


Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
| ||||||
 |
| |||||
 |
| |||||
 |
| |||||
| ||||||
| ||||||
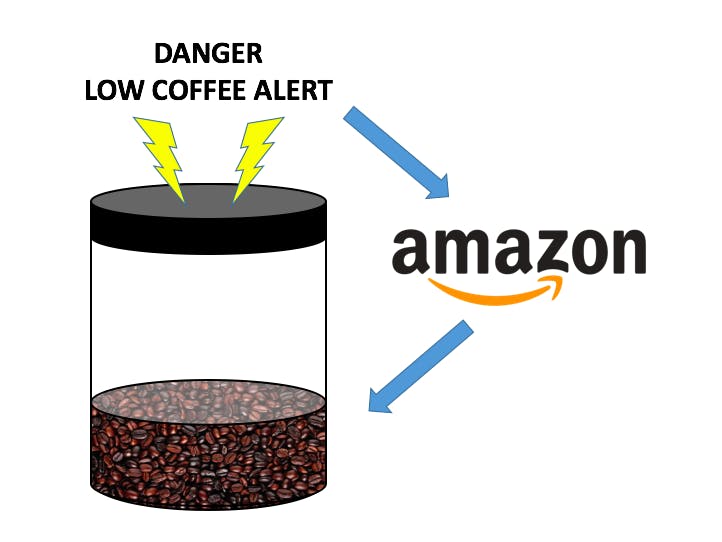
Do you ever start your day off without Coffee? It's not a fun way to start the day when you come down only to find out that you're out of coffee beans. I set out to create a low-friction experience for our kitchen that could stay ahead of running low by leveraging the power of a Raspberry Pi, image recognition AI, and DRS services from Amazon.
Design AlternativesBuilding useful household IoT products is more than a technology challenge. It requires design thinking and product testing to validate applicability with a broad base of consumers. For example, here's a sample photo of my initial iteration of the coffee bean monitor.
To an engineer like me that enjoys spending my weekends soldering, this looks really impressive. Maybe I could I add a few LED's to show that the sensor is working too? To most people (and the average consumer if you want to turn this into a Kickstarter campaign), this looks like a bunch of wires sticking in a coffee canister on a beautiful kitchen counter. There also is the problem around durability. What happens when a coffee gets spilled onto the Raspberry Pi? The sonar sensor is cool, but not sure it was ever tested to be stuck in a container with acidic coffee beans.
Creating a fulfillment product that will be broadly adopted needs to not have wires shooting out from all sides, and unnatural tethering to a power supply. Having others (a spouse, friend, sibling) that aren't deeply involved in technology is a huge asset for usability testing as they are more likely to represent the broadest customer segment. In early stages of product development, I tested out different sensors (i.e. distance and light) but both required significant modifications to the container, particularly when embedding the sensor and a power supply.
This all changed when my design switched to using image processing given that the monitoring device can be decoupled from the actual consumer product. It's called JavaWatch, and it's a DRS enabled device.
Image Processing complementing IoTWhen thinking of IoT products, image recognition and detection is likely to play a surprisingly significant role in making products mainstream. It enables separation between the end product and sensors that acquire the data. This reduces the "friction" in product design, and in some cases enables dual-mode products that can be used with our without the technology. For example, the coffee bean canister that I used in my product didn't require any physical modifications. That has significant implications for adoption as my JavaWatch device can be compatible with items that consumers already have in their kitchen. Extending the product to other applications, like monitoring cereal quantity, a fruit basket, or other visible containers just requires changing software deployed in the Cloud.
JavaWatch ArchitectureThere are three main components involved in this architecture. First is the device itself - a physical image sensor that will be within the home with the hardware driven by a Raspberry Pi and camera. Ideally these would be mass produced, and everyone could buy them for their own use. Next is the website that once users acquire a JavaWatch device they will need to go to to register, and make their coffee bean selection for what Amazon will send them when they get low. This website accessible to anyone on the internet via https://www.javawatcher.com and the source code is in the GitHub repo. Next is the "brains" which will reside in the Cloud, performing the image processing component. The orchestration will be driven by various Lambda functions. Lambda is a serverless computing service by AWS that can also include the rules determining when to call in a refill using DRS. I'm leveraging the AI capabilities of the Rekognition service for image processing, and S3 to host and process the images out on the cloud. Here's a visual of the different components.
