


Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
| ||||||
In my last project, I demonstrated the initial steps to writing a custom FIR module in Verilog. That project resulted in a LPF FIR that functioned properly in the behavioral simulation, but failed to meet timing requirements when placed and routed into a design.
Starting with the design as is from the previous project, let's walk though how to analyze a design when it fails to meet timing requirements. Timing requirements are first determined in the implementation of a design in Vivado when the logic is being placed and routed in the fabric of the target FPGA chip (in this case it is the Zynq 7020 on the Arty Z7 development board that I'm using).
I chose to import the FIR as an RTL module into a block design for the Arty Z7 where a DDS compiler being streamed phase increment offset values from memory via an AXI DMA (direct memory access) block can input varying frequency sinusoids to demonstrate how the LPF FIR behaves.
Upon running implementation in Vivado and then opening the Implemented Design, the critical warning pops up declaring the design does not meet timing requirements.
To be able to see exactly how the design is failing timing, the bottom window in the Implemented Design contains a tab for the timing analysis Vivado performs on the design during implementation. When signal paths that fail timing are present, a user can filter this timing analysis to only see these violating paths using the red circle exclamation symbol shown in the image below:
In this particular design, there are several signal paths failing their allotted setup timing, meaning that the signals have too far of a physical distance to travel across the chip and/or too many levels of logic to be clocked through before the signals are expected and being clocked into their destination registers. A signal whose setup time is too long means that you can't depend on its value to be valid when you go to clock it into a register, thus making the behavior of the rest of the downstream logic unreliable/unpredictable.
In this case, the data signal s_axis_fir_tdata coming into the AXI Stream input interface of the FIR module is currently taking too long to reach the output of the FIR at the m_axis_fir_tdata destination register. To see more details than what's in the timing analysis window at the bottom of the screen, right-click on the violating signal path in the bottom timing analysis window and select the View Path Report option. You will then be able to see how Vivado has calculated the allowable setup time for that signal compared to what it actually came out to be given the way the HDL for the design is written. This will give you some hint of what's causing the extended setup time. However, I've found to really visualize setup timing violations it's more advantageous to view the signal in the schematic.
To open a specific signal path in the schematic, again right-click on the violating signal path in the bottom timing analysis window and select the Schematic option. A new tab will be opened showing the logic the signal path goes through in the physical layout of the design.
Upon opening a violating signal path for one of the bits in the data bus of axis_fir_tdata, it reveals the design was routed in the chip such that the signal must be clocked serially though 11 levels of logic before reaching its destination.
Now that the analysis of the Implemented Design has revealed which signal paths are an issue for each timing violation, the question is now how do we fix it? In this case, it's clear that the current logic needs to be re-designed to handled smaller chunks of the data in a more parallel manner to shorten the overall path the data is clocked through to its destination register.
I personally prefer to draw out my logic before trying to write any actual Verilog code. The two main programs I've found useful for this are Microsoft's Visio (paid subscription) and Draw.io (free). I find that it's much easier to debug my designs when I have this visual representation of what I want the design to be doing, especially for tracking down issues like this type of timing violation.
Examining my logic design for the current FIR module where the data bus is violating setup timing, it becomes obvious as to how my circular buffer filling serially then sending all fifteen products to the accumulation block to be summed all at once could create a significant amount of delay in processing necessary to obtain the output result.
Instead of trying to fill the circular buffer, then multiplying each buffer by the appropriate coefficient, and summing each of the 15 products all at once, I re-designed the logic to multiply and accumulate (sum) only two registers in the circular buffer at a time in a cascading manner.
