

Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
 |
| |||||
 |
| |||||
 |
| |||||
Testing for COVID-19 at the start of the pandemic was difficult, there weren't enough test kits to go around and the kits themselves were still developing as far as reliability. Doctors have been diagnosing various diseases by listening to patients cough and breathe for decades. Researchers have conducted studies on developing machine learning models to predict if a patient has bronchitis, can we apply the same approach to COVID-19?
Yes, the answer is yes and MIT plus others have already done it...and are making an app...
One of the key pieces of information from the MIT study is that they were able to identify people who were asymptomatic of the virus using their trained model and as it turns out the cough was the key.
Now, MIT beat us this time but as MIT have already pointed out, asymptomatic people probably aren't rushing in to get tested and if MIT release an app it will still require users to download and use the app.
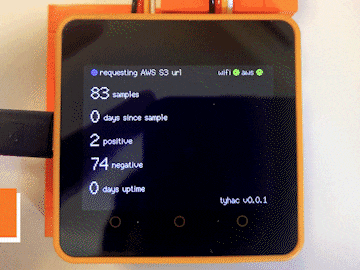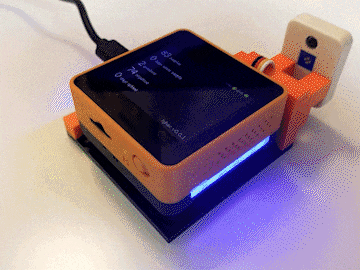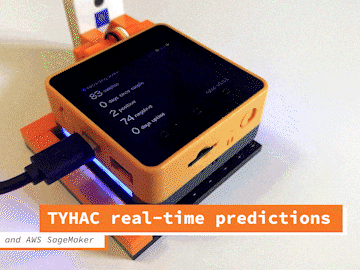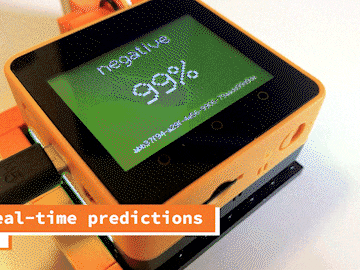
Tyhac aims to address these problems by providing a passive listening device that detects coughs and then runs deep learning inference on the sample to determine if it's COVID-19 positive or negative. By installing tyhac in common places such as offices, elevators, waiting rooms we can help to better protect our community by responding to detected events. We can also use tyhac to better understand how the community responds during flu season and if in the workplace manage healthy habits campaigns to ensure workers are taking care of themselves and where possible using remote working to limit the spread.
How does it work?The solution itself is quite simple thanks to the M5 Core2 stack and AWS, this makes everything pretty straight forward. I've prepared a short video that will run through the high-level design of the device and AWS configuration:
Now that we have a better understanding of the stack we can talk about some of the key features and then move onto a demo. The device has been designed to operate in two modes:
Passive
This mode has been developed for the device to be installed in a workplace, elevator, waiting room, office cubicle, home etc. The LM393 Mic Sensor has a threshold for audible nosies, once it passes that threshold the SPM1423 internal I2S microphone will begin recording a 10 second audio sample.
Clinician(Field Unit)
This mode has been designed for medical professionals, in this mode the device does not use the LM393 and is technically not required. The device can be used on battery (included with device) if preferred e.g. mobile.
The user is presented with a menu showing two options:
Submit
This button is intended for medical professionals to submit positive samples, I have included this so that we receive labelled samples to continue to train the model and improve the predictions.
Test
This button is used to diagnose a patient, once the button is pushed it will record 10 seconds of audio using the internal SPM1423 I2S microphone.
Upload
Both modes record the audio sample as a WAV file and is written to the Sdcard on the device. The device will then publish to the S3 Pre-signed URL MQTT topic to request a secure url to upload the WAV file. Once received the device will begin uploading via secure HTTPS.
Validation
Once the file has been uploaded to AWS S3 a bucket trigger event will invoke the staging Lambda function. The staging process runs a series of checks on the sample:
- Is the sample a valid WAV file?
- Is the sample a cough?
- Augment the file
- Archive the file and copy to the final bucket
If at any stage the staging function does not work or the checks fail the file is removed from the bucket. The DynamoDB events are updated with the results, this has been designed to minimize storage of non-cough related audio samples.