I'm using two different software languages to write code for JavaWatch. On the Raspberry Pi, I'm using python as well as the SDK from AWS called Boto. For the Lambda functions, they're written in both Python and NodeJS and the data structures are in JSON (JavaScript Object Notation).
Now let's build!
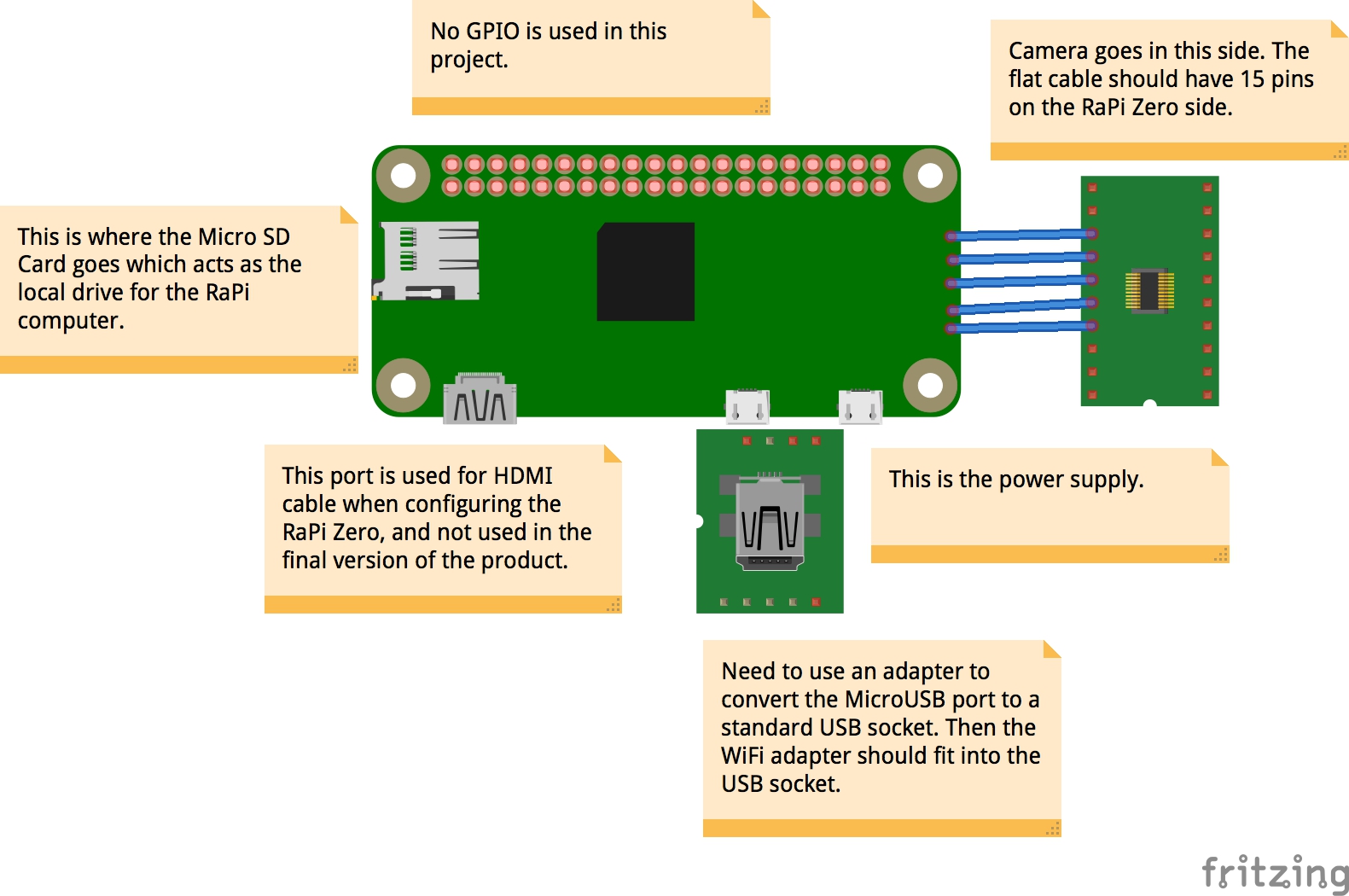
Step 1 - Construct JavaWatch (the DRS enabled device)I selected to use a Raspberry Pi Zero given that it has a small surface area for the board, and takes up the least amount of space in the kitchen. Our goal with the sensors is to make them as hidden as possible, and not detract away from the consumer experience. To assemble the JavaWatch unit, here is the complete part list. These parts retail for about $50, and can be assembled in an hour.
