examples demonstrating the framework's applicability and effectiveness, with minor adjustments needed to fit a wide range of application scenarios.
Our goal is to make the development of streaming analytics applications more accessible to developers of all skill levels, fostering the creation of innovative solutions across various domains.
The JetYOLO project workflow is streamlined and consists of just three steps:
- Start with a Pre-trained Model: Obtain a pre-trained model from common training frameworks and export it as an ONNX file.
- Build the TensorRT Engine with X-TRT: Import the ONNX model into our X-TRT, a lightweight inference tool, to construct a TensorRT engine. Within XTRT, you have the flexibility to customize and modify the ONNX model file, use tools for model quantization scripts to quantize the model, and employ performance analysis tools to test accuracy and optimize the model.
- Integrate with DeepStream for Application Development: Configure the exported Engine file from X-TRT into the DeepStream configuration files for further application development, such as people flow detection, to create tailored applications.
We recommend deploying with Docker for the quickest project startup. Docker images for both X86 architecture and NVIDIA Jetson ARM architecture are provided.
docker build -f docker/[dockerfile]If you prefer to manually configure the environment, please continue reading the section below.
🔖 NVIDIA Jetson Appliances- JetPack SDK >= v5.0.2
- DeepStream >= v6.2
Click to expand to read the detailed environment configuration.
To build the JetYOLO components, you will first need the following software packages.
TensorRT
- TensorRT >= v8.5
DeepStream
- DeepStream >= v6.2
System Packages
- CUDARecommended versions:cuda-12.2.0 + cuDNN-8.8cuda-11.8.0 + cuDNN-8.8
- GNU make >= v4.1
- cmake >= v3.11
- python >= v3.8, <= v3.10.x
- pip >= v19.0
- Essential utilitiesgit,pkg-config,wget
Pytorch(Optional)
- You need the CUDA version of PyTorch. If your device is Jetson, please refer to the Jetson Models Zoo for installation.
If you have completed the above environment setup, you can proceed with the following steps. Building the Basic Inference Framework:
git clone --recurse-submodules https://github.com/gitctrlx/JetYOLO.git
cmake -S . -B build \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_ARCHITECTURES=72 \
-DBUILD_XRT=ON \
-DBUILD_NVDSINFER_CUSTOM_IMPL=ON \
-DBUILD_TOOLS_POLYGON_DRAW=ON \
-DBUILD_APPS_DS_YOLO_DETECT=ON \
-DBUILD_APPS_DS_YOLO_LPR=ON \
-DBUILD_APPS_DS_YOLO_TRACKER=ON
cmake --build buildConfigure your build with the following options to tailor the setup to your needs:
-DCMAKE_BUILD_TYPE=Release: Sets the build type to Release for optimized performance.-DCMAKE_CUDA_ARCHITECTURES=72: Specify the CUDA compute capability (sm) of your host (Jetson Xavier NX: 72).-DBUILD_XRT=ON: Enables the build of xtrt, our lightweight, high-performance inference tool.-DBUILD_NVDSINFER_CUSTOM_IMPL=ON: Determines whether to compile the DeepStream plugin for app applications.-DBUILD_TOOLS_POLYGON_DRAW=ON: Controls the inclusion of the bounding box drawing tool in theapp/ds_yolo_trackerapplication.-DBUILD_APPS_DS_YOLO_DETECT=ON: Determines whether to build theapp/ds_yolo_detectapplication.-DBUILD_APPS_DS_YOLO_LPR=ON: Determines whether to build theapp/ds_yolo_lprapplication.-DBUILD_APPS_DS_YOLO_TRACKER=ON: Determines whether to build theapp/ds_yolo_trackerapplication.
If you are unsure about your CUDA SM version, you can run tools/cudasm.sh to check. For more details, please see FAQ.
We recommend enabling all options for the build. If you encounter errors during compilation, you can selectively disable some options to troubleshoot, or feel free to submit an issue to us. We are more than happy to assist in resolving it.
