



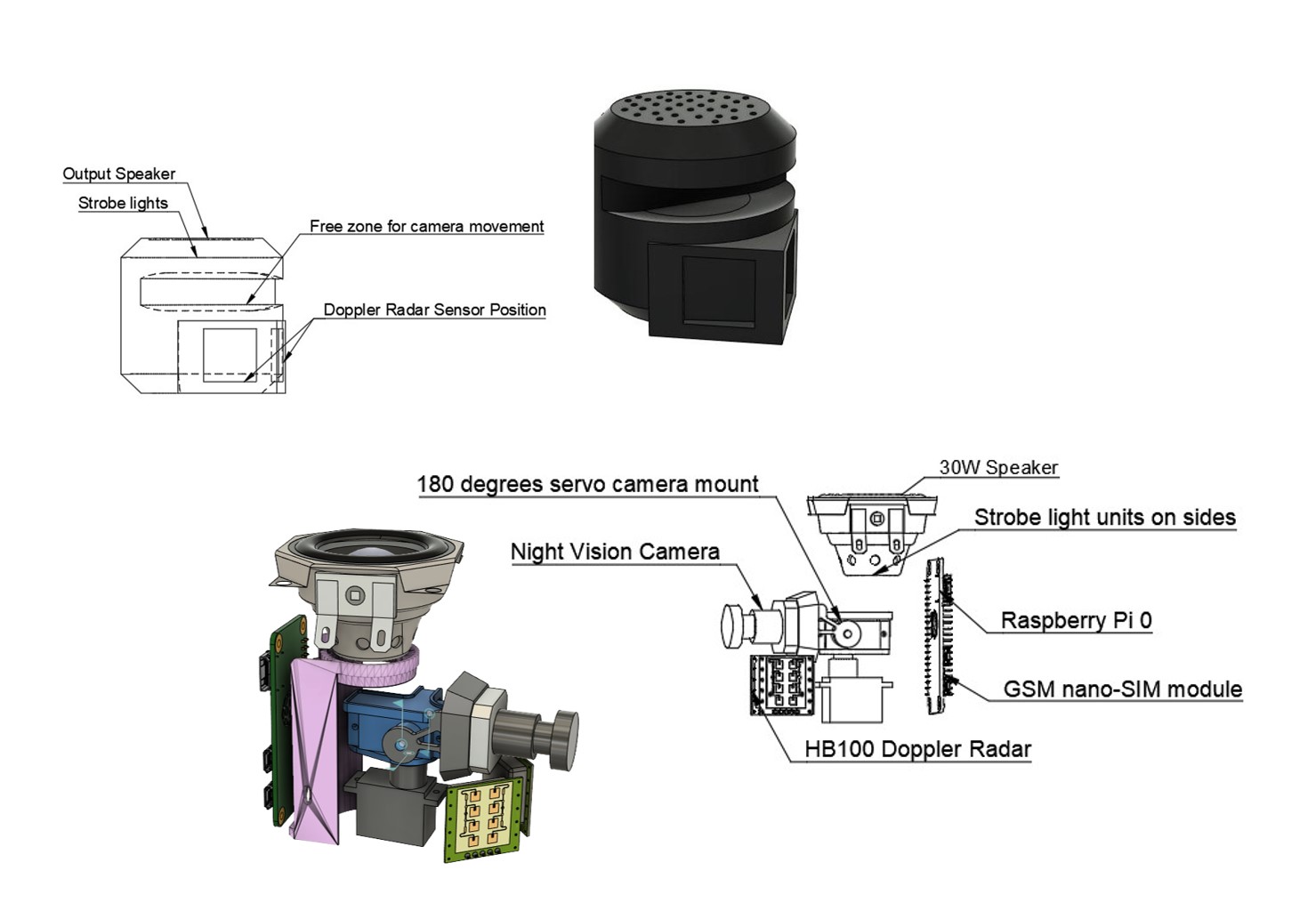
Hardware components | ||||||
| × | 1 | ||||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
Farmers in India and abroad face serious threats from pests, natural calamities, thefts, damages by animals and other types of crop losses, resulting in lower yields. Most often, none of the steps taken to counter the problems is foolproof. Indian states like Uttarakhand, Jharkhand, Kerala, etc. have a huge problem of Human-Wildlife Conflict where thousands of crop-raiding cases are getting reported annually. Apart from the traditional practices that farmers use to protect their crops from animal intrusions, there are not many technical solutions available to help them. Existing methods like electric fences are no longer efficient in the case of elephants because they break the fences with the help of wooden logs and enter the farmlands. Once the herd of animals enters the farms, it is extremely difficult to scare them away because they have got immune to human tricks. It is also extremely dangerous for the farmer to confront a wild animal. The farmers are not only troubled by elephants but wild boars, deers, money, nilgais (aka Blue Bull) too.