Inference / Prediction
The inference Lambda function is invoked from an S3 event once the file has been created in the final bucket. This will load the trained tyhac model and perform a prediction on the sample. The results are returned via MQTT.
DemoI've prepared a demo that will run through some of the features so what we can see it action. The demo shows:
- Bootup
- Passive covid-19 detection
- Clinician mode testing
In this section we'll step through getting your setup up and running. Be sure to review the BOM to make sure you have the components required to run through the build.
Apart from the BOM you will need an active AWS account as this will require the use of AWS services (awesome!!!). If you don't have an account please follow the AWS official documentation for setting up an account.
Pro tip: Cloud costs money, I strongly recommend understanding the costs of the build and use billing alarms to set a threshold you're comfortable with. I have created a separate project to automate this, feel free to check it out.
Everything you need to build this project (excluding physical assets) is available open source on the talkncloud github repo. The following will serve as a "quick-start" to get you up and running.
Note: You'll find additional information inside the project code and github repo to compliment this write up.
Project folder structure
Once you browse the repository you'll notice the project has been split up into three seperate folders:
- aws-cdk
- aws-iot
- aws-sagemaker
AWS-CDK
AWS Cloud Development Kit (CDK) folder has everything you need to deploy the services required in the cloud. If you refer to the high level design diagram earlier, everything pictured will automatically be provisioned for you. This is Infrastructure as Code (IaC), by developing everything as code I can provide a consistent repeatable environment to make sure it works as designed. The alternative is you'll need to create everything manually (boring).
Note:CDK is a great project, if you've seen IaC before you might be familiar with developing in definition style languages such as JSON or YAML. CDK allows you to bring programming languages to the party such as typescript, python, which if you're browsing hackster I'm sure you'll appreciate.
AWS-IOT
The arduino code to build and upload the firmware to your M5 Core2 AWS EduKit device. This is required to run the tyhac firmware on your device and we'll be using platformio to make things a bit easier.
AWS-SAGEMAKER
If you're into deep learning this folder contains everything you need to perform data preparation, model training and model hosting. The trained models used in the high-level design are included as part of the project. You don't need to use sagemaker at all for this build. Sagemaker is not included in the aws-cdk deployment.
If you want to build on the model or you were just curious, this folder is for you.
Protip:I'm using fastai with fastaudio, if you're looking at doing any deep learning I highly recommend checking it out.
Step1: Cloning the repoLet's work our way through preparing your local environment, we'll start with cdk and then move onto the device.
Clonethe repo
Let's clone all of that tyhac goodness...
git clone https://github.com/talkncloud/tyhac-aws-hackster
cd tyhac-aws-hacksterThis project requires the use of docker containers, these containers will be built and stored in your AWS account using AWS Elastic Container Registry. The containers are used for the lambda functions to perform staging and inference. You can build these containers locally if you have docker installed and running, CDK will take care of everything. If you don't have any of this or your internet is slow, I can recommend AWS Cloud9. The containers will upload approx 3-4GB.
You don't need to know anything about containers, everything is taken care of.
If you're going local, please refer to the docker doco for installation and configuration. If you're using Cloud9 it's already installed.
Note: Cloud9 isn't free, refer to AWS pricing, Cloud9 has not been included as part of the final costs for this build as it's not required.
Apart from CDK we'll be using projen, another great project, this simplifies the building and maintaining of CDK and similar projects. This assumes you have node already installed, refer to the node doco for details.
npm install -g aws-cdk
npm install -g projen
npm install -g yarnYou will need to download and install the AWS cli, this will allow you to authenticate to AWS and perform cloud related actions, which is what we need for CDK to deploy into your account.
Once the AWS cli is installed, you will need to configure the client to add your access keys. This gives the AWS cli privileges to access your account. Refer to the AWS doco for configuration.
Pro tip: The keys AWS refer to are passwords, treat them like that. Don't share them and limit their access. If this is your fist time getting into AWS, remove your credential file at the end of this build and any keys you've generated in your AWS account. You can always create more later if you need. It's best not leave keys hanging around.
