




Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
The crucial information necessary to track the migration of birds is vocalization. However, capturing this information requires the physical presence of birdwatchers who are adept in identifying bird species from their calls and songs. This process is very time consuming and impractical, especially for nocturnal birds. A better solution to this would to have an automated system which can both capture the vocalizations and identify the birds within this captured information.
Our project has attempted to address this issue of accurately identifying bird species from vocalizations using the power of an Intel Edison compute module to capture and store audio data and the predictive power of TensorFlow to take each audio sample and identify the bird within it.
Our system will attempt to identify the following four species of bird:
- Barn Owl
- Crow
- Oriental Scops Owl
- Western Screech Owl
To accomplish this task, we will use a very simple architecture like the one below. Data flows from the Edison to the Server where a TensorFlow model resides to predict the birds within the audio samples and then publish these results to a web page for easy access to the results.
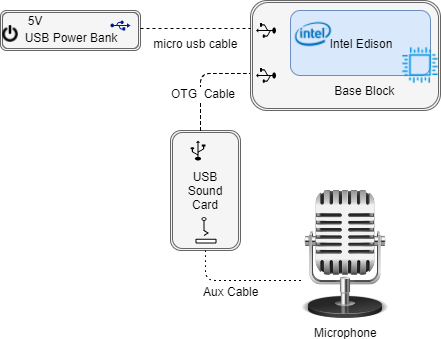
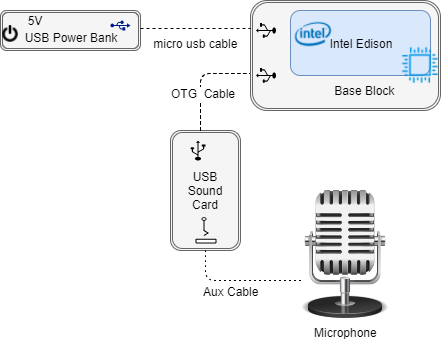
To capture bird vocalizations, we require hardware that can both record and transmit audio samples. To build our audio recording component, we need:
- Intel Edison
- Sparkfun Block
- Microphone
- OTG Female to Micro USB Adapter
- USB Sound Card
Step 1 - Set up the Edison
The Edison is first mounted onto the Sparkfun Block. The Edison can be easily setup or mounted by following the “Getting Started” page here. This step should be followed through to connect via the USB console and OTG, enabling WiFi and download the Intel XDK.
To talk to the Edison, we use a command line interface. We used PuTTY for Windows. In PuTTY, we can connect to the Edison terminal via the COM port. To do this, we plug a USB cable connecting the “console” port of the Edison to a computer. Open PuTTY, select “serial” and connect to the right serial port at speed 115200 (for effective communication).
Similarly, we can connect to the Edison terminal using its known IP Address, selecting SSH on PuTTY and connect with port 22.
Step 2 - Connect the Microphone
If the Edison has been connected to WiFi and you can properly access the terminal, the next step is building the audio component by putting all the required hardware parts together.
The OTG cable is connected to the OTG USB port of the Edison. The female end of the OTG cable should then be connected to the USB sound card.
Next the microphone is connected to the USB sound card via the audio jack. Be sure to connect the microphone to the right audio jack.
To power the Edison, a USB cable is connected from the “console” port of the Edison to a laptop or a power bank of no greater than 9V. The Edison is designed to tolerate 9V and so it is not advised to exceed it.
With all this we are ready to set up the audio component to listen and record sounds. The setup should look like the schematic below.
Step 3 - Configure the Edison
By following the "Getting Started" link provided in Step 1, you should have downloaded the recent Linux image for the Edison. This image comes with:
- GStreamer: a player that allows Intel Edison to play WAV files
- PulseAudio: a server that manages the audio source/sink device
- ALSA Driver
- ALSA Library: a Linux audio library
For more on the Intel Edison Audio software architecture and more understanding of setting up the audio go to the Intel Edison: Audio Setup Guide. Following the steps in the guide, you should be able to listen to sounds from the microphone and hear the output when you connect a speaker to the USB sound card.
Now we install apache2 and PHP. We do this so that we can have a directory to store our recordings and simply access it via a web browser when connected to same network as our Intel Edison board.