The raging conflict between humans and animals in the state of Jharkhand of India have killed 1,405 people and around “80 elephants” since the state was created 19 years ago. On average, the two faces off every day, killing 74 people every year and injuring at least 130, say documents accessed by The Indian Express.
According to statistics from the Kerala forest department, from 2010 to 2020, 173 people die in human-animal conflicts. The highest number of deaths were reported in 2016 – 33 – and the lowest in 2015, of six. In the same period, 64 elephants died after being hunted, electrocuted, hit by speeding vehicles and from explosions.
“Nilgais eat all crops except mustard. Every time I find this animal destroying my crop, I want to kill it right there. But, I control myself because I will face legal action and anger from fellow villagers, who will call me a murderer of a sacred animal,”
"Bihar, UP, MP intended to cull nilgai and wild boar as vermin for five years. Notorious for destroying crops, the largest Asian antelope found in abundance is a vermin now. The farmers can kill them to save their crops, with permission from forest authorities. There have been proposals to declare at least 12 wild animals—elephants, wild boars, Indian porcupine, Indian gaur, sambar, bonnet macaque, common langur, barking deer, mouse deer, blacknaped hare, malabar giant squirrel and peafowl— vermin in the past." - The situation has become severe in many parts of India since farmers have stopped farming because of mounting loss done by wild animals, if we don't have a solution for it now maybe we won't be able to prevent killing lust among farmers for these animals.What can be the solution?
As deforestation and growing human populations push people and wildlife ever closer together, these conflicts are becoming more frequent. But what if a tiny, barely visible camera with a very smart brain could stop a conflict before it starts?
Our new system called Kheti Kavacha (Hindi words for Farm Shield) may provide an early warning that could save the lives of both animals and humans. This project provided a very well-detailed POC (proof of concept). I have been working on this project for the last several months, from collecting tiny bits of information to testing ideas. There has been the traditional way of deterring animals- mainly by wildlife conflict training and deterrent kits, that deploy light, noise, and trunk-tickling chilli pepper to humanely turn elephants and other animals away from fields.
But this system has drawbacks too that is - " Crop raiders act fast, and one of the critical and weak points of response is its rapidity. Most of the time these animals raids occur at night. Lack of sleep for farmers erodes ability to function and being alert, and guarding fields during cold and wet periods can be very distressing for farmers. Our solution could potentially help farmers to be awake only if and when there is a real threat. ”
Scarecrow technology has a long history of ignominious failure, and not just for elephants – animals quickly learn to tune out a deterrent if it becomes apparent that there is no threat. But this can be solved at some stages if AI and Computer Vision are involved and that too at a tinyML level, it would be a boon for the communities and huge plantations as it would get cheaper.
How did it start?I started with making a simple PIR based alarm unit for farms (POC 1.0) like this https://www.electronicshub.org/pir-sensor-based-security-alarm-system/ and it worked for most of the time but not for several months as the animals are smart and got used to it. I also knew the problems of ordinary solutions like using PIR sensors combined with Audio MP3 player modules and strobe lights (they are full of false triggers and anybody can make it but it is sold in the markets by companies for more than $300 check below pricing and PIR vs Radar comparison image, very expensive and nothing special, check yourself 👉 https://kyari.in/aniders/ ) PIR and AIR has many disadvantages too.