The Verilog code for the new FIR module:
`timescale 1ns / 1ps
module FIR(
input clk,
input reset,
input signed [15:0] s_axis_fir_tdata,
input [3:0] s_axis_fir_tkeep,
input s_axis_fir_tlast,
input s_axis_fir_tvalid,
input m_axis_fir_tready,
output reg m_axis_fir_tvalid,
output reg s_axis_fir_tready,
output reg m_axis_fir_tlast,
output reg [3:0] m_axis_fir_tkeep,
output reg signed [31:0] m_axis_fir_tdata
);
/* This loop controls tkeep signal on AXI Stream interface */
always @ (posedge clk)
begin
m_axis_fir_tkeep <= 4'hf;
end
/* This loop controls tlast signal on AXI Stream interface */
always @ (posedge clk)
begin
if (s_axis_fir_tlast == 1'b1)
begin
m_axis_fir_tlast <= 1'b1;
end
else
begin
m_axis_fir_tlast <= 1'b0;
end
end
// 15-tap FIR
reg enable_fir;
reg signed [15:0] buff0, buff1, buff2, buff3, buff4, buff5, buff6, buff7, buff8, buff9, buff10, buff11, buff12, buff13, buff14;
wire signed [15:0] tap0, tap1, tap2, tap3, tap4, tap5, tap6, tap7, tap8, tap9, tap10, tap11, tap12, tap13, tap14;
reg signed [31:0] acc0, acc1, acc2, acc3, acc4, acc5, acc6, acc7, acc8, acc9, acc10, acc11, acc12, acc13, acc14;
/* Taps for LPF running @ 1MSps */
assign tap0 = 16'hFC9C; // twos(-0.0265 * 32768) = 0xFC9C
assign tap1 = 16'h0000; // 0
assign tap2 = 16'h05A5; // 0.0441 * 32768 = 1445.0688 = 1445 = 0x05A5
assign tap3 = 16'h0000; // 0
assign tap4 = 16'hF40C; // twos(-0.0934 * 32768) = 0xF40C
assign tap5 = 16'h0000; // 0
assign tap6 = 16'h282D; // 0.3139 * 32768 = 10285.8752 = 10285 = 0x282D
assign tap7 = 16'h4000; // 0.5000 * 32768 = 16384 = 0x4000
assign tap8 = 16'h282D; // 0.3139 * 32768 = 10285.8752 = 10285 = 0x282D
assign tap9 = 16'h0000; // 0
assign tap10 = 16'hF40C; // twos(-0.0934 * 32768) = 0xF40C
assign tap11 = 16'h0000; // 0
assign tap12 = 16'h05A5; // 0.0441 * 32768 = 1445.0688 = 1445 = 0x05A5
assign tap13 = 16'h0000; // 0
assign tap14 = 16'hFC9C; // twos(-0.0265 * 32768) = 0xFC9C
/* This loop controls tready & tvalid signals on AXI Stream interface */
always @ (posedge clk)
begin
if(reset == 1'b0 || m_axis_fir_tready == 1'b0 || s_axis_fir_tvalid == 1'b0)
begin
enable_fir <= 1'b0;
s_axis_fir_tready <= 1'b0;
m_axis_fir_tvalid <= 1'b0;
end
else
begin
enable_fir <= 1'b1;
s_axis_fir_tready <= 1'b1;
m_axis_fir_tvalid <= 1'b1;
end
end
reg [3:0] cnt;
reg signed [31:0] acc01, acc012, acc23, acc34, acc45, acc56, acc67, acc78, acc89, acc910, acc1011, acc1112, acc1213;
/* Circular buffer w/ Multiply & Accumulate stages of FIR */
always @ (posedge clk or posedge reset)
begin
if (reset == 1'b0)
begin
m_axis_fir_tdata <= 32'd0;
end
else if (enable_fir == 1'b1)
begin
buff0 <= s_axis_fir_tdata;
acc0 <= tap0 * buff0;
buff1 <= buff0;
acc1 <= tap1 * buff1;
acc01 <= acc0 + acc1;
buff2 <= buff1;
acc2 <= tap2 * buff2;
acc012 <= acc01 + acc2;
buff3 <= buff2;
acc3 <= tap3 * buff3;
acc23 <= acc012 + acc3;
buff4 <= buff3;
acc4 <= tap4 * buff4;
acc34 <= acc23 + acc4;
buff5 <= buff4;
acc5 <= tap5 * buff5;
acc45 <= acc34 + acc5;
buff6 <= buff5;
acc6 <= tap6 * buff6;
acc56 <= acc45 + acc6;
buff7 <= buff6;
acc7 <= tap7 * buff7;
acc67 <= acc56 + acc7;
buff8 <= buff7;
acc8 <= tap8 * buff8;
acc78 <= acc67 + acc8;
buff9 <= buff8;
acc9 <= tap9 * buff9;
acc89 <= acc78 + acc9;
buff10 <= buff9;
acc10 <= tap10 * buff10;
acc910 <= acc89 + acc10;
buff11 <= buff10;
acc11 <= tap11 * buff11;
acc1011 <= acc910 + acc11;
buff12 <= buff11;
acc12 <= tap12 * buff12;
acc1112 <= acc1011 + acc12;
buff13 <= buff12;
acc13 <= tap13 * buff13;
acc1213 <= acc1112 + acc13;
buff14 <= buff13;
acc14 <= tap14 * buff14;
m_axis_fir_tdata <= acc1213 + acc14;
end
end
endmoduleRe-running synthesis and implementation of the same design with the new Verilog code for the FIR module does indeed yield a design that meets all timing requirements. And opening the schematic for the same data signal paths that were previously violating setup timing gives visual proof of how the signal paths have been shortened overall.
