

Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
NVIDIA’s TAO (Train Adapt Optimize) Toolkit enables data scientists, developers, and engineers to create optimized Machine Learning (ML) models with smaller datasets using transfer learning. TAO models suited for IoT applications can be deployed to devices equipped with an Arm based CPU, GPU, or NPU for efficient privacy preserving on-device inferencing with TensorFlow Lite.
In a previous blog, my colleagues Amogh and Chu demonstrated how an image classification model trained and optimized with the TAO Toolkit can be deployed onto an Arm Corstone-300 system, which contains an Arm Cortex-M55 CPU and Arm Ethos-U55 NPU.
This blog will explore deploying a pre-trained NVIDIA TAO Toolkit Object Detection ML model to an Arm Cortex-A based device with an Arm Ethos-U NPU which runs a Yocto Linux distribution. We’ll demonstrate the ML model in action using a Python application that leverages OpenCV, GStreamer, and TensorFlow Lite. Then show how using the Ethos-U NPU for ML inferencing results in 10x faster inference latency.
DetectNet V2 ModelsNVIDIA’s TAO toolkit includes support for creating Object Detection models based on a variety of model architectures, including DetectNet V2, FasterRCNN, YOLO (v3 and v4), SSD. DetectNet V2 models use a GridBox architecture that divides the input into a uniform grid that predict a confidence value (cov) and bounding box (bbox) and per category using regression.
The input image is passed into a feature extractor model, the extracted features are then passed into two separate 2D convolution layers that calculate the confidence values and bounding boxes per category.
NVIDIA’s TAO DetectNet V2 supports several types of feature extractor models, including:
- resnet10/resnet18/resnet34/resnet50
- vgg16/vgg19
- googlenet
- mobilenet_v1/mobilenet_v2
- squeezenet
- darknet19/darknet53
Pre-trained models for each type of feature extractor are also provided. These pre-trained models have been trained on a subset of the Google OpenImages dataset.
The output of the model needs to be scaled and offset, then post-processed with a clustering algorithm (DBSCAN or NMS) that calculates the final bounding boxes and category labels.
PeopleNetNVIDIA has leveraged the TAO Toolkit to create several DetectNet V2 models for smart city applications. The PeopleNet model is a DetectNet V2 model with a ResNet 34 backbone that detects objects in the following three categories:
- persons
- bags
- faces
v2.6 of the model was trained on a proprietary dataset of over 7.6 million images which contained over 71 million objects for the person class!
The model’s input is a 960x544 RGB image, and outputs a 34x60 grid which has a scale and offset of 35 and 0.5 respectively. Each interference requires 14.6 billion MAC (multiply and accumulate) operations.
Hardware platformThis blog will focus on deploying the PeopleNet model to an NXP i.MX 93 EVK board. The NXP i.MX 93 EVK is based on the NXP i.MX 93 SoC, which contains 2 Arm Cortex-A55 CPUs that run at 1.7 GHz and an Arm Ethos-U65 NPU that runs at 1 GHz and supports 256 MACs/cc. We’ll run the model on both the CPU and NPU, and briefly compare the inference latency of both.
What you’ll need:
- NXP i.MX 93 EVK board - includes USB-A to USB-C adapter, and USB-C power supply
- NXP IMX-MIPI-HDMI (for HDMI output) - includes mini-SAS cable
- microSD card - 8 GB or larger
- USB Web camera
- HDMI cable
- Ethernet cable
- Monitor with HDMI input
While this blog focuses on the NXP i.MX 93, the Python code and model should be portable and be able to run on an alternative Arm Cortex-A based development board that runs Linux.
Model ConversionThe PeopleNet model needs to be converted to a quantized TensorFlow Lite format before it can be run efficiently on the i.MX 93 EVK board. The Jupyter Notebook for this can be found in the following on GitHub and Google Colab.
This section will give a high-level overview of the process:
1. The PeopleNet model is licensed under NVIDIA’s Model EULA,review the license, and proceed to the next step if you accept the terms and conditions stated in the license.