With my first idea, using Raspberry pi Nano, cheap mmWave doppler radars and Edge Impulse models, and it was quite promising for elephant detection. Nothing complicated, it was just a simple three-step solution:
- Sensors that detect animal is approaching and their distance,
- A processing brain to identify them and decide how best to respond
- And deterrent devices that can respond intelligently with the right combination of sound or light, loaded with a library of predator sounds, animal alarm calls and irritating tones, as well as its own self-generated noises – anything we would consider as “scary or startling".
These can be scattered widely to encompass any area that needs protection, even if it’s the size of a plantation. My solution is more than 80% feasible because the current market devices like mentioned above https://kyari.in/aniders/, just play random sounds for a specific interval but animals become smarter and get used to the sounds however in our case we detect each animal and use bioacoustic and scary sounds proven to work for that particular animal. The trick here is to observe animals, understand their movement pattern and deploy a good number of our Kheti Kavacha devices at appropriate places and confuse and scare them.
It was a good approach to tackle the problem with less expensive hardware but had few problems which I will explain in the next steps, first let's see this solution.
Training Edge Impulse Model for Elephant detection (since Edge Impulse free runtime has limits so I am going to shorten the training process).
You can use a custom neural net model as well, I did not hard-code the number of filters, their size or the size of fully connected layers, it was just a small simple Convolutional Neural Network with a small number of layers I chose,
model = models.Sequential()
model.add(Conv2D(FilterNum1, FilterSize,
activation='relu',
padding="same",
input_shape=(320,320, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(FilterNum2, FilterSize,
activation='relu',
padding="same")
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(FilterNum3, FilterSize,
activation='relu',
padding="same")
model.add(Flatten())
model.add(Dense(DenseSize, activation='relu'))
model.add(Dropout(DropoutRate))
model.add(Dense(4), activation='softmax')To run the model and test in locally run these Edge Impulse commands;
$ curl -sL https://deb.nodesource.com/setup_12.x | sudo bash -
$ sudo apt install -y gcc g++ make build-essential nodejs sox gstreamer1.0-tools gstreamer1.0-plugins-good gstreamer1.0-plugins-base gstreamer1.0-plugins-base-apps
$ npm config set user root && sudo npm install edge-impulse-linux -g --unsafe-perm
# Connect to Edge Impulse
$ edge-impulse-linux
# run your impulse locally
$ edge-impulse-linux-runnerBelow is the hardware setup for the initial POC with Raspberry Pi. Code is attached at the end, code is fairly simple - EDGE Impulse Inference runs which returns animal detected and if animals is an elephant (the model we had trained above) then using vlc library to play audio files stored along with led flashing patterns, for strobe light effect I am using Matrix Creator board with 35 wRGB LEDs. (I tried using radars but better to go with expensive radars to get accurate distance and 4D point cloud data and it would be more accurate and robust than PIRs).
$ pip install python-vlc
# Install HAL packages and drivers for Matrix Creator board
# Add repo and key
$ curl -L https://apt.matrix.one/doc/apt-key.gpg | sudo apt-key add -
$ echo "deb https://apt.matrix.one/raspbian $(lsb_release -sc) main" | sudo tee /etc/apt/sources.list.d/matrixlabs.list
# Update repo and packages
$ sudo apt-get update
$ sudo apt-get upgrade
# Install MATRIX HAL Packages
$ sudo apt-get install matrixio-creator-init libmatrixio-creator-hal libmatrixio-creator-hal-dev
# Reboot the system
$ sudo reboot
# MATRIX Lite Python library to control on board peripherals
$ python3 -m pip install --user matrix-liteThe below shown evaluatory stages were used to assess the long term benefits of my Kheti Kavacha solution.