Now that you have everything installed and you have configured your AWS cli with access you are ready to provision the backend AWS resources, permissions, policies and configuration for tyhac.
projen
projen deployThe following video shows the deployment using Cloud9, same applies for visual studio code:
Let's verify a few things, I won't go into too much detail but understand CDK uses AWS Cloudformation, the IaC 'OG' if you will. Using the console head over to cloudformation and find the deployment:
Congratulations, you've just built containers, functions, buckets, databases, IoT and more. Pretty cool!!
Step3: AWS-IOT Building and Uploading the tyhac arduino firmwareNow, the part you're probably most interested in, the tyhac thing. Now that our AWS backend is waiting and ready for your thing we can go ahead and build our device.
I can highly recommend the examples and guides over at the AWS EduKit, this is a wealth of information that ranges from getting your env setup to running sample projects. It's a good idea to run through one or two of these to get a feel for it.
LM393MicUnitandSDCard
This part is simple, if you are using the LM393 unit simply connect the sensor to port B on the device. This is indicated on the casing of the LM393.
Insert a micro SD card into the SD Card slot of the device.
Platformio
I'm using platformio to provide a feature rich and easy extension to use the visual studio code. Refer to the visual studio code download and install and platformio install to get those running.
Now let's move into the aws-iot folder:
cd aws-iot
codeThis should open the visual studio code editor in that location, otherwise open visual studio code and open the cloned repository.
We are going to use platformio to open the iot project, this will create environment required to connect to the device and use platformio:
Folder structure
The folder structure is mostly based off the default platformio skeleton, you'll notice the readme files included explain this better than I can.
There are few items I'd like to highlight:
certs - public AWS certs required for secure HTTPS communication
utilities - we'll be using this to automate the provisioning of the thing with AWS
lib - most of the code has been split up into separate libraries to make it easier, this folder contains the tyhac libraries
lib/env - you will need to update this for your environment, we'll talk more about this in the next section
platformio.ini - you may need to change the settings in this file depending on your system, mainly the USB port. Example, AWS EduKit, USB information.
Env.sample.h
Using the editor open the environment file, you'll need to copy the sample file over to the same location named env.h
Update the settings for your env, the file contains helpful details on how to retrieve AWS related information that you need. Example:
Your AWS account:
aws sts get-caller-identityYour AWS IoT Endpoint:
aws iot describe-endpoint --endpoint-type iot:Data-ATSDeviceprovisioning
As you can imagine, we don't want just anyone using our AWS tyhac stack. To use AWS IoT with our configuration you'll need to register the device with AWS IoT. This requires generating certificates and associating the device with relvant policies so that the thing can do what it needs to do e.g. MQTT.
I've provided a script to handle this for you. If you follow the AWS EduKit guides you'll notice this is a similar approach. The script will register the thing in AWS IoT, generate certificates and associate the certificate with the policy we created earlier in the CDK stack.
cd utilities/AWS_IoT_registration_helper
./registration_helper.shThe certificates that are generated are stored in the output_files folder, these are your certificates and are private. These certificates will be loaded into the SPIFFS on the device during build time and used for secure communication with AWS.
Device build and upload
With the M5 Core2 AWS EduKit device connected, AWS backend completed, device provisioned and configured for your environment you are ready to build the firmware and upload to your device.
I like to use the platformio toolbar located at the bottom of the IDE:
tick = build
arrow = upload to device
bin / trash = clean
plug = monitor serial output
terminal = new platformio terminal
Using the tick, build the project and then use the arrow to upload to the device, the terminal output will show you the current status. Once the upload is completed it should automatically switch to the monitor output but if not hit the plug button to switch to monitor.
You can see under normal operation the serial output will provide some useful details on how the tyhac thing is operating. In the next section I'll provide some detail into what each of the different indicators and messages mean.
Pro tip: If you're clicking the platformio monitor button in the toolbar watch out for the button location moving as it does in the video. argh.
Devicestatus indicatorsandserial output
The M5 Stack Core2 AWS EduKit comes with two RGB strips either side of the device so I figure we may as well use them. Now that your device is running the tyhac firmware and communicating with AWS you might notice different indicators happening.