The new schematic shows the design is now routed such that the signal paths for each of the bits in the axis_fir_tdata bus are now being processed in parallel, effectively cutting down on their arrival time to the destination register. This is what reduces the setup times for the signals.
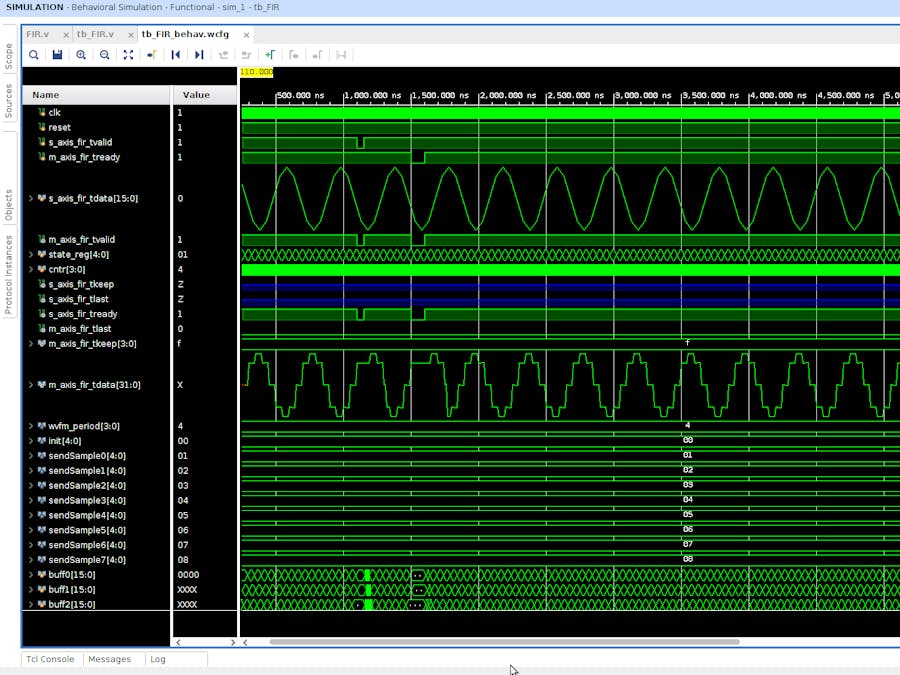
While the new design meets timing, I wanted to verify that the rewritten logic still behaved the same as the old logic. Rerunning behavioral simulation will answer this question pretty fast (check out my tutorial on behavioral simulation if you're unfamiliar with this step).
Since I'm looking to replicate the exact same logic with new code, I found that the capability to set breakpoints and step through each line of Verilog as the waveform graph is being updated came in handy.
Upon launching the behavioral simulation, you will notice that each valid line of HDL will have a red circle just to the right of the line number. Clicking in one of these red circles will enable a break point on that line.
When the simulation is run and hits that breakpoint, you can then use the Step button in the top tool bar (shown below) or F8 to step through the remaining lines of code.
And finally we see that the new logic design of the FIR filter does in fact behave and function as expected!
Hopefully this demonstrates the significance of how two different ways of writing HDL that ultimately outputs the same result can look very different when implemented on a target FPGA chip and what those consequences can be. This is why it's always important to keep the function of your logic in mind while writing your code.





Comments
Please log in or sign up to comment.