

Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
| ||||||
Hand tools and fabrication machines | ||||||
 |
| |||||
E-Guide - A Helping Hand for the Visually Impaired
Let’s say you are in a familiar environment; it can be your home, your office or any other place that will include the things you use daily – your phone, keys, or a cup of coffee, for example. Now, let me bring you to the next level and ask you to locate these items with your eyes closed. I try to make the first move, yet all semblance of game playing appears more forced and random and one starts to get annoyed. This is a challenge that millions of visually impaired people have to go through every day of their lives. Welcome to E-Guide a personal assistant to finally give the Visually impaired community an easy and independent live. By using E-Guide, you have your assistant who will describe to you the environment, and lead you to the objects you need.
Build2gether 2.0 ChallengeThat is the idea behind the Build2gether 2.0 Inclusive Innovation Challenge, which focuses strictly on successful innovations and cooperation. It is a special challenge where innovators from across the globe converge with an aim of addressing some of the challenges faced in society through use of technology. Let me compare it to a game where not only do people create projects, but create solutions that positively impact people’s lives.
As inspired by Build2gether, rather than only considering the possibility of my solution’s implementation, I tried to turn the spotlight towards the people who would be using it. It’s something that made me develop something that solves a real need or addresses a real issue, and that’s making a firm step in the right direction to creating a world in which people can move through life without fear or trepidation.
Problem IdentificationThe problem I’m addressing with E-Guide is one that affects millions of people worldwide: The anticipated feeling of the daily fight of living in the midst of blindness. Each of the above mentioned symptoms can be mentally and physically tiring for the visually impaired; for example, it can take ages for the visually impaired to look for an object that has been misplaced or even to move from one section of a room to another. Some of the conventional assistive devices used by the disabled include those for walking or moving around such as canes and guide dogs, they do not guide one in finding an object or give details of the environment. This has the effect of making them feel as though they are completely dependent on others because they cannot access such things as accessibility incorporates an impaired person’s capability to function on his or her own. I realized this as a big challenge that required a solution and thus embarked on coming up with such a solution. The idea which led to the creation of EchoGuide is based on the need to provide visually impaired individuals with the means to become more engaged with the surrounding world. EchoGuide integrates voice recognition, object detection, and audio feedback that brings a break through to the disability that blindness is; turning the inconvenience of not seeing into gain of knowing that preserves independence.
Developing a SolutionSolution Overview: E-Guide is a wearable cap that just like a normal cap has the factor of safety, fashionable color and also being enriched with the features of technology for helping the visually impaired in their daily activities. On the head part, only the camera should be seen while wires are neatly sewn throughout the fabric of the cap. The aim was to develop a device that will not make the impression that the user is impaired in any way and can be used in any environment.
Technical Approach: The main technology used in E-Guide is a machine learning technology that is coupled with deep learning approaches and this work in analyzing the visual data from a webcam placed on the cap. This makes it possible for the system to detect objects in real-time as well as in different environments.
User Interface and Experience: The given system has the ability to speak out along with it passes all the recognized objects and their locations. The focus is made on the case that the interface layer is friendly and adjustable to individual users depending on their requirements. It is possible to adjust the device for various types of the loss of vision, thus it is possible to cover different levels of disability.
How It WorksE-Guide works through the camera located at the cap that captures images of the surroundings. These images are analyzed using the machine learning algorithms to recognize objects in the pictures. The system finally conveys audio feedback to the user through the headphone, to explain what objects has been recognized, and where they are found.
Additionally, it gives the direction of the identified object is described in relation to the clock-face method and distance is indicated in beeps with the frequency increasing as one gets closer to the object.The user has the possibility to set the level of feedback’s informativeness and choose between basic and detailed l evels. If the given option was basic, then the feedback will be without any color detection and if the given option was detail then the feedback will be of the colors of the object.
Build InstructionsBelow are instructions on how to prototype, assemble, and deploy the E-Guide Cap. These instructions assume you are familiar with the Raspberry Pi 4 Model B and working with Python and Machine Learning.
Complete project code and 3D files are found within this project's attachments and on Github.