If you are unsure about your CUDA SM version, you can run tools/cudasm.sh to check. For more details, please see FAQ.We recommend enabling all options for the build. If you encounter errors during compilation, you can selectively disable some options to troubleshoot, or feel free to submit an issue to us. We are more than happy to assist in resolving it.(Optional) If you would like to use the complete set of tools developed in Python, please install the following:
python3 -m pip install xtrt/requirements.txtData is used for calibration during quantization. We plan to use the COCO val dataset for model quantization calibration work. Place the downloaded val2017 dataset in the xtrt/data/coco directory.
xtrt\
└── data
└── coco
├── annotations
└── val2017Place the prepared ONNX file into the weights folder. You can directly download the ONNX weights we have exported from HuggingFace, all weights originate from mmyolo pre-trained weights. You also have the option to configure mmyolo to freely export weights, or use other object detection models to export ONNX. The related code can be found in xtrt/tools/modify_onnx.
There are two formats of ONNX exported by mmyolo. One is an end-to-end ONNX that has added the EfficientNMS node from TensorRT8, and the other is a pure model part that has removed the decode part (including three output results). For detailed content, please see the detailed tutorial document. You can use the ONNX model that has added EfficientNMS, or use the model that has removed the decode part and manually add plugins for acceleration. The related code can be found in xtrt/tools/modify_onnx.
There are two formats of ONNX exported by mmyolo. One is an end-to-end ONNX that has added the3. Building the EngineEfficientNMSnode fromTensorRT8, and the other is a pure model part that has removed the decode part (including three output results). For detailed content, please see the detailed tutorial document. You can use the ONNX model that has addedEfficientNMS, or use the model that has removed the decode part and manually add plugins for acceleration. The related code can be found inxtrt/tools/modify_onnx.
Once the dataset is ready, the next step is to construct the engine. Below is an example for building a YOLOv5s TensorRT engine, with the corresponding code located in scripts/build.sh:
./build/build \
"./weights/yolov5s_trt8.onnx" \ # ONNX Model File Path
"./engine/yolo.plan" \ # TensorRT Engine Save Path
"int8" \ # Quantization Precision
3 \ # TRT Optimization Level
1 1 1 \ # Dynamic Shape Parameters
3 3 3 \
640 640 640 \
640 640 640 \
550 \ # Calibration Iterations
"./data/coco/val2017" \ # Calibration Dataset Path
"./data/coco/filelist.txt" \ # Calibration Image List
"./engine/int8Cache/int8.cache" \ # Calibration File Save Path
true \ # Timing Cache Usage
false \ # Ignore Timing Cache Mismatch
"./engine/timingCache/timing.cache"# Timing Cache Save PathFor a detailed analysis of the code's parameters, please see the detailed documentation.
Verify the engine: Executing Inference(xtrt's inference demo)
Note: Run the demo to test if the engine was built successfully.
- demo-1: Inferencing a single image using the built YOLO TensorRT engine.
./build/yolo_det_img \
"engine/yolo_m.plan" \ # TensorRT Engine Save Path
"media/demo.jpg" \ # Input Image Path
"output/output.jpg"\ # Output Image Path
2 \ # Pre-processing Pipeline
1 3 640 640 # Input Model Tensor Values- demo-2: Inferencing a video using the built YOLO TensorRT engine.
./build/yolo_det \
"engine/yolo_trt8.plan" \ # TensorRT Engine Save Path
"media/c3.mp4" \ # Input Image Path
"output/output.mp4"\ # Output Image Path
2 \ # Pre-processing Pipeline
1 3 640 640 # Input Model Tensor ValuesThen you can find the output results in the xtrt/output folder.
For a detailed analysis of the code's parameters, please see the detailed documentation.
For a detailed analysis of the code's parameters, please see the detailed documentation.4. DeepStream
Next, you can use DeepStream to build end-to-end, AI-driven applications for analyzing video and sensor data.
