


Hardware components | ||||||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
 |
| |||||
This article is designed for individuals who have recently acquired a Xilinx RFSoC UltraScale+ evaluation board and are uncertain about how or where to begin. I will outline the fundamental steps in the board boot process, covering tasks such as powering the board, communicating with the processing system, then move to initiating Jupyter labs and interacting with hardware designs using the PYNQ framework (Python for ZYNQ). The second part of the article includes a Vivado tutorial outlining how to build and implement a custom design in the board's hardware. Although there are numerous tutorials and slide presentations covering these subjects online, this article aims to consolidate these insights, providing a centralized resource to help inexperienced users get their projects up and running quickly.
Booting the BoardFully detailed schematics outlining all of the different internal and external board connections can be viewed from the purchasing site at RFSoC 4x2 | Real Digital yet booting the board for the first time only requires knowledge of the following components.
The micro-SD card slot will hold a preconfigured image specifically for the UltraScale+ platform that contains all of the processor and hardware information required for initial booting. This image includes the PYNQ framework, base file systems for the operating system, and all of the functionality involved with programming the FPGA fabric through this operating system. This image can be reconfigured and redesigned to better fit the users' needs, yet this is out of the scope for the time being and the default will be used. A 12V-10A power cable is included in the boards kit and is always required during board operation. A micro-USB 3.0 port is provided to establish a serial communication to the board and allow the user to traverse the base file systems. An ethernet port is included to give the operating system direct access to internet and finally an LCD Display is embedded into the board itself which when powered on displays helpful information about the board's health and connection status.
Before powering on the board for the first time we need a tested image to boot from. Luckily as previously hinted this base image has already been created by the PYNQ support team specifically for this UltraScale+ which greatly reduces the complexity and timeframe of booting. To obtain this image file, navigate to the PYNQ - Python productivity for Zynq - Board website and download the latest image version for the RFSoC 4x2.
Flash this downloaded image (.iso file) to the kits included micro-SD card using software such as Balena Etcher or a similar type. After this flash process completes insert the micro-SD card into the corresponding slot on the board, connect your host PC to the board using the micro-USB port as well as an ethernet cable using a direct router or network splitter connection. Finally plug in the power cord to the input power port and turn the board on using the embedded power switch. The board should begin a series of boot regimens in which an array of on-board peripherals are tested. Different LEDs and fan speeds will be cycled through as well as version information will be subsequently written out on the LCD display. After 5-10 seconds has gone by the board should settle in which the fan converges to a steady rate and the LCD display shows the boards IP address.
If no internet connection is established the image verification can still be checked using the serial micro-USB connection and a terminal emulator application such as Putty (baud rate=115200) but for the remainder of the boot process it will be assumed that an internet connection was made, and proper IP address displayed.
To verify the image functionality, we can ssh into the boards operating system using the following command: the preconfigured user and password for authenticating are both set to 'xilinx', all lowercase, as seen below.
> ssh xilinx@<ip-address>
> xilinx password: xilinxUpon authentication you will be tunneled into the boards base file system which entails the following sub directories:
- 'jupyter_notebooks': This folder holds all python notebooks to be run in the Juypter labs server (more on this next). The folder comes preconfigured with an array of introductory notebooks focused on getting the user comfortable with the PYNQ fraework.
- 'pynq': This folder holds the framework configuration and supporting python files needed to run PYNQ. It is also home to the 'overlays' directory where all reconfigurable hardware designs are located and their supporting files.
Jupyter Labs has gained widespread acceptance in the Python community thanks to its user-friendly nature as well its lightweight integrated development environment (IDE) which is easily deployable on embedded processors like the one found in the RFSoC. The PYNQ image takes care of configuring the processing chip to launch Jupyter Labs as a web application during boot time. This setup enables users to wirelessly access the integrated development environment through the board's IP address. To do this open a search engine on your host machine and navigate to the following web address replacing <ip-address> with the address displayed on your board.
http://<ip-address>/labJupyter Labs may require a minute or two to fully load. Following, you will be prompted for password authentication, where you'll again utilize the default login: "xilinx." The base image incorporates several different notebooks which outline the process of loading new hardware designs via the operating system, interacting with on board peripherals, and even an intro to software defined radio processing techniques.