- Raspberry Pi Zero Board
- Raspberry Pi Camera
- Raspberry Pi Zero 15 pin Camera cable (This is for the smaller size port used by the zero. Unfortunately older cables used by the RaPi 1/2 won't work).
- WiFi USB Adapter
- MicroUSB to USB A Socket
- Micro SD Card
- Power Supply
A schematic is attached to this project, but there isn't any wiring involved, rather it's the assembly of components, then initializing the software described in the next section. Once you have the device built, boot it and configure the WiFi on the device to connect to your network.
Here's a photo of the end product in my kitchen. It's mounted on the wall, and close to a power source. The white dongle is the WiFi along with the converter to the micro socket.
Within the kitchen, it can be hidden while still being in "sight" of the coffee bean supply that it is entrusted to guard. Unlike the introductory video, see how this blends into the background? This is the difference between a product that works in a lab, and one that will be purchased by a million consumers.
Step 2 - Program JavaWatchInitial configuration of the Raspberry Pi will require a few additional packages that aren't included on the current Raspbian distribution.
- Clone the repo attached to this project. For reference, here is the direct link.
- Install Boto3. This is used to communicate with AWS.
- Create a user within the IAM console, and attach permissions to be able to write to a S3 bucket.
- Generate an access key for the user, and copy the credentials into the aws.config file.
I wrote a simple python script that runs on the PiZero recursively to capture pictures, write it to both local storage as well as upload to the Cloud. It's in the attached GitHub repo as photo.py, and here's the salient code. When posting to AWS, it puts the image twice to the S3 bucket, once it overwrites the current.jpg object so that we always have the latest view from the camera, then another in an archive folder for historical tracking with the timestamp embedded in the object name.
camera = picamera.PiCamera()
camera.vflip = True
camera.hflip = True
# set resolution of the camera - this should be about a 500kb file
camera.resolution = (1200, 600)
camera.start_preview()
# overlay timestamp on top of the photo and use a black background
camera.annotate_background = picamera.Color('black')
# sleep to give the camera time to warm-up and focus
time.sleep(5)
# capture the photo to a local file system
camera.capture('temp.jpg')
# connect to AWS using credentials unique to the account and saved in a local config file
session = Session(aws_access_key_id = AWS_ACCESS_KEY_ID,
aws_secret_access_key = AWS_SECRET_ACCESS_KEY,
region_name = 'us-east-1')
s3 = session.resource('s3')
# configure the correct S3 bucket and API parameters
image = 'temp.jpg'
bucket = 'javawatchdrs' #todo: change to your bucket name
target_name = 'current.jpg'
# this will read the temp image and update to the current garden view
data = open(image, 'rb')
s3.Bucket(bucket).put_object(Key=target_name, Body=data, ACL='public-read')
time.sleep(5)
# this will add the image to the archive setting the naming convention below
curr_hour = curr_dt_tm[:10] + '-' + curr_dt_tm[11:13] + '.jpg'
data = open(image, 'rb')
s3.Bucket(bucket).put_object(Key='archive/'+curr_hour, Body=data, ACL='public-read')
Given that we need to upload the images to AWS for processing, we need to configure the credentials on the Raspberry Pi. Here are the steps required using the IAM console to create a user ID, then generate an access key that will be setup on the RaPi. Once you've completed this, copy the credentials to the aws.config file that is read in by the python script.
To store images at AWS, you'll need to create an S3 bucket within your account. The bucket acts as a virtual folder on the internet where images from the Raspberry Pi can be posted to by the photo.py script. The script running is taking photos at intervals during the day, and deferring any logic to the next step.
As part of creating the S3 bucket, make sure and add CORS (Cross-Origin Resource Sharing) else the Rekognition service won't be able to access. The name of this bucket needs to be included in the python script above - for reference, I'm using the javawatchdrs bucket name.
<CORSConfiguration>
<CORSRule>
<AllowedOrigin>*</AllowedOrigin>
<AllowedMethod>GET</AllowedMethod>
<MaxAgeSeconds>3000</MaxAgeSeconds>
<AllowedHeader>Authorization</AllowedHeader>
</CORSRule>
</CORSConfiguration>
After you have completed this step, you will have a JavaWatch device that is constantly uploading photos of the coffee canister in your kitchen. Take some time to validate this by inspecting the photos that are in the S3 bucket you created, and reposition the device as necessary.