Quick Start
- You can quickly launch a DeepStream application using deepStream-app:
Before running the code below, please make sure that you have built the engine file using xtrt, meaning you have completed the section 3. Building the Engine.
deepstream-app -c deepstream_app_config.txtNote: If you wish to start directly from this step, please ensure that you have completed the following preparations:
First, you need to modify the deepstream_app_config.txt configuration file by updating the engine file path to reflect your actual engine file path. Given that the engine is built within xtrt, you will find the engine file within the xtrt/engine directory. In addition to this, it is crucial to verify that the path to your plugin has been properly compiled. By default, the plugin code resides in the nvdsinfer_custom_impl folder, while the compiled plugin .so files can be found in the build/nvdsinfer_custom_impl directory.
Note: If you wish to start directly from this step, please ensure that you have completed the following preparations:First, you need to modify thedeepstream_app_config.txtconfiguration file by updating the engine file path to reflect your actual engine file path. Given that the engine is built within xtrt, you will find the engine file within thextrt/enginedirectory. In addition to this, it is crucial to verify that the path to your plugin has been properly compiled. By default, the plugin code resides in thenvdsinfer_custom_implfolder, while the compiled plugin.sofiles can be found in thebuild/nvdsinfer_custom_impldirectory.
- Alternatively, you can run the following code to view an example of the detection inference:
./build/apps/ds_yolo_detect/ds_detect file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4Note:
The command to run is: ./build/apps/ds_yolo_tracker/ds_tracker_app [Your video file path or RTSP stream URL]
Display Contents:
- The top left corner shows the current frame's pedestrian and vehicle count.
- Detected individuals and vehicles within the frame will be marked with bounding boxes.
Note:The command to run is: ./build/apps/ds_yolo_tracker/ds_tracker_app [Your video file path or RTSP stream URL]
Display Contents:The top left corner shows the current frame's pedestrian and vehicle count.Detected individuals and vehicles within the frame will be marked with bounding boxes.This example is based on the app/ds_yolo_detect directory, showcasing its processing pipeline as illustrated below:
Upon running the application, you can view the output stream on players like VLC by entering: rtsp://[IP address of the device running the application]:8554/ds-test. This allows you to see:
**Note:**The streamed video output can be viewed on any device within the same local network.
**Note:**The streamed video output can be viewed on any device within the same local network.
We also provide some example applications created with deepstream, located in the app folder.
This feature enables real-time tracking and boundary detection for individuals and vehicles using a single video stream. The application utilizes DeepStream for efficient processing.
This example is based on the app/ds_yolo_tracker directory, showcasing its processing pipeline as illustrated below:
To view an inference example, execute the following command:
./build/apps/ds_yolo_tracker/ds_tracker_app file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4Usage:
./build/apps/ds_yolo_tracker/ds_tracker_app [Your video file path or RTSP stream URL]
Display Features:
- The top-left corner shows the total count of pedestrians and vehicles that have passed.
- At the center is a boundary detection box; vehicles crossing this area are highlighted with a red bounding box.
Usage:./build/apps/ds_yolo_tracker/ds_tracker_app [Your video file path or RTSP stream URL]
Display Features:The top-left corner shows the total count of pedestrians and vehicles that have passed.At the center is a boundary detection box; vehicles crossing this area are highlighted with a red bounding box.Upon running the application, you can view the output stream on players like VLC by entering: rtsp://[IP address of the device running the application]:8554/ds-test. This allows you to see:
**Note:**The streamed video output can be viewed on any device within the same local network.
**Note:**The streamed video output can be viewed on any device within the same local network.
This application extends the capabilities of the single-stream inference application to support simultaneous processing and analysis of multiple video streams. It enables efficient monitoring and boundary detection for individuals and vehicles across several feeds, leveraging NVIDIA DeepStream for optimized performance.