The next section of this tutorial will walk through the process of building a custom accelerated hardware design in Vivado and interacting with it using the PYNQ framework in a notebook similar to the preloaded ones you see in Jupyter Labs. At this point you should be able to follow this boot process (minus flashing the image) each time the board is used and through the example notebooks in the base design begin to understand and realize the full capabilities of the RFSoC you are working with.
Custom Hardware Acceleration - Part 1Before creating a board design we must first build an IP clock to create around. This tutorial will implement a complex multiplier but as the tutorial continues it will be easy to see how the design can be replicated and/or expanded.
To begin open Vivado (2023.1 used in my design) and create a new project specifying the RFSoC part number xczu48dr-ffvg1517-2-e. Under the 'Tools' dropdown tab select 'Create and Package New IP', 'Next', then 'Create AXI4 Peripheral'. Title the IP block 'cmult' standing for complex multiplier and save it to the default Vivado generated IP directory. Our complex multiplier IP design will adhere to the following diagram where inputs a and b are each 32 bits long with the first 16 representing their real components and second 16 representing their imaginary components. Output c_r represents the real result of a and b being multiplied and c_i the imaginary, both of 32 bits in length.
Knowing this overview, we now can jump back to the IP packager and specify our inputs and outputs. Use the single AXI-Lite slave interface and configure it to have 4 registers since we will need 2 for inputs a and b and 2 for outputs c_r and c_i. At the final IP packager menu select 'Edit IP' to open the IP project repository to begin its customization.
The two preloaded Verilog files are centered around AXI-Lite protocol which is transfers data between internal registers at the rate of one clock cycle. The AXI interface family also includes AXI-Full which supports packet and burst transmission as well as AXI-Stream. These are out of the scope of this demo as AXI-Lite provides a simple design for internal chip communication and results in a very quick development time. Add the following Verilog file representing our complex multiplier to the design sources, save the project, and let the hierarchy automatically update.
`timescale 1ns / 1ps
module cmult #(
parameter DATA_WIDTH = 32
)
(
input wire [DATA_WIDTH-1:0] a,
input wire [DATA_WIDTH-1:0] b,
output reg [DATA_WIDTH-1:0] cr,
output reg [DATA_WIDTH-1:0] ci
);
wire signed [(DATA_WIDTH/2)-1:0] ar;
wire signed [(DATA_WIDTH/2)-1:0] ai;
wire signed [(DATA_WIDTH/2)-1:0] br;
wire signed [(DATA_WIDTH/2)-1:0] bi;
assign ar = a[DATA_WIDTH-1: 16];
assign ai = a[(DATA_WIDTH/2)-1:0];
assign br = b[DATA_WIDTH-1: 16];
assign bi = b[(DATA_WIDTH/2)-1:0];
always@(a, b) begin
cr = ar*br - ai*bi;
ci = ar*br + ai*bi;
end
endmoduleAs seen in the Verilog above, we are mimicking exactly what the previous diagram did by breaking apart inputs a and b into their real and imaginary parts then operating on these four values to find the resulting c_r and c_i outputs.
The next step of this tutorial involves connecting our specified inputs and outputs to the four preconfigured AXI-Lite registers located in the cmult_v1_0_S00_AXI.v Verilog file. A block diagram is included below to help visualize this connection and the subsequent wiring that will occur.
Open the cmult_v1_0_S00_AXI.v file and add user ports a, b, c_r, and c_i as seen below. Next add the internal signals seen at the end of the module input and output instantiations (these internal signals all adhere to a top-level reconfigurable data width parameter).