The benefits were as follows (with this POC 2.0 I got some support from Indian government incubation schemes and people but due to Covid I was unable to make a functional MVP early):
- The solution to accurately determines the presence of animals in farms which saves unnecessary high-intensity noise and battery consumption due to higher false triggers unlike available methods of loudspeakers and lights used currently to scare animals in farms.
- Cause no harm to animals, unlike electric fencing, brutal traps, and hazardous chemicals, save farmers and animals life from human-wildlife conflicts. No manual guarding of the farm is required at night.
- Device powered by Radars and Night vision cameras to detect animals and targeted sound playback to scare them, send all information to the dashboard as well. Using the conventional way but in more efficient and in better terms of technology.
- Detection range around 20-30 meters, multiple devices increases range to cover entire farm. Solar-powered as well.
The device was able to detect animals and play a variety of sounds and light patterns but it was still much inefficient in terms of power usage, Raspberry Pi firstly runs too many tasks which requires constantly to be awake, other peripherals too needed higher power usage. So I needed something smaller and less power demanding than raspberry pi so that I can power the rest peripherals. So more on the technology side, I was looking for a microcontroller-based innovation than a Single Board Computer like Raspberry Pi. This intuition led to our POC 3.0 which would be focused on the below points:
- Lesser power consumption
- Microcontroller based rather than SBCs
- The use of a stereo depth camera for greater vision, not only makes the AI better-placed recognize its target but also prepares the system to recognize it from any angle.
- This includes high above the ground, where the camera will be out of reach from destructive creatures like elephants, or from humans who don’t want to be caught stealing.
For our POC 3.0, I decided to use Luxonis-ESP32 (aka OAK-D-IOT-40) as the main module. It has numerous benefits that would easily beat our POC 2.0. Let's learn about Luxonis-ESP32 and why it is the best option for the Kheti Kavacha device.
Luxonis-ESP32 has a baseline of 4cm and by varying the resolution and stereo depth mode, we get the following minimal depth perceiving distances:
- Min distance (800P): ~ 37cm
- Min distance (400P): ~ 19.6cm
- Min distance with extended disparity (800P): ~ 19.6cm
- Min distance with extended disparity (400P): ~ 19.6cm
- Maximal perceiving distance for Luxonis-ESP32(OAK-D-IoT-40): 21 meters
So we can easily detect animals within 21 meters, even other Luxonis IoT camera modules allow up to 40 meters range based upon stereo camera alignment. Using stereo cam we can
Below is the device connection and logics overview,
DepthAI device ┌─────┐
┌───────────────────────────────────────────────┐ │ ◎ │
│ │ │ │
│ ┌───────────────────ESP32───┐ │ BT | |
│ │ │--│◄───►| |
│ │ (Your ESP32 firmware) │ │ └─────┘
│ │ │ │ ┌──────────┐
│ │---------------------------│ │ │ │
│ │ depthai-spi-api │--│◄───────►├──────────┤
│ └───────▲───────────────────┘ │ WiFi │ Server │
│ │ │ ├──────────┤
│ │SPI │ │ │
│ Right │ │ └──────────┘
│ ┌───┐ ┌───┬────▼───┬─MyriadX(VPU)──┐ │
│ │ ◯ │--►| │ │ │ │ Host
│ ┌───┐ └───┘ │ │ SpiOut │ ┌─────────┤ │ ┌───────────┐
│ │ ◯ │--------►| └────────┘ │ │ │ │ │
│ └───┘ ┌───┐ │ │ XLinkIn │ │ XLink │ │
│Color │ ◯ |--►| (Your pipeline) │ XLinkOut│--│◄──────►│ │
│ └───┘ │ │ │ │ └────┬─┬────┘
│ Left └──────────────────┴─────────┘ │ │ │
│ │ ──┴─┴──
└───────────────────────────────────────────────┘The real interesting features are:
- Can run on +5V power supply,
- Run spatial object detections and/or object tracking pipeline on the Myriad X VPU and send tracklets with spatial data over the SPI to the ESP32
- ESP32 can also flash DepthAI bootloader and/or pipeline, which means OTA (over-the-air) updates are supported.