E-Guide HardwareBuilding the E-Guide device, need the following components:
Raspberry pi 4 model B
Camera: you can use NoIR or normal pi camera or webcam
power supply or power bank
Headphones
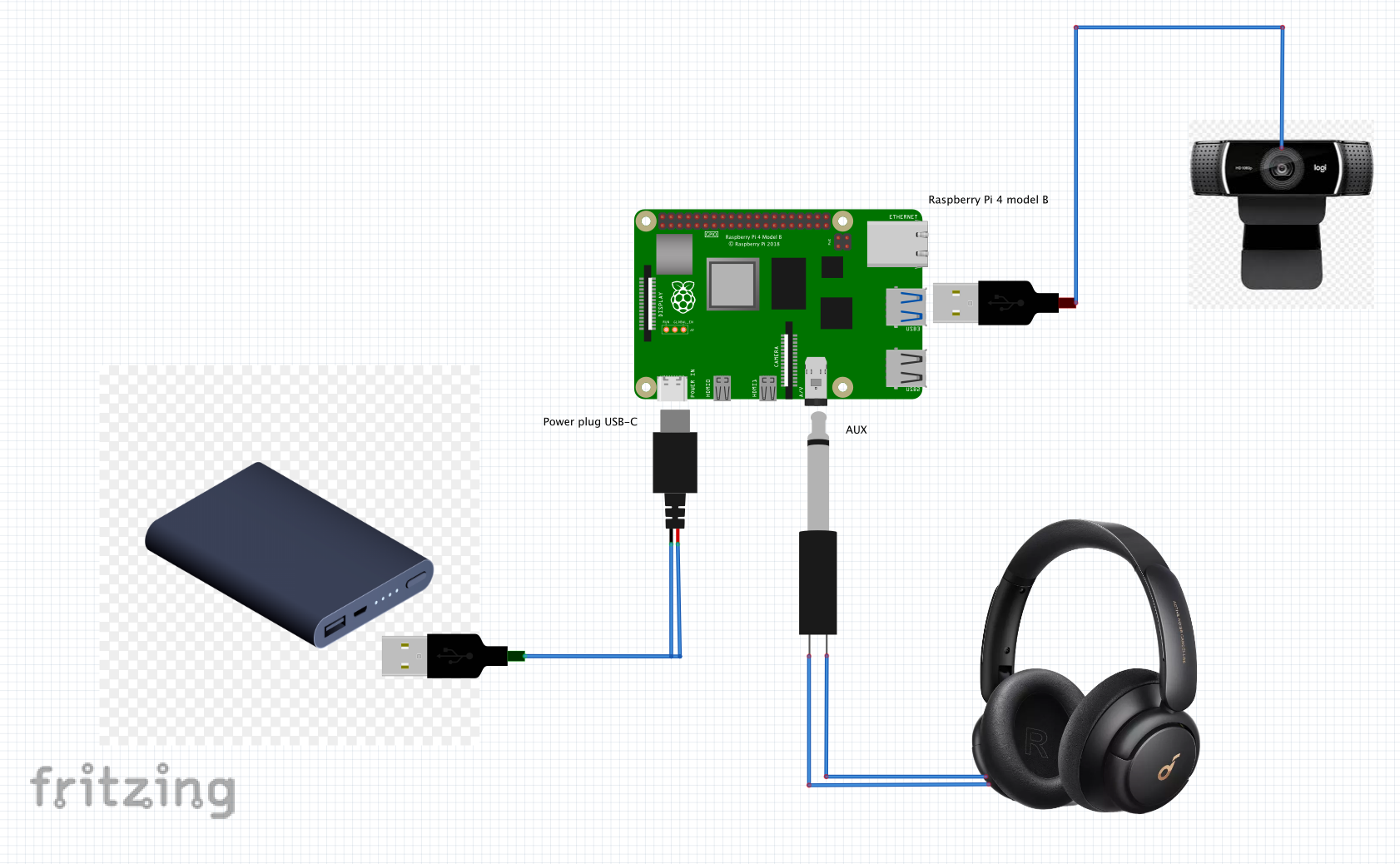
The setup of the E-Guide mainly comprises a circuit of Raspberry Pi 4 along with a WebCam and Headphone for interaction with the users. Here is a circuit diagram showing the connections as described above.
For the audio output to work in the E-Guide, there is need to include sound files in (.wav) format, together with a Python script.
