
Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
| ||||||
| ||||||
| ||||||
Hand tools and fabrication machines | ||||||
 |
| |||||
Traditional vision-based wildlife monitoring methods are limited by weather conditions, the camera's field of view, the size of target organisms, and their proximity. There is great room for alternative technologies which can monitor wildlife more reliably through other channels: like acoustic monitoring.
Acoustic monitoring offers a reliable, low-cost, and scalable alternative to monitor wildlife, with the added bonus of detecting harmful human activity: whilst poaching and logging may be impossible to see, they are much easier to hear.
Of course, acoustic monitoring is not a new idea. However, most products only record; they don’t analyze. This gives rise to huge quantities of raw data which exceeds the manpower of researchers to analyse individually. Currently, conservation organizations often turn to big tech companies to process their raw data. Not only does this place conservationists in the passive with a big focus on historical data, but it also presents a significant barrier for small-scale, local conservation efforts. Moreover, this also hinders the potential for acoustic monitoring systems to act as alarms.
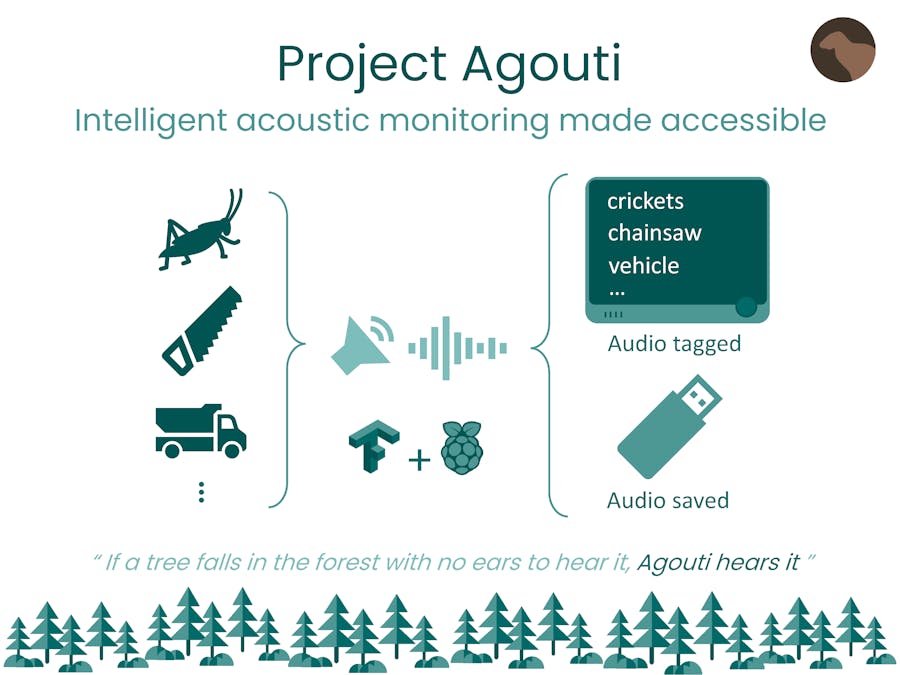
Agouti: Our ProductIn light of these considerations, Agouti is an intelligent, weatherproof acoustic monitoring device that can be easily deployed for the recording and analyzing of audio data.
We employ edgeML to automatically tag the microphone data for key event classes like insect sounds and birdsongs, human activity (e.g. vehicles), and logging (e.g. chainsaw noises), storing these tags together with their respective audios for human inspection. We also record readings from temperature, humidity, and light sensors to link audio with the real world, quantifying exactly how the environment affects species' behaviours.
Agouti broadly addresses "Challenge 2: Wildlife/Biodiversity Conservation". Specifically, we tackle two issues at once:
- Non-intrusive monitoring of endangered wildlife: Our acoustic recording system takes periodic 5-second recordings of its surrounding soundscape, which is then analysed and stored together with the audio.
- Human-wildlife conflict prevention/mitigation: by examaning audio for sounds of suspicious activity (like logging or transport noises), we can detect for illegal activities detrimental to the environment.
So, as shown above, Agouti uses the Wio Terminal for gathering data and displaying predictions, whilst the Raspberry Pi is used for processing and storing the data. We decided to incorporate a Raspberry Pi for 2 reasons
1. Some simpler models we tried simply cannot perform audio analysis with a reasonable degree of accuracy. So we had to use an AI model that was too large to fit or run on the Wio, but small enough to fit on the RPi.
2. The RPi can write to USB storage devices with capacities much larger than the 16GB SD card slot of the Wio.
Now, let's walk through how we created Agouti. All code and other supporting files referenced here can be accessed at our GitHub repo, which contains detailed instructions for setting up each part of our system.
Part 1: AI TrainingThis was the hardest bit. We tried many model architectures of all sizes, and the approach we stuck with in the end is transfer learning. As opposed to training a new model, transfer learning significantly reduces training time and resources required. By taking advantage of the advanced model architecture of a pre-trained model, it also results in a greater accuracy.