Step 3 - Create 3rd Party Device Companion Application (i.e. javawatcher.com )When building JavaWatch, I needed to create it as an officially registered device with Amazon.com. This includes setting up the authentication that will enable individual users of the JavaWatch to login and identify that they are using the device as well as the ordering options with the device. Here's how the different pieces fit together once this is all setup.
This required registration within the developer console that identifies options of what products can be fulfilled when the end user runs out of coffee beans. Here are the screenshots that show what was setup.
After the device is registered, we need to create a slot that represents what will be reordered - for JavaWatch it is a small (10-12oz) bag of coffee beans. The slot needs identification of different types of coffee that the end user could select. For each choice, a ASIN (Amazon Standard Identification Number) must be provided, and it needs to fit within a set of guidelines for the program.
Here are the steps required to get each ASIN.
1 - Find a whole bean coffee that looks good using the Amazon.com website.
2 - Find the ASIN (Amazon Standard Identification Number) on the Product Details page.
3 - Product must be "Shipped & Sold" by Amazon.
Here's an example using screenshots from the Amazon.com retail website that help identify the ASIN.
With the different products selected, we can then list all of these in the slot for the Device we have created. This is done through the DRS section of the Amazon developer console.
Companion Website for Registering Device
To setup the website (javawatcher.com), we're going to use Amazon S3 to host the html files, then connect to LWA/DRS. Here is what the page flow will end up looking like, and the html files are in the GitHub repo.
Here is the start page, and is just basic html.
The next page is where the hook resides to get into LWA & DRS.
Note the following Javascript that is in the page that will open the next window when the "login with Amazon" button is clicked. This ties together the client ID from the LWA setup section, as well as the product ID from the DRS setup section.
function lwaFunction() {
var str = String(window.location);
var pos = str.indexOf("code=");
if(pos == -1)
{
var x1 = document.getElementById("frm1");
var productid = String(x1.elements[0].value);
var serialno = String(x1.elements[1].value);
window.open("https://www.amazon.com/ap/oa?client_id=amzn1.application-oa2-client.<your client id here>&scope=dash%3Areplenish&scope_data=%7B%22dash%3Areplenish%22%3A%7B%22device_model%22%3A%22"+productid+"%22%2C%22serial%22%3A%22"+serialno+"%22%2C%22is_test_device%22%3Atrue%7D%7D&response_type=code&redirect_uri=https%3A%2F%2Fs3.amazonaws.com%2Fjavawatchdrs%2Fregistration.html");
}
}
Here are the pages you will be taken to.
In addition to the confirmation page that gets rendered in the browser, there's also an e-mail notification that comes through from Amazon indicating that the coffee I selected in the setup is now being shipped. Here's what it looks like, and contains details from what was entered in the device registration process.
If there's an error and the customer needs to cancel the order, they can do so like any other Amazon order.
Step 4 - Image Processing and Order RequestThe prior two steps involved getting images to the Cloud, now we need to apply logic to them evaluating what is in the image. This is done with the image processing service called Rekognition, and if you want to try it out with pictures of your own, here are the product details from AWS.
Once the image of the coffee dispenser is uploaded to S3, a Lambda function is invoked that then evaluates what the images contain. This is done via a request response model, and the processing is rather straight forward.
The response model that Rekognition provides for image recognition includes an attribute called a "label". These are predefined by the service, and don't require any training using predefined datasets. When the Rekogintion API is invoked, the labels come back in the response, and each has a confidence level attached to it.
from __future__ import print_function
import boto3
from decimal import Decimal
import json
import urllib
print('Loading function')
rekognition = boto3.client('rekognition')
# --------------- Helper Functions to call Rekognition APIs ------------------
def detect_labels(bucket, key):
response = rekognition.detect_labels(Image={"S3Object": {"Bucket": bucket, "Name": key}})
return response
# --------------- Main handler ------------------
def lambda_handler(event, context):
# Get the object from the event
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.unquote_plus(event['Records'][0]['s3']['object']['key'].encode('utf8'))
print("Image Name: " + key)
try:
# Calls rekognition DetectLabels API to detect labels in S3 object
response = detect_labels(bucket, key)
# Print response to console.
print(response['Labels'])
return response
except Exception as e:
print(e)
print("Error processing object {} from bucket {}. ".format(key, bucket) +
"Make sure your object and bucket exist and your bucket is in the same region as this function.")
raise e
Now interpreting the response message isn't as simple as a normal sensor. What we're doing in the image processing is a type of negative logic. When presented with a full container of coffee beans (image below).