3. Place the converted model in the same directory has the Jupyter Notebook or upload it to the Google Colab instance.
4. Update the value of the INPUT_MODEL variable, with the file name of the model.
5. The ONNX model’s input and output tensor names have a “:0” suffix which is incompatible with TensorFlow (as it will add its own similar suffix). The ONNX model must be modified to remove the “:0” suffix from the input and output tensors using the ONNX Python package.
import onnx
onnx_model = onnx.load('resnet34_peoplenet_int8.onnx')
# input and output names to remove :0 suffix from
suffix = ':0'
graph_input_names = [input.name for input in onnx_model.graph.input]
graph_output_names = [output.name for output in onnx_model.graph.output]
print('graph_input_names =', graph_input_names)
print('graph_output_names =', graph_output_names)
for input in onnx_model.graph.input:
input.name = input.name.removesuffix(suffix)
for output in onnx_model.graph.output:
output.name = output.name.removesuffix(suffix)
for node in onnx_model.graph.node:
for i in range(len(node.input)):
if node.input[i] in graph_input_names:
node.input[i] = node.input[i].removesuffix(suffix)
for i in range(len(node.output)):
if node.output[i] in graph_output_names:
node.output[i] = node.output[i].removesuffix(suffix)
onnx.save(onnx_model, 'resnet34_peoplenet_int8_mod.onnx')6. TensorFlow runs more efficiently with models that are in NHWC format (where N = batch size, H = height, W = width, C = channels). In the above screenshot, you can see the ONNX model is in NCHW format, as the input tensor size is [unknown, 3, 544, 960]. OpenVINO and openvino2tensorflow can be used together to convert the NCHW ONNX model to a NHWC TensorFlow model.
pip3 install openvino_dev openvino2tensorflow tensorflow tensorflow_datasets
mo \
--input_model resnet34_peoplenet_int8_mod.onnx \
--input_shape "[1,3,544,960]" \
--output_dir resnet34_peoplenet_int8_openvino \
--compress_to_fp16=False
openvino2tensorflow \
--model_path resnet34_peoplenet_int8_openvino/resnet34_peoplenet_int8_mod.xml \
--model_output_path resnet34_peoplenet_int8_tensorflow \
--non_verbose \
--output_saved_model7. Once the model is in TensorFlow format, it can be converted to quantized TensorFlow Lite model. Since we are unable to access the original training dataset, the random data will be used for the representative dataset during quantization. The quantized model’s input will be set as int8, but output will be left as float32.
import tensorflow as tf
import numpy as np
converter = tf.lite.TFLiteConverter.from_saved_model(
'resnet34_peoplenet_int8_tensorflow'
)
tflite_model = converter.convert()
def representative_dataset():
for _ in range(10):
yield [
tf.random.uniform((1, 544, 960, 3))
]
converter.optimizations = [
tf.lite.Optimize.DEFAULT
]
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS_INT8
]
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.float32
converter.representative_dataset = representative_dataset
tflite_quant_model = converter.convert()
with open('resnet34_peoplenet_int8.tflite', 'wb') as f:
f.write(tflite_quant_model)8. We now have a.tflite model that can run on the Arm Cortex-A55 CPU. In order for the model to run on the Arm Ethos-U65 NPU the.tflite file must be compiled using the Vela compiler.
pip3 install ethos-u-vela
vela \
--config Arm/vela.ini \
--accelerator-config ethos-u65-256 \
--system-config Ethos_U65_High_End \
--memory-mode Dedicated_Sram \
--output-dir . \
resnet34_peoplenet_int8.tfliteThe quantized TensorFlow Lite and Vela compiled quantized TensorFlow Lite model can now be used in the Python application.