Orange = Connecting or processing, this can be for Wifi or AWS MQTT
Green = The action was OK e.g. wifi connected
Red = Critical error, mostly likely unable to connect to Wifi
White = normal operating mode
Note: The same colors are used for the prediction display.e.g positive and negative green and red.
The status messages both on the display and in the serial output are mostly self explanatory:
MQTT = Subscribing, receiving, connecting
Heartbeat = A heartbeat MQTT message is sent to AWS every minute with the current mode
NTP = Sync with remote time server
Screen = LCD screen related items such as change display
Button = Switch modes e.g. passive or clinician (active)
Tyhac device libraries
I've tried to split the code up into libraries to more easily manage the code base and to allow others to use the bits they need for other projects:
audio = everything related to recording audio from the mic to the sd card
env = your environment specific configuration
mqtt = everything related to pub/sub MQTT with AWS
ntp = setting the clock with remote NTP server
rgbcolor = managing the RGB strips
ui = everything related to the LCD screen interface
upload = everything related to AWS S3 uploading over HTTPS
version = simply a version file
If for example you wanted to change the color of the RGB's you would simply go to the lib/rgbcolor library and update the changeRgbColor function with the RGB values of your choosing or add different colors etc.
Step4: AWS-Sagemaker optional model trainingI won't go into too much detail about sagemaker. As I've said earlier, you won't need to do this part unless you want to for your own understanding or you're looking to maintain the model. The basic approach that I've taken to sagemaker is that I need CPU, GPU and storage that I simply don't have, AWS provide this for us on-demand at a low cost.
Pro tip: I've taken steps to reduce the costs associated with sagemaker by using the spot market for training, this should result in ~70% cost saving depending on your region and the AWS market. However, this will still be the most costly part of this project, make sure you monitor your costs and setup billing alarms and remove anything when you're done.
AWS Sagemaker Studio
I ended up using sagemaker studio because it gave me so many features that I could use to build, train and deploy all inside a standard browser using the studio IDE, it just made sense given our short timeframe. AWS have provided more information on why Studio is preferred. You should be able to do this locally if you have your own setup or standard notebook instances in AWS. This would reduce costs further but will take more of your time.
Creating sagemaker studio
Using the AWS console in your browser head over to sagemaker and using the landing page hit the orange "SageMaker Studio" button.
Using the "Quick Start" option this will setup and environment for you with the required permissions. Once you accept the configuration AWS will start configuring your environment, this will take a few minutes but is a once of.
When your configuration is ready you'll notice a banner message something like this:
You should notice the "Open Studio" click is available, this will launch the AWS SageMaker Studio Web IDE so we can begin.
If this isn't available your env may still be provisioning or you'll need to use the "Assign users and groups" button to associate your user account.
Once you launch SageMaker studio you'll see a sweet SageMaker logo loading screen, the first launch tends to take a little longer, after that it will be much quicker.
Once Studio has loaded you'll be landed into the Studio IDE:
I really like the Studio IDE, for the most part I found it pretty intuitive and visually quite nice to work with. Because we'll be adding a git repository we can use the git icon to load the tyhac repo and hit "clone a repository":
Once cloned you'll notice the familiar tyhac code base structure, navigate over to aws-sagemaker to work with the files we need:
Dockercontainers for fastai training
When you need to perform training AWS SageMaker will submit a job for training and spin up the compute, GPU, memory instance or instances that you specify for the training. AWS SageMaker provide a bunch of preconfigured containers for various frameworks to get you going such as tensorflow, pytorch etc. When you want to use something different you can build containers with your custom framework. This is what I've done. The docker folder in the repo contains the code needed to build and push the containers into your AWS ECR to be consumed by SageMaker when it needs to.
Protip: As with the previous tips, if you have slower internet or don't want to configure docker etc, AWS Cloud9 is a big help here.
You'll notice two containers, one for training and one for inference. If you want to train the model and replace it in the tyhac backend you do not need to worry about the inference container. If you want to run inference using a dedicated SageMaker endpoint the container code and notebook is included.
To build the containers you will need to be authenticated with your aws cli again, update the Dockerfile to reflect your AWS region and then simply run the shell script:
./build_and_push.shSageMaker diagram
It's a little easier to understand how SageMaker, ECR and notebooks hang together using a diagram. The following diagram shows how the tyhac notebooks and services work together:
Usingthenotebooks
The Studio IDE and notebooks will give you everything you need to run, simply open the notebook and step through the cells:
For the most part I used the tensorflow kernel from AWS and just added a couple of packages I needed. You can change the kernel at the top of the IDE.