To setup apache2 we open the terminal via PuTTY for Windows (or equivalent software for Mac and Linux). To download and install Apache2 open the Edison terminal and type the following command:
wget http://repo.opkg.net/edison/repo/core2-32/apache2_2.4.20-r0_core2-32.ipk
Next we install apache2:
opkg install apache2_2.4.20-r0_core2-32.ipk
Getting PHP is a similar task:
wget http://repo.opkg.net/edison/repo/core2-32/php_5.6.18-r0_core2-32.ipk
opkg install php_5.6.18-r0_core2-32.ipk
Note: Installing either apache2 or PHP may require some dependencies such as libmysqlclients18, libaprutil-1-0, libmcrypt, etc. This can be found in the repo here and by following similar process of downloading and installing Apache2, you can do same for these dependencies.
Next we start up the apache2 server:
systemctl start apache2
systemctl enable apache2
All that is needed to be done is to reboot the Edison board by entering “reboot” into the terminal. When the Edison has restarted, the Apache server should start as well. Typing the command “ifconfig” in the terminal shows Edison's IP address:
Try typing the IP Address into a compatible web browser like Chrome. The page should say “It Works”, otherwise try following Step 3 again.
To navigate to where the intel.html file is, type into the terminal:
cd /usr/share/apache2/htdocs
While in the “htdocs” directory, create a directory called “capturedsounds” to save the recorded sounds:
mkdir capturedsounds
First lets try to see that we can record sounds. With the USB sound card, microphone and Edison all plugged in, open the Edison terminal via PuTTY and enter:
arecord -f cd audio.wav
This will record a 10 second .wav file by default at a CD quality to the root of the Edison at 44.1kHz sampling rate with 16-bit resolution. When done recording click CTRL+C or CTRL+Z to end recording. A file called audio.wav will be saved to the Edison root.
Now we know we can record with our audio component. Next we write a Python script to systematically record 3 seconds .wav file and save it to our capturedsounds directory.
In the Python script:
changeDirectory = ‘cd /usr/share/apache2/htdocs/capturedsounds’
The "changeDirectory" script navigates to the capturedSounds directory where recorded sounds will be saved.
record = ‘arecord -f cd -t wav --max-file-time 3 --use-strftime %Y%m%d/sound-%H-%M-%v.wav’
The “record” script records audio at 44.1KHz sampling rate with 16-bit resolution. The “--max-file-time 3” tells Edison to record audio samples for 3 seconds. The “--use-strftime %Y/%m/%d/” creates a directory using the current year, a sub directory using the present month and a sub-sub directory using the present day. The “sound-%H-%M-%v.wav” saves the recorded .wav file using the time it was recorded. E.g sound-12-11-02.wav tells us the sound was recorded at 12:11:02pm.
The sound files can be accessed in the browser with URLs of the following format:
<ipAddress>/capturedsounds/<year>/<month>/<day>
This is demonstrated in the image below.
Upload the Python script “record3.py” to the Edison root and run in the background.
python record3.py &
With this set, the Edison is ready to be deployed to record sounds.
Creating a DatasetWhile the Edison setup will capture new sounds for us to predict, we first need a very large dataset of exemplary data to train our model with. We used a mixture of both primary and secondary data due to limitations in the number of birds available to record. We sourced Crow sounds locally, whereas Barn Owl, Oriental Scops Owl (OS Owl), and Western Screech Owl (WS Owl) sounds were curated using audio contributions from Macaulay Library at the Cornell Lab of Ornithology; we were able to record some Barn Owl sounds by the time that the model was developed.
Our primary data was collected by entering a woodland area in the evening as crows were cawing in the trees above. We then placed our Intel Edison microphone setup securely onto a branch and recorded the area for half an hour.
The recordings were then arduously trimmed and stored one by one, applying amplification and noise reduction on them in order to remove any background noise and leave us with just the bird sound. The complete dataset of bird sounds can be found here (and are credited individually in their respective README.md files).
To be useful in training a predictive model, the recordings need to be uniform so that TensorFlow has a standard format when loading and manipulating each sound. Therefore, each clip was then padded and trimmed to all be 2 seconds in duration.
Below are visual representations of each bird sound. The images show how there is a lot of variation in the different sounds produced by each bird. When the model examines future (unseen) sounds, the patterns we see below will serve as the criteria to determine which bird classification the new sounds should fall into.