Here is the response that comes back from the API call.
{
"Labels": [
{ "Confidence": 84.64501190185547, "Name": "Bottle",
{ "Confidence": 84.64501190185547, "Name": "Jug",
{ "Confidence": 84.64501190185547, "Name": "Water Bottle",
{ "Confidence": 80.8670425415039, "Name": "Jar",
{ "Confidence": 73.33070373535156, "Name": "Bean",
{ "Confidence": 73.33070373535156, "Name": "Produce",
{ "Confidence": 73.33070373535156, "Name": "Vegetable"
],
"OrientationCorrection": "ROTATE_0"
}
When the level begins to drop (photo below).
Here is the response. The labels change some, but still seeing the beans.
{
"Labels": [
{ "Confidence": 88.48421478271484, "Name": "Jar",
{ "Confidence": 74.14774322509766, "Name": "Bean",
{ "Confidence": 74.14774322509766, "Name": "Produce",
{ "Confidence": 74.14774322509766, "Name": "Vegetable"
],
"OrientationCorrection": "ROTATE_0"
}
Still further drop (photo below).
Returns this response.
{
"Labels": [
{ "Confidence": 94.05787658691406, "Name": "Bottle",
{ "Confidence": 94.05787658691406, "Name": "Jug",
{ "Confidence": 94.05787658691406, "Name": "Water Bottle",
{ "Confidence": 80.77616882324219, "Name": "Jar",
{ "Confidence": 63.5648078918457, "Name": "Alcohol",
{ "Confidence": 63.5648078918457, "Name": "Beer",
{ "Confidence": 63.5648078918457, "Name": "Beer Bottle",
{ "Confidence": 63.5648078918457, "Name": "Beverage",
{ "Confidence": 63.5648078918457, "Name": "Drink"
],
"OrientationCorrection": "ROTATE_0"
}
It no longer sees any beans, so it's time to reorder. This kicks off a separate lambda function to call the DRS service to do so.
A good observation is that interpreting the responses isn't as straight forward as what reading a height or weight sensor is that gives a number that linearly corresponds to the amount of beans in the jar. The AI of the Rekognition service is a little bit of a brain dump of everything that is in the field of view of the image. The answers aren't wrong either - it's just that we don't care about the "Jar" label, or that the beans might also be "Produce".
There's the straight forward approach of parsing through the results and seeing if the "Bean" attribute exists. For a binary switch, that's okay and we know if it falls out of the array, it's time to order up some more beans, and here's the lambda function that parses through all of the labels, and returns an indicator if it's time to order more coffee.
exports.handler = (event, context, callback) => {
// Event is passed in to the function from Rekognition
labels = event.Labels;
var beansFound = false;
// check all of the labels provided, and set boolean to true if Beans are found
for (i = 0; i < labels.length; i++) {
console.log(JSON.stringify(labels[i]));
if (labels[i].Name == "Bean") {
beansFound = true;
}
}
// return boolean if beans were found in the labels for the image
callback(null, beansFound);
};
What's next? With the goal of creating as low-friction of a consumer experience as possible, my next round of improvements will be to simplify further. A next step could be to manufacture the JavaWatch devices, and attempt to get economies of scale to get the price point lower than $50 for the items listed on the BOM. Alternatively, one way of getting these costs low would be to eliminate the RaspberryPi and build the JavaWatch as an app that is compatible with smartphones. There are a few significant advantages with this approach. First is cost, as it eliminates parts to purchase and assemble, and the distribution network would be simplified. Second is in improving the quality of the images being captured. This improves the decision making, and reducing false positives. Finally, by making the capturing device mobile, and under full control of the customer, it could move beyond coffee beans, and could start to fulfill on a variety of items. Imagine being able to take a photo of your fridge, having an inventory being taken, then whatever is missing fulfilled on?
ConclusionThe technology for order replenishment has different options, but when building consumer products, it's critical to factor in what belongs in a science lab vs. your kitchen. Hardwired sensors may make sense for coffee makers, dishwashing machines, etc., but there are plenty of other items that we want to touch that image processing will play a key role in. Looking ahead 5-10 years into the future, I believe it's more likely that our cupboards and refrigerators will be using image scanning and AI to ascertain inventory, than each object having an embedded sensor. This will be more effective from a cost perspective, and far less impact to the supply chain around creating and packaging products.





{kind=link}
{kind=link}
Comments
Please log in or sign up to comment.