Scroll to the bottom of this file and add the following lines in the user logic section to connect our input and output signals to their corresponding ports.
// Add user logic here
assign a_wire = slv_reg0;
assign a = a_wire;
assign b_wire = slv_reg1;
assign b = b_wire;
assign cr_wire = cr;
assign ci_wire = ci;
// User logic endsFinally find the address decoding section, seen below, and change the last two register pointers such that they are updated with our c_r and c_i signals. Save the file and let the project hierarchy auto refresh.
It is important to note that this decoding section also establishes our offsets between register addresses within the AXI-Lite bus. These hexadecimal values represent bytes and can be used to map our inputs and outputs to the correct register when implementing the design. For now, a table will be created to summarize each address offset and the value it holds.
We now update our top-level file with the lower-level file changes made and connect each of our each of these modules together. Open the current top-level file (show in bold) and instantiate the cmult.v file in the user logic section using the following Verilog.
// Add user logic here
cmult # (
.DATA_WIDTH(C_S00_AXI_DATA_WIDTH)
)
cmult_inst (
.a(a_wire),
.b(b_wire),
.cr(cr_wire),
.ci(ci_wire)
);
// User logic endsCreate four internal signals for wiring our modules together and add our newly configured ports in the cmult_v1_0_S00_AXI module instantiation as seen in the figure below.
After saving these changes the hierarchy should adjust and now include the cmult module in the top-level connections. Navigate to the 'Package IP' tab and select 'Re-Package IP' to save changes and bring the configured IP into a production state to be used in our system level block design.
Custom Hardware Acceleration - Part 2Back in the boards Vivado project select 'Settings' under 'Project Manager' then the 'IP' drop down, click 'repository' and add the path to your previously created complex multiplier IP if it has not already been included. Save/Apply the changes and insert the IP into the working block design as seen below.
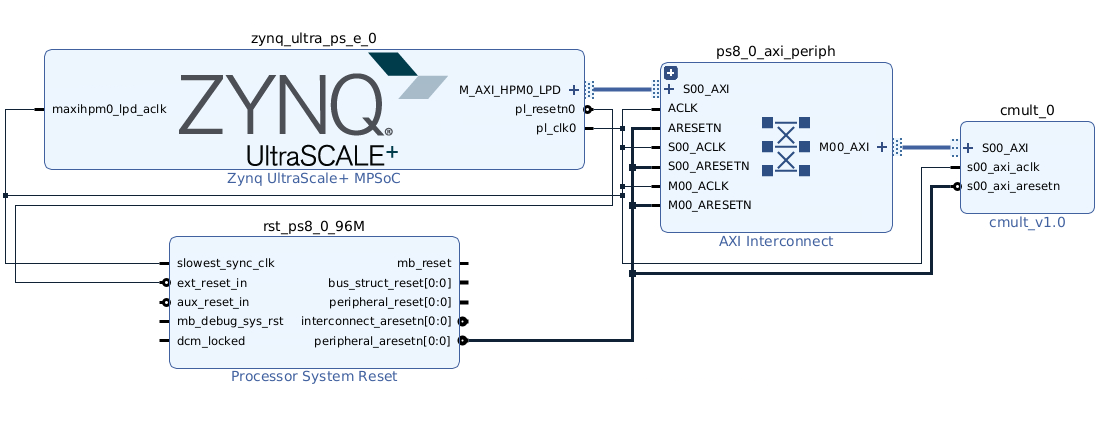
Add the Zynq UltraScale+ MPSoC IP which represents the boards processing system and its configuration. For this project we will leave the presets as is including the 100 MHz clock preconfigured to be used for programmable logic. Wire this clock signal output to the master AXI connect clock input as seen below.
Connect the output programmable clock signal to the complex multiplier IP input clock and then click 'Run Connection Automation' to fill all other intermediate connections including system reset control and AXI interconnect translations. Save then validate the design verifying it matches the configuration seen below.