As there were far fewer OS Owl sounds available, 60 samples were chosen of each bird except for the OS Owl where 50 were chosen. This was done to prevent a large bias between using hundreds of the other bird recordings and only tens of the OS Owl.
The dataset was then artificially increased in size through data augmentation by increasing and decreasing the amplification of each clip at different decibel (dB) levels, producing 7130 total sounds in the process. Generating sounds at varying dB levels provides regularization for the dataset as it means that the model will not overfit to specific dB levels.
Convolutional Neural NetworkTo predict bird species from the sounds they make in audio is a task that must be ‘taught’ to the model in a supervised manner. In other words, one must give examples of typical bird sound data along with its correct classification (e.g. ‘this audio clip contains the cawing of a crow’). Given sufficient examples, the model can eventually tune its weights so that, given an unseen crow sound, it can be passed through these weights and return a correct classification for that given sound.
Training should routinely be checked against a small portion of the dataset that isn’t being used for training (i.e. a test set) to test the accuracy of the system as it is being trained and check whether the model is improving over time. The number of correct predictions made upon the test set indicates the accuracy of the model.
Of the 7130 sounds in our dataset, 6500 (~91%) were used for training and 630 (~9%) for testing. The data was randomly shuffled before splitting.
Each audio file is 2 seconds long with a sample rate of 44100 - that means 88200 data points per file! To find patterns in so much data, it is essential to digest each file by looking at the patterns that exist in smaller areas of the data (i.e. receptive fields) and slowly reduce the amount of data through dimensionality reduction (i.e. max pooling).
This is why our TensorFlow architecture comprises a Convolutional Neural Network (CNN) starting with a convolutional layer and then a fully-connected layer.
Convolutional Layer
Training starts at the convolutional layer with input audio data represented as very tall and wide, as shown in the image below. With three rounds of convolution and max pooling, it is slowly “stretched” into the very small and dense shape shown to the right of the image. The width and height decrease due to pooling, and the denseness increases due to the feature maps produced with convolutions.
Below shows the portion of Python code which implements the convolutional layer in Tensorflow.
with tf.name_scope("cp"):
# None and -1 indicate a variable size. During training, they would be the size of the batch.
x = tf.placeholder(tf.float32, [None, 65536], name="x")
x_reshape = tf.reshape(x, [-1, 256, 256, 1], name="x_reshape")
# Reshapes data to: -1, 128, 128, 16
pool_1 = pool_layer(conv_layer([4, 4, 1, 16], [16], x_reshape, "conv_1"), "pool_1")
# Reshapes data to: -1, 64, 64, 32
pool_2 = pool_layer(conv_layer([4, 4, 16, 32], [32], pool_1, "conv_2"), "pool_2")
# Reshapes data to: -1, 32, 32, 64
pool_3 = pool_layer(conv_layer([4, 4, 32, 64], [64], pool_2, "conv_3"), "pool_3")
Fully-Connected Layer
The output from the convolutional layer feeds into a fully-connected layer, which is essentially a neural network that takes the output of the convolutional layer, flattens it, and uses this as the input to the fully-connected layer shown below. The output of this layer is a one-hot vector with probabilities for each classification.
For example, a one-hot vector of [0.8, 0.1, 0.5, 0.5] would indicate an 80% probability that the vocalization within the input audio data is that of a Barn Owl, 10% for Crow, and 5% for the others.
Below shows the portion of Python code which implements the fully-connected layer in TensorFlow.
with tf.name_scope("fc"):
# Input (flattened pool)
# Shape: -1, 65536
pool_flat = tf.reshape(pool_3, [-1, 32 * 32 * 64], name="pool_flat") # 65536
# Hidden
# Weights: 65536, 2048
# Output: -1, 2048
fc_1 = fully_conn(pool_flat, 2048, "fc_1")
# Readout Layer
# Weights: 2048, 4
# Output: -1, 4
with tf.name_scope("fc_out"):
W_fc_out = weight_variable([2048, ONE_HOT]) # 2048, 4
b_fc_out = bias_variable([ONE_HOT])
y_conv = tf.add(tf.matmul(fc_1, W_fc_out), b_fc_out, name="y_conv")
Training a Model
Our training script inputs training data into the model in batches of 50. If batches are too large then TensorFlow will not be able to function as there will not be enough memory to hold them all! The image below shows ffmpeg software reading the audio files at rapid pace for training. When it finishes, the model will be output and ready for use.