For our training, we used the pre-trained model YAMNet from Google. YAMNet analyses the Mel Spectrogram of the input audio data, which is a spectrogram with biased sensitivity to different frequencies according to human hearing. It is a model mainly composed of convolutional layers, trained on Google's AudioSet dataset, and outputs an array of scores corresponding to each of the 521 pre-defined classes.
We then selected another dataset, ESC-50, which mainly comprises environmental noises and is hence more suited to our purpose. The audio data here comes as 5s 16khz. YAMNet generates embeddings from the audio and we train a final classifier on those embeddings. Because YAMNet slices audio data into 0.96s frames, our 5 second recordings yielded an array of embeddings. To get around this, we employed a 128-unit LSTM model that recurrently operates on this array of data.
To further increase the robustness of our model, we added audio augmentations: stretching/compressing of time axis, modulating of frequencies, mixing of random noise, harmonic distortion, etc. This inevitably decreases the accuracy when training, though resulted in a better performance in application.
To make the model's final predictions more visual, we also created a confusion matrix of what the model mixes up. This is shown below:
Once the final classifier layer has been trained, we quantised it and turned it into a TFlite model that can be easily run on the Pi.
You can play with our actual implementation on Google Colab here.
Here are a few snippets of the AI analysing audio from YouTube:
Part 2: Wio + RPi Over SerialWe are immensely grateful to Seeed Studios for supplying us with a free SenseCAP K1100 Sensor Prototype Kit. We used the Wio terminal to take readings from its builtin light sensor and microhpone, as well as an attached Grove SHT40 Temperature and Humidity sensor.
As you'll recall, the Wio Terminal takes care of all the sensor data and records audio through its mic, whilst the Raspberry Pi runs a big AI acoustics model (too big to fit on Wio) and enables data to be stored onto a USB drive with large storage. Communication between the two is achieved using serial:
- The Raspberry Pi sends a command to Wio on startup
- Wio grabs sensor data and records 16k frames of audio data, then sends that back to the Pi. The Pi then does a few things:
- The Pi measures the time it takes for Wio to get audio data, automatically calibrating for the delay between each frame, so that the Wio returns exactly 16000 frames per second.
- The Pi converts raw audio data to a numpy array between -1 and 1, then passes this through YAMNet to extract YAMNet predictions and embeddings
- The YAMNet embeddings are then passed through our custom model to extract higher level audio information
- Predictions from both YAMNet and our custom model are combined to give a final audio tag
- If enough time has passed since the last audio was stored or if the audio is tagged as dangerous, the Pi write the audio data together with its predicted tags (as a JSON) to the USB
- The Pi sends the predicted audio tag and calibrated delay time back to the Wio
- The Wio displays the predicted audio tag, records audio data again (this time using the new delay value), and the loop continues
Again, full instructions are available in our GitHub repo for setting up the RPi and the Wio.
Part 3: CasingIn order to protect the hardwares from external environmental damage, we designed a waterproof casing on Onshape, using 3mm transparent acrylic boards which are shaped using a laser cutter.
We decided to use acrylic boards because they are durable and lightweight with the added benefits of being easily laser cut. The case is also entirely transparent to make sure that the screen is visible. In addition, a small window was included in the design of the case to connect the temperature and humidity sensor (which is outside) to the Wio (which is inside). All the base parts of the protective case are designed with finger joints, giving strong stability and strength, and maximising the adhesiveness of the acrylic cement which is used to connect and form the entire box.
And... we've done it!
Here is a video of Agouti in action, detecting human noises with a plane in the background:
Below is a sample of what the JSON file linked to an audio file might look like:
{
"category": "chainsaw", # Final audio tag
"class": "sawing", # Big class that tag falls into
"humidity": 51.6, # Humidity value
"light": 170, # Light sensor value
"original": "chainsaw", # Prediction from our model
"temperature": 20.09, # Temperature value
"yamnet": [ # YAMNet prediction at each frame
"Engine",
"Breathing",
"Vehicle",
"Vehicle",
"Vehicle",
"Vehicle",
"Frying (food)",
"Breathing",
"Rattle",
"Engine"
]
}And... all the audio files have been stored correctly onto the USB:
In the future, we envision making the following changes to improve Agouti:
- Support for sending analysed audio tags and sensor data through LoRaWan, so data and warnings can be refreshed instantly (we did have code ready to send sensor data to Helium over Lora, but there were issues with connecting, perhaps to do with Lora coverage)
- Solar panels for longer continuous operation
- Making the ported ML model more accurate, and capable of recognising more audio classes
- Use a better mic and sample at higher rate
Credits to my 3 other teammates from Team Enigma who took part in developing this project:
Dylan Kainth mainly for handling the Wio-side of the hardware, for suggesting to use a Pi, and for so many other things
Alex Yi mainly for helping with the AI, for investigating different algorithms, and for coming up with different audio augmentations
Mark Zeng for designing the case and for doing some research on Edge Impulse













{kind=link}
Comments