This example is based on the app/ds_yolo_tracker directory, showcasing its processing pipeline as illustrated below:
To run the application with multiple video feeds, use the following command syntax:
./build/apps/ds_yolo_tracker/ds_tracker_app_multi file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4 file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4Usage:
./build/apps/ds_yolo_tracker/ds_tracker_app_multi [Video file path or RTSP stream URL 1] [Video file path or RTSP stream URL 2] [...]- note: After compilation, the current program only supports input from two stream addresses. If you wish to facilitate input from more streams, you will need to modify the corresponding code. For details, please refer to the detailed documentation.
Display Features: The application provides a unified display that incorporates elements from all the processed streams.
- Overall Counts: The top-left corner of each video feed display shows the total count of pedestrians and vehicles that have passed within that specific stream.
- Boundary Detection Box: A boundary detection box is presented at the center of each video feed. Vehicles crossing this predefined area in any of the streams are immediately highlighted with a red bounding box to signify a boundary violation.
Usage:./build/apps/ds_yolo_tracker/ds_tracker_app_multi [Video file path or RTSP stream URL 1] [Video file path or RTSP stream URL 2] [...]
note: After compilation, the current program only supports input from two stream addresses. If you wish to facilitate input from more streams, you will need to modify the corresponding code. For details, please refer to the detailed documentation.Display Features: The application provides a unified display that incorporates elements from all the processed streams.Overall Counts: The top-left corner of each video feed display shows the total count of pedestrians and vehicles that have passed within that specific stream.Boundary Detection Box: A boundary detection box is presented at the center of each video feed. Vehicles crossing this predefined area in any of the streams are immediately highlighted with a red bounding box to signify a boundary violation.Upon running the application, you can view the output stream on players like VLC by entering: rtsp://[IP address of the device running the application]:8554/ds-test. This allows you to see:
**Note:**The streamed video output can be viewed on any device within the same local network.
**Note:**The streamed video output can be viewed on any device within the same local network.
The DeepStream application offers a comprehensive solution for detecting and recognizing license plates in real-time.
This example is based on the app/ds_yolo_lpr directory, showcasing its processing pipeline as illustrated below:
To launch the license plate detection and recognition feature, use the following command:
./build/apps/ds_yolo_lpr/ds_lpr [file or rtsp]Usage:
./build/apps/ds_yolo_lpr/ds_lpr [Your video file path or RTSP stream URL]
Display Features:
- The number displayed in the top-left corner of the screen indicates the total count of license plates detected in the current frame.
- License plates within the frame are enclosed by detection boxes, and when the plate content is fully recognized, the plate number will be displayed above the detection box. The confidence level of the recognition result is shown on the right side of the detection box.
Usage:./build/apps/ds_yolo_lpr/ds_lpr [Your video file path or RTSP stream URL]
Display Features:The number displayed in the top-left corner of the screen indicates the total count of license plates detected in the current frame.License plates within the frame are enclosed by detection boxes, and when the plate content is fully recognized, the plate number will be displayed above the detection box. The confidence level of the recognition result is shown on the right side of the detection box.Upon running the application, you can view the output stream on players like VLC by entering: rtsp://[IP address of the device running the application]:8554/ds-test. The application displays the detected license plates and their recognized characters.
**Note:**The streamed video output can be viewed on any device within the same local network.
**Note:**The streamed video output can be viewed on any device within the same local network.
PS: The video is sourced from the internet. Should there be any copyright infringement, please notify for removal.
PS: The video is sourced from the internet. Should there be any copyright infringement, please notify for removal.
This functionality is based on the NVIDIA-AI-IOT lab's three-stage license plate detection project at deepstream_lpr_app, with modifications for enhanced performance.
We have also provided a flowchart for the three-stage license plate detection and recognition process as follows. For a detailed analysis, please refer to the detailed documentation.
- Face Detection and Pose Recognition Project Initiatives
Note:
We are setting out to develop practical applications for face detection and pose recognition by building upon the foundation laid by exemplary works, namely DeepStream-Yolo-Face and DeepStream-Yolo-Pose. Our objective includes devising compelling applications such as detecting human falls.