Datavisualization
Once you completed some data prep there are cells that include data visualization before you move onto training, the below shows samples from covid-19 positive and negative patients. The output is the audio mel-spectrogram which we use for training:
We can dig a little further into the data set to show our current labels and spectrograms:
Training
Once you're happy with the dataprep you can move onto the training notebook, this will run the sagemaker training job and output model files to s3, you can update the hyperparameters and the model architecture in the notebook:
hyperparams = { 'epochs' : 1,
'learning-rate': 0.001, # fastai default
'batch-size' : 64, # fastaudio default
'model-arch' : 'resnet18', # resnet34
'workers' : 16 # default 2
}You will need to update the container location for your account:
image_uri = 'ACCOUNTID.dkr.ecr.ap-southeast-2.amazonaws.com/tyhac-sagemaker-fastai:1.0-gpu-py36',The notebook I've developed will output a few images that you can use to see model performance:
Updating the model in AWS
If you're happy with the model you can simply download the model.tar.gz from your sagemaker S3 bucket, extract the contents and copy the export.pkl into the aws-cdk/src/lambda/predictor/model folder.
Then update your AWS CDK deployment:
cd aws-cdk
projen deployNow when the tyhac M5 Core AWS EduKit thing receives a new sample to perform inference on it will be using your newly trained model. Simple!
Step5: Clean upOnce you've completed the project and you no longer need to be running any of the tyhac AWS stack we should remove them.
Because we've used CDK, removing the stack is easy
You'll first need to remove the device cerficate from the AWS IoT core CDK policy using the AWS management console and then:
cd aws-cdk
projen destroyProtip: You can also use cloudformation via the AWS console to remove the stack.
This will leave behind the following that will need to be removed manually:
- AWS S3 buckets
- AWS DynamoDB
- AWS ECR (containers)
Navigate to those services in the AWS console to empty and remove them.
If you configured SageMaker Studio:
- Navigate to SageMaker Studio
- Click the user, delete the associate apps
- Delete the user
- Go back
- Delete Studio
Navigate to AWS EFS
- Select the EFS volume and then delete
Protip: If you have multiple volumes inspect the tags, SageMaker tags the volume associated with SageMaker.
Difficulties / ChallengesI'll now discuss some of the challenges I had during this project, spoiler there were many (and still are) :)
DeeplearningwithSageMaker
- How the heck to you even predict anything from audio?
This was a rabbit hole, trying to understand how I might go about using an audio cough to predict anything. Once I started researching the problem, I was able to find some really great information and research papers (see repo). In the end the best approach is to use mel-specrograms and convolutional neural networks with known architectures. Rather than looking at numerical data points for an audio sample, using an image of audio.
- Data preparation, data preparation, data preparation
This seemed never ending, download the data, sort the data, find the labels, rinse and repeat. Work out that there isn't enough data, adjust to get more data if possible and then realize I've made a mistake in the data preparation and it needs to be redone. Time consuming but critical part of the stack.
- Hyperparameters, audio parameters, frameworks
Epochs? Optimizers? A whole new language, I had a lot of trouble training a model that worked at all. Trying various frameworks with no luck I almost abandoned the project and was preparing to write about my failures. I would constantly train a model with a ROC of 0.5, a perfectly useless model. FastAI really saved me from myself here, once I switched to using fastai I was able to train something that worked, pairing that with fastaudio had the same effect on the audio component.
- Just use more CPU cores, who needs GPU anyway
Once I switched to FastAI I need to build custom docker containers for the framework. Which was great, however, I noticed during training that the GPU was never used. I put the issue on the backlog and threw more CPU at it (not smart) to get the training time to about 5-7 minutes per cycle. I ended up working out that the tensorflow required packages are installed based on your system, my local system lacks NVIDIA GPU's and installed the CPU package. Tweaking the Dockerfile to pull the GPU packages meant the GPU was used and cycles went down to about 1 minute. This means, more cost saving, less time!
- OK, I've got a trained model, now what?