- Sending data to the cloud (eg. AWS/Azure/GCP or any other IoT platform) through the ESP32 module
Hardware setup:
For this POC we are only going to use Lux-ESP32 and Sparkfun Quiic I2C OLED Display module. In the final stage prototype, I will also add GPS, audio and LED driver modules (the GPIO pin holes on the Lux-ESP32 is very small, making it difficult for me to add the above modules, planning to make a separate PCB to connect all modules via I2C). Radar would be used as a trigger device to wake up ESP32 and allow it to send commands to Lux-ESp32 running Depth AI pipeline to analyze the animal triggered,
Development Process (On the host machine):
Step 1:
- Install required dependencies from the Luxonis Depth AI documentations https://docs.luxonis.com/projects/api/en/latest/install/#supported-platforms
- Install DepthAI package,
$ python3 -m pip install depthai Step 2:
- Install the ESP-IDF, instructions here.
- After setting up the environmental variables, you can build any demo from the esp32-spi-message-demo repository with idf.py build.
- After building, you can flash your ESP32 using
idf.py -p PORT flash monitor(replacePORTwith the ESP32 port, eg./dev/ttyUSB0). You might need to change the permission of the port withsudo chmod 777 PORTso idf.py can access it. - After flashing the ESP32, you can start the pipeline. If you have used a demo ESP32 code, you should run the corresponding python script from gen2-spi demos.
Firstly, we will acquire a dataset and label them, I used Roboflow (I loved it). Check the below images for labelling and augmentation, I used two classes elephant and deer. After all, annotations are done, download all datasets with corresponding XML annotation files to be used during the training process.
All codes are attached at the end. Training script is provided by Luxonis Depth AI documentation, https://colab.research.google.com/github/luxonis/depthai-ml-training/blob/master/colab-notebooks/Easy_Object_Detection_With_Custom_Data_Demo_Training.ipynb Once the model is trained it needs to be converted to blob format, Luxonis also provides an online blob converter that provides an easy access to converting OpenVino models for different versions and shave counts: http://blobconverter.luxonis.com/
SDG Goals:Life on Land:
Wildlife-human conflict is a major problem leading to mass wastage of land, destruction of crops and loss of animal and human life. Several species like those elephants are endangered.
A more conventional camera trap can be as cheap as $100 and as expensive as $1,000, but these systems don’t offer real-time alerts and actions. Our device Kheti Kavacha not only scare animals away but also gives a real-time alert. And the other part is, how do you make this solution really cheap? Our device can be really cheaper than current market options with good results and accuracy. These sensors could come with added benefits for biodiversity monitoring, as the AI Scarecrow can detect and log all the animals that pass through a given area.
Economic Growth
Mounting crop losses leads farmers to get into more debt and sometimes leading cause of suicide in several parts of our country. Each year government suffers a heavy economic loss due to compensation for wild animals affected farms. Using our device Kheti Kavacha we can protect elephants while giving farmers more good nights’ sleep — their farms are protected not by human eyes, but by AI.
Future Milestones:Once the final prototype and MVP is ready, I am aiming to test this device with several farms and in Partnership with Farmer Producer Organization (FPO’s), KVK’s & The Indian Council of Agricultural Research - ICAR Institutions (PAN India coverage). On evaluating the capabilities of TinyML with Luxonis ESP32 I think there are far more things to discover and experiment with such solutions including, AI-generated alert sound calls, more training models and spatial data tracking(Spatial refers to 3D dimensional data for any real-time object).
I hope you enjoyed reading the project :) I think I explained the POC working very clearly.
_jwCGbp1oUl.jpg)
{kind=link}
_jwCGbp1oUl.jpg){kind=link}

Comments