Additionally, we plan to integrate these solutions with our XTRT inference engine. The integration aims at enhancing the performance of the Yolo-Face and Yolo-Pose TensorRT engines through plugin-based optimizations for smoother and more efficient inference. We are open to new ideas and invite contributions and suggestions to further enrich our project.
Note:We are setting out to develop practical applications for face detection and pose recognition by building upon the foundation laid by exemplary works, namely DeepStream-Yolo-Face and DeepStream-Yolo-Pose. Our objective includes devising compelling applications such as detecting human falls.Additionally, we plan to integrate these solutions with our XTRT inference engine. The integration aims at enhancing the performance of the Yolo-Face and Yolo-Pose TensorRT engines through plugin-based optimizations for smoother and more efficient inference. We are open to new ideas and invite contributions and suggestions to further enrich our project.💻 Overview of Benchmark and Model Zoo🔖 Benchmark
Leveraging MMYOLO's comprehensive suite of pre-trained models, we have utilized its provided pre-trained models to convert into TensorRT engines at fp16 precision, incorporating the TensorRT8-EfficientNMS plugin. This process was aimed at evaluating the accuracy and speed of inference on the COCO val2017 dataset under these conditions.
The following graph displays the benchmarks achieved using MMYOLO on an NVIDIA Tesla T4 platform:
The evaluation results above are from the MMYOLO model under FP16 precision. The "TRT-FP16-GPU-Latency(ms)" refers to the GPU compute time for model forwarding only on the NVIDIA Tesla T4 device using TensorRT 8.4, with a batch size of 1, testing shape of 640x640 (for YOLOX-tiny, the testing shape is 416x416).
**Note:**In practical tests, we found that on the Jetson platform, due to differences in memory size, there might be some impact on the model's accuracy. This is because TensorRT requires sufficient memory during the engine construction phase to test certain strategies. Across different platforms, there could be an accuracy loss of about 0.2%-0.4%.
The evaluation results above are from the MMYOLO model under FP16 precision. The "TRT-FP16-GPU-Latency(ms)" refers to the GPU compute time for model forwarding only on the NVIDIA Tesla T4 device using TensorRT 8.4, with a batch size of 1, testing shape of 640x640 (for YOLOX-tiny, the testing shape is 416x416).**Note:**In practical tests, we found that on the Jetson platform, due to differences in memory size, there might be some impact on the model's accuracy. This is because TensorRT requires sufficient memory during the engine construction phase to test certain strategies. Across different platforms, there could be an accuracy loss of about 0.2%-0.4%.🔖 Model ZooFor convenience, you can use the YOLO series ONNX models we have uploaded to HuggingFace. However, if you prefer to export your own ONNX models, you have the option to use your models or download the original pre-trained PyTorch model weights from MMYOLO. Follow the steps outlined in the MMYOLO documentation and use the export_onnx.pyscript to convert your model into the ONNX format.
**Note:**The models we have uploaded to HuggingFace are exported to ONNX from MMYOLO's pre-trained models and are available in two formats: one is an end-to-end model that includes the EfficientNMS plugin, and the other has the decode step removed. Please choose the version that best fits your needs. For more information, refer to the detailed documentation.
**Note:**The models we have uploaded to HuggingFace are exported to ONNX from MMYOLO's pre-trained models and are available in two formats: one is an end-to-end model that includes the EfficientNMS plugin, and the other has the decode step removed. Please choose the version that best fits your needs. For more information, refer to the detailed documentation.📖 Document
For more detailed tutorials about the project, please refer to the detailed documentation.
❓ FAQPlease refer to the FAQ for frequently asked questions.
🧾 LicenseThis project is released under the GPL 3.0 license.
🎯 ReferenceThis project references many excellent works from predecessors, and some useful repository links are provided at the end.



Comments
Please log in or sign up to comment.