

Recently, the DeepSeek models have gained a lot of popularity, but a single Raspberry Pi can only run relatively small DeepSeek models. And smaller models often produce hallucinations on certain issues. Therefore, I thought about using multiple Raspberry Pis to run larger DeepSeek models.
So I find distributed llama which can run bigger model with multiple Raspberry Pis, and accelerate DeepSeek model inference speed.
Step 1: Hardware ConnectionConnect all Raspberry Pi5 to the internet switch box, and power on your Raspberry Pi5, then make sure your host computer can use ssh connect to all the Raspberry Pi5.
Among all the distributed nodes, there are root node and worker nodes. The root node is responsible for assigning tasks to the worker nodes while also participating in inference. The worker nodes receive and execute the inference tasks. All nodes need to install Distributed Llama.
SSH in your raspberry pi for example:
ssh ain@10.0.0.139Use command below to install distributed llama on your raspberry pi:
git clone https://github.com/b4rtaz/distributed-llama.git
cd distributed-llama
make dllama
make dllama-apiIn this example there are three work nodes need to set. Use the following command to set your worker node:
cd distributed-llama
sudo nice -n -20 ./dllama worker --port 9999 --nthreads 4Use the SSH command to access your root node, for example:
ssh ain@10.0.0.234Create and activate python virtual environment with follow command:
cd distributed-llama
python -m venv .env
source .env/bin/acitvateInstall necessary lib:
pip install numpy==1.23.5
pip install tourch=2.0.1
pip install safetensors==0.4.2
pip install sentencepiece==0.1.99
pip install transformersThen install model:
git lfs install
git clone https://huggingface.co/b4rtaz/Llama-3_1-8B-Q40-Instruct-Distributed-LlamaRun the command on root node, and input your own works'ip adress:
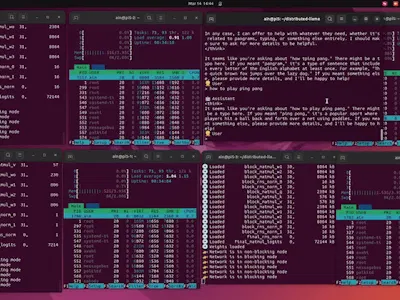
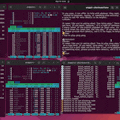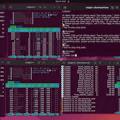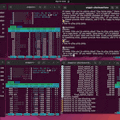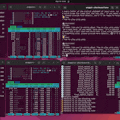
(.env) ain@pi5:~/distributed-llama $ ./dllama inference --model ./Llama-3_1-8B-Q40-Instruct-Distributed-Llama/dllama_model_deepseek-r1-distill-llama-8b_q40.m --tokenizer ./Llama-3_1-8B-Q40-Instruct-Distributed-Llama/dllama_tokenizer_deepseek-r1-distill-llama-8b.t --buffer-float-type q80 --prompt "Hello world" --nthreads 4 --max-seq-len 2048 --workers 10.0.0.139:9998 10.0.0.175:9998 10.0.0.124:9998 --steps 256And here is the chat model run on root node:
(.env) ain@pi5:~/distributed-llama $ ./dllama chat --model ./Llama-3_1-8B-Q40-Instruct-Distributed-Llama/dllama_model_deepseek-r1-distill-llama-8b_q40.m --tokenizer ./Llama-3_1-8B-Q40-Instruct-Distributed-Llama/dllama_tokenizer_deepseek-r1-distill-llama-8b.t --buffer-float-type q80 --prompt "Hello world" --nthreads 4 --max-seq-len 2048 --workers 10.0.0.139:9998 10.0.0.175:9998 10.0.0.124:9998 --steps 256The inference speed using a 100 Mbps switch is approximately 3.5 tokens per second, while using a 1 Gbps switch, the inference speed is approximately 6.06 tokens per second.

Comments
Please log in or sign up to comment.