The final model yields an accuracy of >99.9%. All data and code used to train the model can be found within the ‘train’ directory of the BirdCNN repository accessible in the Code section of this documentation.
Making PredictionsOnce audio samples have been recorded, we store them in a server. It is here that each recording undergoes preprocessing to get the audio in a suitable format for predictions. The process is as follows:
A simplified version of the script to accomplish this is as follows:
input=<input.wav>
output=<output.mp3>
# Store temporary files in same dir as input
dirname=`dirname ${output}`
filename=`basename ${output}`
# Transformations
convert=${dirname}/convert_${filename}
sample=${dirname}/sample_${filename}
normal=${dirname}/normal_${filename}
profile=${dirname}/${filename}.profile
reduce=${dirname}/reduce_${filename}
silence=${dirname}/silence_${filename}
reshape=${dirname}/reshape_${filename}
# Convert to MP3
sox ${input} ${convert}
# Adjust sample rate and convert to mp3
sox ${convert} -r 44100 ${sample}
# Normalize
sox --norm ${sample} ${normal}
# Noise reduction
sox ${normal} -n trim 1.5 0.4 noiseprof ${profile}
sox ${normal} ${reduce} noisered ${profile} 0.4
# Trim long period of silence at start
sox ${reduce} ${silence} silence 1 0.1 1% -1 0.1 1%
# Pad or trim audio to 2 seconds
duration=`sox --i -D ${silence}`
needspadding=`echo "${duration} < 2" | bc`
if [[ ${needspadding} -eq 1 ]] ; then
padding=`echo "2 - ${duration}" | bc`
sox ${silence} ${reshape} pad 0 ${padding}
else
trimming=`echo "${duration} - 2" | bc`
sox ${silence} ${reshape} trim 0 2
fi
# Output
sox ${reshape} ${output}
Once the recording has been preprocessed, it is fed into a program that runs it against the TensorFlow model. The model’s variables are loaded into the CNN and the new (preprocessed) audio clip is passed through it from start to finish. The weight variables will take this new input and manipulate it until it reaches the one-hot vector/array at the end of the fully-connected layer. The array index with the largest probability is used as the final predicted bird species.
DemonstrationUsing the Edison-powered recorder, we managed to capture a few additional Crow and Barn Owl sounds for demonstration. These were sent from the Edison to a server of our own via FTP.
A demonstration of the system is shown in the video below. The video depicts .wav files being delivered to an ‘/upload’ folder from the Edison. The script (in the command line) identifies, preprocesses, and makes a prediction upon the audio before moving it to the ‘/predictions’ folder in an .mp3 format so the user can see what prediction was made and listen to the sample. Barn Owl and Crow samples were uploaded to the server and both correctly identified.
A simplified version of the script used in the video is as follows:
# Files and directories
edison=./edison
uploads=${edison}/uploads
predictions=${edison}/predictions
temp=${edison}/preprocessed
echo "Listening for new .wav files..."
while true; do
for file in ${uploads}/*.wav; do
basename=`basename ${file}` # $file => example.wav
filename=`echo "${basename}" | cut -f 1 -d '.'` # example.wav => example
tempfile=${temp}/${filename}.mp3
# Preprocess
sh preprocess.sh ${file} ${tempfile}
# Predict
predict=`python3 predict.py ${tempfile} | grep -o 'Predict -.*'`
# Store prediction in ./edison/predictions
store=${predictions}/${filename}_${predict}.mp3
sox ${file} "${store}"
done
done
All data and code used to perform these predictions can be found within the ‘predict’ directory of the BirdCNN repository accessible in the Code section of this documentation.
Future DevelopmentsWhile this system focuses on bird identification through predictive modelling, future developments of the system could include data localisation for fully automated bird migration tracking. Fleets of the Edison hardware could be placed around woodland areas across the country/world, constantly identifying the surrounding birds and tracking when they pass by the individual units to track how birds migrate with minimal human involvement.






_3u05Tpwasz.png?auto=compress%2Cformat&w=40&h=40&fit=fillmax&bg=fff&dpr=2)
{kind=link}
Comments
Please log in or sign up to comment.