
Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
Did you know you can run speech recognition on your Pi, for free? If you want to dive straight in, just download, install, and run the spchcat command to get started. In the rest of this article, I'll tell you a bit more about how I built it, what it can do, and how you can help improve it.
What's this all about?It used to be that only big companies could afford the armies of engineers, mountains of training data, and time it took to build a usable speech recognition system. Thankfully the open source community, especially projects like Mozilla's Common Voice and Coqui's speech-to-text library, have changed all that. By gathering massive amounts of speech in many different languages, and open sourcing training code and completed models, they've made it possible to build speech recognizers that are useful for a lot of tasks. The results may not, yet, be as good as the best commercial systems, but the speed of improvement is impressive, and they can already enable a lot of interesting new applications.
I've been aware of Coqui's work since they launched, because they use TensorFlow Lite, a library I helped build, for the machine learning calculations. I knew they had impressive results, and I wanted to experiment with building simple voice interfaces on my Pi using their framework, but there wasn't an easy way for me to get started. Over the winter holidays I decided my fun project would be to write a simple command line tool to listen to my Raspberry Pi's microphone and write what text it heard to the terminal. The result is spchcat, a command line tool to read in audio from microphones, system audio, or wav files, and output text. All of the models and libraries it relies on are open source, and the code for the tool itself is available at github.com/petewarden/spchcat.
What do you need?To use it, you first need to install it from the latest.deb package. This is over a gigabyte in size, because it contains data for more than 40 languages. In the future I'd like to find a way to make the tool more modular, so you can just pick the languages you want, since the current process makes downloading and installing slower than it needs to be, but I haven't figured out how to do that yet.
You'll need a modern Raspberry Pi (it's been tested on Pi 4's) because it uses optimized NEON instructions to run in real-time, and these weren't present on the original Pi Ones or Zeros. You'll need a recent version of Raspberry Pi OS too, for the PulseAudio library. For the most fun I'd recommend a USB microphone as well. Almost any should work, but I've linked to the one I used in Things.
Once you've downloaded and installed the package, make sure your mic is plugged in, open up a terminal window, and run the spchcat command with no arguments.
spchcat
You should see some version information appear.
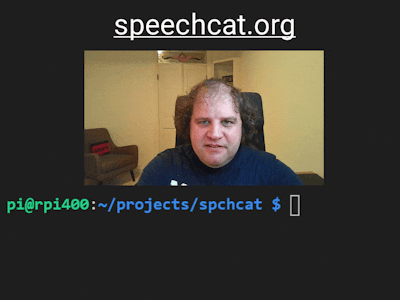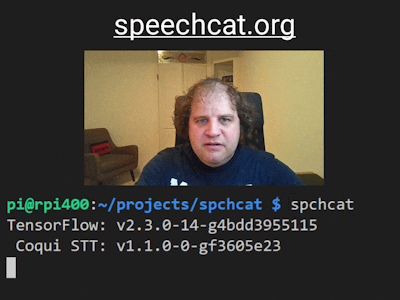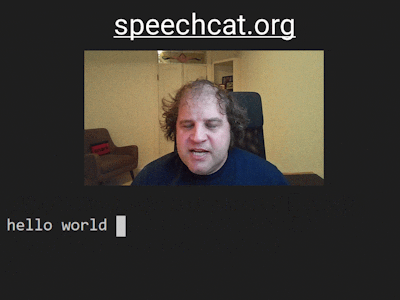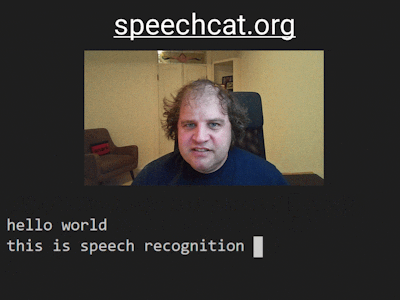
Now, it will be waiting for you to say something. Try speaking normally into the microphone, and output text should begin to appear.
Here I said "Testing, testing", then "Hello Hackster". As you can see, it doesn't know about the word Hackster, so it makes its best guess as "hats the"! There are ways to supply custom words, but I'll cover those in future posts. As you can imagine, speech recognition is often not perfect, but I hope being able to play around with it yourself will give you a good feel for how well it works in practice.
Recognizing From a FileThe next thing you can try is running speech recognition on a file. It should work on any.wav, and you can convert other formats like songs and videos to those using ffmpeg, but there are also some sample files you can download from Coqui for testing purposes. To run it on files, just pass the filenames or directories full of files as command-line arguments:
spchcat audio/8455-210777-0068.wav
You should see output something like this:
Another fun feature is that you can ask the tool to listen to the audio your system is currently playing, and try to transcribe any speech it finds. This can be useful if you're in a Zoom meeting or are playing a video, and want to see an automatic transcript. To use that, you specify the --source=system flag on the command line:
spchcat --source=system
One of the reasons I'm most excited about having a useful open source stack for speech recognition is that it allows motivated community members to build models for languages they care about. Commercial systems support languages that have large numbers of users, because it only makes sense to invest the time and money needed if enough people will use it. Coqui have been able to work with both individuals, and groups like ITML to support a wide range of languages like Czech, Welsh, and many more. It's possible to train your own models, but even if you're not a coder you can help by contributing speech in languages you speak to Common Voice, and help others. The tool will try to use your system configuration to guess what language to default to, but if you want to tell it explicitly you can use the --language flag, like this:
spchcat --language=de_DE audio/auf_wiedersehn.wav
If you're a Hackster reader, I'm betting you're already thinking of ideas for how this could fit in with the projects you work on. The good news is that Coqui have APIs for Python, NodeJS, and Android, as well as the plain C API spchcat is using. I'm hoping that having an easy-to-use command line tool will let you experiment quickly and understand what the capabilities and limitations of the technology are. I originally built it to help me prototype some simple voice interfaces, I just got a bit carried away! It's been great being able to build on top of the hard work of a whole community of people dedicated to democratizing speech recognition, the ecosystem seems like a wonderful example of how well open source efforts can work. I hope it helps you build something fun, or useful, or both, and I'd love to hear about any projects you do create.





Comments