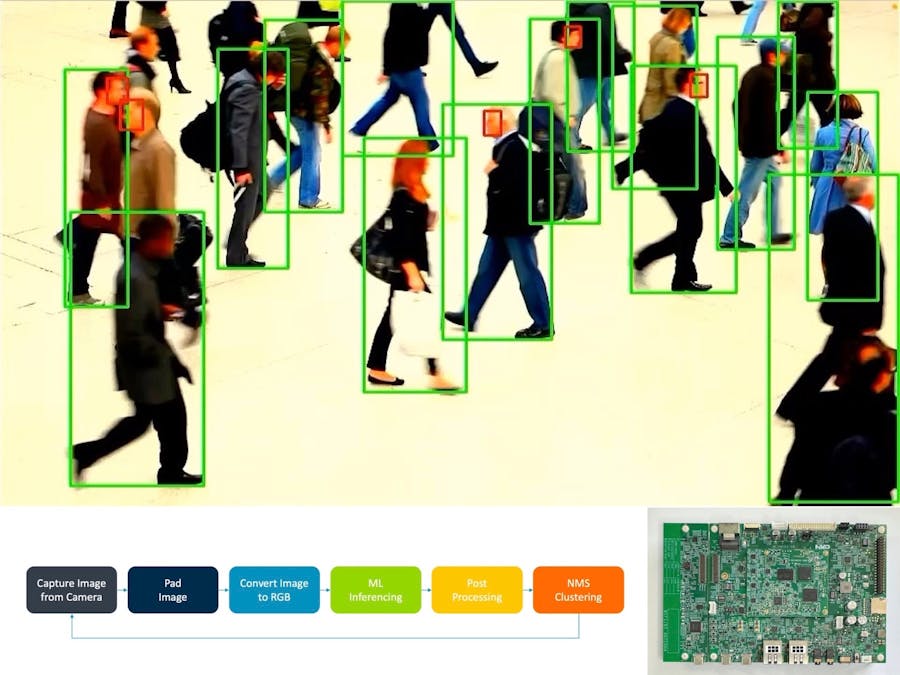
The Python application is structured as follows:
Initialization
- Initialize video capture device using OpenCV and GStreamer
- Initialize model, post-processor, and NMS model
Main loop
- Capture image from video capture device
- Pad captured image to 960x544
- Convert resized image from BGR to RGB format
- Perform ML inferencing with RGB image; results in cov and bbox
- Post-process cov and bbox; scale and offset then reshape
- Apply NMS clustering
- Filter out bounding boxes that are under the minimum height threshold (20 pixels)
- Show image with bounding boxes
Source code for the application can be found on GitHub.
Image CaptureOpenCV and GStreamer will be used to capture still images from the USB web camera.
The video capture input can be setup using the following code:
import cv2
vid = cv2.VideoCapture(
"v4l2src ! video/x-raw,width=1280,height=720 ! autovideoconvert ! "
"videoscale ! video/x-raw,width=960,height=540 ! appsink drop=true sync=false",
cv2.CAP_GSTREAMER,
)The GStreamer pipeline will capture frames from a Video4Linux2 (V4L2) source device with a resolution of 1280x720, and then scale the image to 960x540.
A frame can be read using the following code:
ret, frame = vid.read()The TensorFlow Lite model expects the input image to be in RGB format with a 960x544 size. We can pad the 960x540 image using the following Python code:
frame = np.pad(frame, pad_width=((0, 4), (0, 0), (0, 0)))Since OpenCV uses BRG format, the image must be converted to RGB format using:
x = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)A Python class that uses TensorFlow Lite can be created to make inferencing more convenient:
import os
import numpy as np
import tflite_runtime.interpreter as tflite
class DetectNetV2Model:
def __init__(self, model_path, num_threads=os.cpu_count()):
self.interpreter = tflite.Interpreter(
model_path=model_path,
num_threads=num_threads,
)
self.interpreter.allocate_tensors()
input_details = self.interpreter.get_input_details()
output_details = self.interpreter.get_output_details()
self.input_index = input_details[0]["index"]
self.output_0_index = output_details[0]["index"]
self.output_1_index = output_details[1]["index"]
def predict(self, x):
x = (x - 128).astype(np.int8)
x = np.expand_dims(x, axis=0)
self.interpreter.set_tensor(self.input_index, x)
self.interpreter.invoke()
cov = self.interpreter.get_tensor(self.output_0_index)
bbox = self.interpreter.get_tensor(self.output_1_index)
return cov, bboxSince the model is quantized and requires an int8 input, the predict function subtracts 128 from the uint8 input and then converts the result to an int8 type.
The cov output has a shape of 1x34x60x3 and provides a confidence value for each of the grid cells for each of the 3 categories (person, face, bag). The bbox output has a shape of 1x34x60x12, and provides a bounding box (x1, y1, x2, y2) for each of the 3 categories.
The bbox output from model inferencing will be scaled and offset with 35 and 0.5 respectively.
Then both values can be reshaped for easier input into the NMS clustering.
- cov:
1x34x60x3 => 1x2040x3 - bbox:
1x34x60x12 => 1x2040x3x4
If we don’t apply clustering to the bounding boxes, there will be multiple bounding boxes that overlap.
Non-maximum Suppression (NMS) is a clustering technique that is used to filter overlapping bounding boxes. When provided with a list of bounding boxes and scores, the algorithm will filter out bounding boxes that overlap with a certain area threshold (intersection over union) and score threshold. TensorFlow’s tf.image.non_max_suppression_with_scores(...) API provides an implementation of NMS. A Python script can be found on GitHub that creates an NMS model and converts it to TensorFlow Lite format, so that it can run on the board.
The following values for maximum_output_size, iou_threshold, and score_threshold values will be used at run-time for each category.