Custom containers and SageMaker inference. This was overly complicated, if you want to use SageMaker endpoints you need to work within the framework of the SageMaker inference requirements. There are certain functions required in your serving scripts that just need to be there. I fought this for the longest time thinking this just wasn't true but now understand the structured approach.
M5Core2 Stack Arduino
- Micropython, nope, arduino
I want to go fast, I'm developing python notebooks for SageMaker and I know the M5 Core2 can use micropython. My initial experiments with micropython didn't go well, it became clear pretty early on that what I was trying to do was outside the scope of micropython on the device giving the time constraint. My next go to was arduino, which ended up working out OK. It was good that the device supported multiple languages. I think that shifting over to esp-idf would be a good next step.
- LM393 is a microphone?
I thought this was microphone, not just a sound sensor. My original design needed a trigger, something to start the recording which is why I bought the LM393 but I also thought it was a higher quality microphone. I had to quickly adapt to use the internal mic.
- SM1423 internal microphone I2S
The internal microphone uses I2S, not something I've had anything to do with in the past. Trying to understand how you read from the I2S interface and write that to a file was challenging. There were a few examples kicking around but not many when it came to arduino, SDCards and wav files. A lot of trial and error.
- I just want to upload a file to S3 over HTTPS, what gives?
I could not work out the headers required for AWS S3, it would constantly be rejected by S3. A lot of debugging, changing file types, reviewing headers etc and I eventually got it work. I couldn't find any clear examples on how to do this using arduino. To my knowledge my example is the only known working example to date that is publicly availble.
- Hey, cool, RGB lights, let's use them, this isn't orange?
After all of the challenges I decided to take a detour and have a little fun with the RGB lights. Turns out the RGB lights in the fastled library are out of order, I'd try to make orange and it would end something different. Once I understood the problem, swapping the value in my code made it a little easier to pick my RGB colors and then have my function handle swap. It's the little things...
- Moving house, slow internet, AWS Cloud9 to the rescue
Towards the end the project I moved house, the new location has decent download speeds but the upload could be better. Usually this wouldn't be a problem but my stack is heavily dependent on containers which need to be uploaded to AWS ECR. When I was working through the device and staging/predictor lambda functions I needed to iterate through code changes quickly. It was taking 20, 30, 60 minutes to make a simple change.
I ended up switching to AWS Cloud9 for the aws-cdk deployment, which brought this down to 2-5 minutes for container changes. The managed service was quick, easy and cost effective to get up and running. Switching over to Cloud9 only took minutes, I wouldn't have completed the challenge without it.
Next stepsThis project is a good start to show end to end how you might tackle this problem with the M5 Core2 AWS EduKit. There are a number of improvements and future opportunities that could be looked at:
- Device registration
I'm using RSA certificate authentication (per the AWS console), the M5 Stack includes a secure hardware element. My initial attempts at getting this to work with arduino did not work. There is a modified library by AWS in the M5 Stack repo, I suspect this is needed for it work.
- Experiment with different microphones
I'd like to use different microphones, see what else the community might recommend to increase the audio quality.
- Local inference
A nice change would be to try and bring the model inference down to the device itself, failing that closer to the edge in AWS. This would reduce inference time, however it would still be good to build on the data for training, background uploading might be something to look into.
- More data
The model is only as good as the data and it needs more. It's going to be interesting to see if the public data continues to grow, this might help retrain the model with new data and improve the accuracy.
- Different devices
Because the stack is decoupled we can pretty much use any device that records audio to do this. Can we tap into any existing public services that might be recording audio already.
Final thoughtsI had a great time working through this challenge, it was a great intro to the M5 Core2 Stack which is a pretty capable device and is perfect for quick prototyping like this stack or more complicated stacks. I like how AWS IoT can become the central point for all of your IoT related services, the ability to securely interact with AWS from that central service made it easy to design and integrate with DynamoDB and Lambda.
I hope that this project will be useful for others to build on and extend or take the bits they need to get their prototype or product off the ground.
Thank you Hackster and AWS for putting together this challenge and creating a community to make this possible.
Happy coding.










{kind=link}
{kind=link}
{kind=link}
Comments
Please log in or sign up to comment.