
_YxwMLHLflj.gif?auto=format%2Ccompress&gifq=35&w=400&h=300&fit=min)

Hardware components | ||||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
| ||||||
| ||||||
| ||||||
| ||||||
The Language-Segment-Anything model is a two-stage model that combined power of object detector model a segmentation model to allow user to detect and segment anything with a text prompt. The traditional language-segment-anything model usually combine GroundingDINO and SAM(Segment Anything Model). However, both GroundingDINO and SAM are too slow to be able to achieve any meaningful real-time interactions on edge device such as the Jetson Orin.
In this project, I was able to achieve a 6x time improvement for Language-Segment-Anthying by replacing GroundingDINO with Yolo-world and SAM with EfficientVitSAM. The improved model, Realtime-Language-Segment-Anything, also include new capabilities such as video and real-time webcam processing.
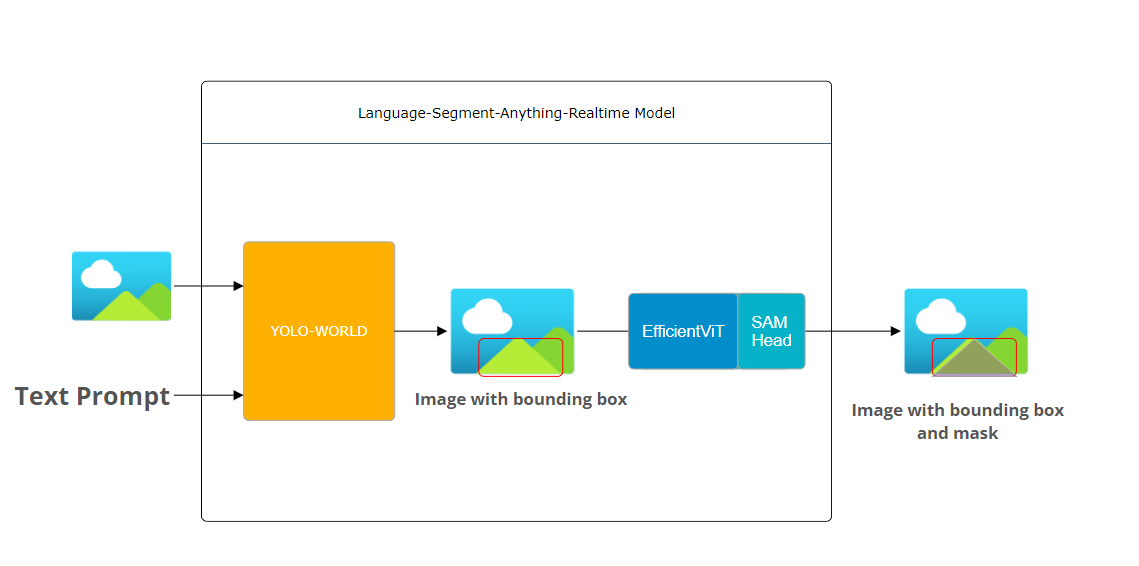
The original architecture of Language-Segment-Anything involved inputing an image and a text prompt into Grounding DINO model. The model then will produced an image with a bounding box based on the user prompt. Next, both image and bounding box coordinate will be fed into SAM model to produce the final image which include the bounding box as well as the mask of the detected object. This approach allows for precise detection and segmentation of any regions within images based on arbitrary text inputs by using SAM Generative A.I technology to "cut out" any object in any image using prompts such as points, boxes, or text.
Improved ArchitectureBoth Grounding DINO and SAM are foundational model and are resource intensive to operate. To improve the processing time significantly, I choose to replace Grounding DINO with YOLO-World.
YOLO-World are much faster to compare to Grounding DINO because it uses Vision-Language Path Aggregation Network to efficiently combine image and text information for quick processing. In addition, YOLO-World is trained on a huge amount of data, making it really good at recognizing a wide variety of objects quickly.
To further optimize the model speed, I also swapped out the original SAM model with EfficientViT-Sam. EfficientViT-Sam retain SAM’s lightweight prompt encoder and mask decoder while replacing the heavy image encoder with EfficientViT. The EfficientViT-Sam are around 48x time faster than the original SAM model but still as well as the original model.
Timing AnalysisTo see the different in performance between the old and new architecture. I did a series of test and record time it take for a processing task to finish. The baseline model I tested against can be found in this repository.
Both model were run on the Invidia Jetson AGX Orin 64GB. For both single image prediction and batch prediction ( video ), Realtime-Language-Segment-Anything outperform the original significantly.
For, single image prediction, Realtime-Language-Segment-Anything is 2x faster than the original model.
For batch processing via video clip, Realtime-Language-Segment-Anything is 6x faster than Language-Segment-Anything. This is due to the fact that the original model have to do the prompt encoding for every frame while Realtime-Language-Segment-Anything only do the prompt encoding once at the very beginning. In addition, Realtime-Language-Segment-Anything is using a YOLO model backbone for object detection and EfficientViT backbone for segmentation, both of these backbone are optimize for speed without losing much performance.
Overall, Realtime-Language-Segment-Anything was able to achieve a 30ms per image processing time which translate roughly to 30 frame per second. With this result, Realtime-Language-Segment-Anything can easily do realtime processing using input from a webcam on the Jetson AGX Orin.
Hardware Setup
The hardware setup of this project include a a mouse, keyboard, and monitor to interface with the Jetson Orin. Ethernet cable to provide internet access for the Jetson Orin. Finally, an EMEET SmartCam to give the hardware capability to capture image in real-time.
Installation1. Set the power mode to MAX on the Jetson AGX Orin
2. Make sure to the the following module:
Pytorch 2.1
Torchvision 0.16.1
Follow this instruction to install the above package on the Jetson AGX Orin
3. Install opencv
sudo apt install python3-opencv4. Clone the repository
git clone https://github.com/TruonghuyMai/Realtime_Language_Segment_Anything.git5. Install requirement
pip3 install -r requirements.txt6. Install Gradio
pip3 install gradio7. Download EfficientViT-SAM checkpoint here
8. Put the checkpoint into /assets/checkpoints/sam/
9. Run the Gradio App
python3 app.pyA browser should open up and let you use the model by either using image, video, or webcam with a prompt of your choice.
Enjoy !!
DemoDemo of Realtime-Language-Segment-Anything using an image, video, and webcam!!
Citation1.EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction (paper, poster). (2023, November 23). GitHub. https://github.com/mit-han-lab/efficientvit
2. AILab-CVC/YOLO-World. (2024, March 4). GitHub. https://github.com/AILab-CVC/YOLO-World
3. Grounded-Segment-Anything. (2023, May 8). GitHub. https://github.com/IDEA-Research/Grounded-Segment-Anything
4. Medeiros, L. (2024, March 3). luca-medeiros/lang-segment-anything. GitHub. https://github.com/luca-medeiros/lang-segment-anything




{kind=link}
Comments
Please log in or sign up to comment.