+----------+---------------------+---------------+-----------------+
| Category | maximum_output_size | iou_threshold | score_threshold |
+----------+---------------------+---------------+-----------------+
| persons | 20 | 0.5 | 0.4 |
| bags | 20 | 0.5 | 0.2 |
| faces | 20 | 0.5 | 0.2 |
+----------+---------------------+---------------+-----------------+These values are the same values found in NVIDIA’s config_infer_primary_peoplenet.txt and config_infer_primary_peoplenet.yml configuration files.
After applying NMS, the bounding boxes are as follows:
The application described in the previous section can now be run on the development board. We’ll need to set up both the hardware and software to do this.
Hardware1. If you don’t already have an NXP.com account, sign-up for one here.
2. Download v6.1.36_2.1.0 of the pre-built Yocto Linux Image for the i.MX 93 from https://www.nxp.com/design/design-center/software/embedded-software/i-mx-software/embedded-linux-for-i-mx-applications-processors:IMXLINUX (requires NXP.com login, then reviewing and accepting a license)
3. Extract the downloaded zip file.
4. Follow section 4.3.1 and 4.3.2 of NXP’s "i.MX Linux User's Guide" and flash the imx-image-full-imx93evk.wic file from the extracted zip file to microSD card.
5. Insert the microSD card into the i.MX 93 EVK board.
6. Configure the SW1301 jumper as follows, to enable booting from the microSD card.
7. Plug in the Ethernet cable to the board.
8. Plug in the miniSAS cable into the HDMI adapter and the DSI port of the board, then the HDMI cable into the adapter and monitor.
9. Plug in the USB web camera into the USB-A port of the USB-A to USB-C adapter, then plug the USB-C side of the adapter into USB-C port next to the Ethernet adapter on the EVK.
10. Plug in the USB-C power supply into the USB-C port next the power switch.
11. Move the power switch to ON position.
1. Clone the example application from GitHub:
git clone https://github.com/ArmDeveloperEcosystem/ml-object-detection-examples-for-imx93.git2. Copy the application code to the board using scp
scp -r ml-object-detection-examples-for-imx93/detectnet_v2 root@imx93evk.local:.3. Copy the converted.tflite models to the board using scp
scp resnet34_peoplenet_int8.tflite root@imx93evk.local:detectnet_v2/.
scp resnet34_peoplenet_int8_vela.tflite root@imx93evk.local:detectnet_v2/.4. SSH into the board
ssh root@imx93evk.local5. Change directories
cd detectnet_v26. Run the application on the CPU only
python3 main.py resnet34_peoplenet_int8.tflite7. Stop the application using CTRL-C
8. Run the application on the NPU
python3 main.py resnet34_peoplenet_int8_vela.tflite9. Stop the application using CTRL-C
Latency CPU vs NPUWhen only using the CPU to run the application the inference latency is much larger than using both the CPU and NPU together. Here’s a summary of the inference latency in milliseconds.
+------------------------------+-------------------+
| | Inference Latency |
+------------------------------+-------------------+
| 2x Cortex-A55 | 928.77 ms |
| 2x Cortex-A55 + 1x Ethos-U65 | 86.34 ms |
+------------------------------+-------------------+Running the ML model on the NPU is over 10x faster than the CPU! We can’t run everything on the NPU however, the CPU is still needed to:
1) Capture image data from the USB camera and perform pre-processing before ML inferencing.
2) Post-process the ML model’s output and perform NMS clustering after ML inferencing.
ConclusionThis guide covered how to deploy the pre-trained NVIDIA TAO Toolkit DetectNet V2 based PeopleNet Object Detection model to an NXP i.MX 93 EVK development board. We covered how a pre-trained ONNX model can be converted to TensorFlow Lite format to run efficiently on the boards Arm Cortex-A55 CPU’s and Arm Ethos-U65 NPU with a Python application running in Yocto Linux. As well as how to use Python for image capture, pre and post processing.
Wesaw an over 10x increase in inference performance when using the Ethos-U65 NPU for ML inferencing!
As a next step, you can follow NVIDIA’s "Object Detection using TAO DetectNet_v2" tutorial to train your own model. Once your model has be trained, the tao model detectnet_v2 export command can be used to export the model to ONNX format, so it can then be converted to a TensorFlow Lite model to run on the EVK board.
The model conversion section is based on Silicon Labs “ONNX to TF-Lite Model Conversion” guide.






{kind=link}
Comments