Under the 'Sources' tab, left click the block design directory and select 'Create HDL Wrapper'. This will package and instantiate all of the previously configured modules into one top file. Since our design is relatively simple and does not require any board inputs or outputs this file will not include any instantiated ports and therefore no board peripheral connections (no constraints file needed).
Synthesize the design then run implementation to validate the design on simulated hardware and after successful completion of the previous two steps left click 'Generate Bitstream' and let the binary build. The generated bitstream file, the block designs.tcl script, and the projects hardware handoff file (.hwh) are all needed to load the hardware design through the PYNQ framework.
After successful generation of the bitstream create a new directory on your host machine named the same as what was used for your Vivado project. This folder will shortly be copied to the boards base file system in the following steps. Back in Vivado, navigate to the 'File' dropdown tab, then 'Export', and export both the bitstream file as well as the block design.tcl script. Rename these files the same as your projects name with their corresponding file suffixes. Locate the autogenerated hardware handoff file located in the following directory.
./<project-name>/<project-name>.gen/sources_1/bd/<block-design-name>/hw_handoff/<block-design-name>.hwhOr search for it with the Linux command below.
<project-name>$ find -type f -name *.hwhCopy/rename this file in the same way as the others prior. The resulting folder structure should look as follows ('rfsoc_tutorial' being the name used for my Vivado project).
At this point, the design phase is complete, and we are prepared to upload and execute the designed configuration, along with its associated IP, on the board.
Custom Hardware Acceleration - Part 3If the board is not already booted follow the initial procedure of this tutorial and establish a connection to the board either using ssh or a terminal emulator on your host. In the boards terminal, navigate to the 'overlays' directory within 'xilinx/pynq' and using sftp copy the previously created <project-name> folder containing the designs.bit,.tcl, and.hwh files to the 'overlays' directory. The resulting structure should resemble the diagram below.
Open the boards running Jupyter labs server in a browser using the IP address shown on the LCD display (outlined in the 'Booting the Board' section) and create a new Jupyter notebook by clicking the blue plus icon then selecting 'Notebook'. Create two new cells and copy the following code into each which will import the PYNQ library and upload the generated bitstream onto the FPGA fabric.
If any errors occur at this point it is most likely due to naming errors (all folders and files within an overlay must have the same name to be correctly parsed) or the files and folders are not located in the right directory (see file structure diagram). Next run the help function around the newly created overlay object to expose the external peripherals connected to the processing system. In this case, we have one, our complex multiplier seen below as 'cmult_0'.
The PYNQ framework helps to identify and convert all peripheral IP blocks into python class-based objects each with a plethora of underlying methods. Create a 'cmult' object that is a subclass of the overlay 'ol' object and again run the help function to expose its underlying methods.
The preconfigured we will be using are 'write' and 'read' which will allow direct access to the registers we configured during complex multiplier IP design. These functions take an offset value, in hex, corresponding to the register to be written to or read from. Back when we packaged our custom complex multiplier IP we set the offsets for each register and thetare summarized again below.
Using these known offset values, we can now create a simple python function using the 'write' and 'read' methods to input complex values into the hardware and read the resulting complex product.
All that is left to do is test our design and verify its output! Add the following lines in the next block to test the complex multiplier or add your own inputs following the 32-bit format designed for a and b.
This article aims to offer some helpful insight in getting the RFSoC up and running quickly as well as how to implement a simple design in the board's hardware. By following this hardware acceleration design flow, you can begin to customize your own unique IP blocks and even integrate more sophisticated connection interfaces such as AXI-Full or AXI-Stream. Much of what I have learned about the board pertaining to hardware design as a whole and more specifically SDR on the RFSoC is credited to the following links which are all very useful for providing foundational knowledge. Using the examples found in these resources or the one outlined above can allow users to quickly start piecing together more advanced designs tailored to their field of interest. Best of luck developing!



{kind=link}
Comments