Download and unzip the project beeps sound bundle from the following link on GitHub: Beeps_sound.zip.
Unzip the downloaded COCO datasets. I chose this version coco_ssd_mobilenet_v1_1.0_quant_2018_06_29, For the record, I uploaded it to my GitHub; you can download the unzip of it when you want.
Let's go through the project code step by step, explaining the implementation process in detail:
Step 1: Importing Necessary Packages
import os
import argparse
import cv2
import numpy as np
import sys
import time
from threading import Thread
import importlib.util
import pyttsx3
import speech_recognition as sr
import pygame
from pygame import mixer
import webcolors
from scipy.spatial import KDTreeI started by importing all the necessary Python packages. These include essential libraries like os, sys, and time for handling file paths, system operations, and time management, respectively. I used argparse for parsing command-line arguments, cv2 (OpenCV) for video processing, and numpy for numerical operations. I also imported threading to handle parallel tasks and importlib.util for dynamic module loading.
Additionally, pyttsx3 and speech_recognition were imported for text-to-speech and voice recognition functionalities. Finally, I used pygame for playing audio feedback, webcolors for color name detection, and KDTree from scipy.spatial for efficiently finding the closest color name.
Step 2: Setting Up the Color Recognition Function
def get_color_name(rgb_tuple):
css3_db = webcolors.CSS3_HEX_TO_NAMES
names = []
rgb_values = []
for color_hex, color_name in css3_db.items():
names.append(color_name)
rgb_values.append(webcolors.hex_to_rgb(color_hex))
kdt_db = KDTree(rgb_values)
distance, index = kdt_db.query(rgb_tuple)
return names[index]
def get_color_name(rgb_tuple):
css3_db = webcolors.CSS3_HEX_TO_NAMES
names = []
rgb_values = []
for color_hex, color_name in css3_db.items():
names.append(color_name)
rgb_values.append(webcolors.hex_to_rgb(color_hex))
kdt_db = KDTree(rgb_values)
distance, index = kdt_db.query(rgb_tuple)
return names[index]Next, I created a function called get_color_name that uses the KDTree algorithm to find the closest color name corresponding to an RGB value. I accessed a dictionary of CSS3 color names and their hexadecimal values from the webcolors library.
I then converted these hexadecimal values to RGB and stored them in a list. Using KDTree, I constructed a tree for fast nearest-neighbor lookup and returned the name of the closest matching color.
Step 3: Setting Up Text-to-Speech (TTS)
def mySpeak(message):
engine = pyttsx3.init()
engine.setProperty('rate', 150)
engine.say('{}'.format(message))
engine.runAndWait()I implemented a mySpeak function that uses the pyttsx3 library to convert text to speech. I initialized the TTS engine, set the speaking rate to 150 words per minute for clarity, and instructed the engine to speak the given message. This function was used throughout the project to provide audio feedback to the user.
Step 4: Defining Beep Files for Audio Feedback
BEEP_FAST = "/home/pi/Desktop/beeps_fast.wav"
BEEP_MEDIUM = "/home/pi/Desktop//beeps_medium.wav"
BEEP_SLOW = "/home/pi/Desktop/beeps_slow.wav"I defined file paths for three different beep sounds (BEEP_FAST, BEEP_MEDIUM, and BEEP_SLOW) that were used later in the code to indicate the distance of the detected object. These beeps provided auditory cues to the user, corresponding to near, medium, or far distances.
Step 5: Creating a Function for Voice-Activated Object Detection
def detect_object_by_voice():
recognizer = sr.Recognizer()
microphone = sr.Microphone()
with microphone as source:
print("Listening...")
mySpeak("Please say the object you want to detect")
recognizer.adjust_for_ambient_noise(source)
audio = recognizer.listen(source)
try:
object_name = recognizer.recognize_google(audio)
print(f"You said: {object_name}")
mySpeak(f"Searching for {object_name}")
return object_name.lower() # Convert to lowercase for consistency
except sr.UnknownValueError:
print("Could not understand audio")
mySpeak("Sorry, I could not understand. Please try again.")
return None
except sr.RequestError as e:
print(f"Could not request results; {e}")
mySpeak("Sorry, I'm having trouble processing your request.")
return NoneI developed the detect_object_by_voice function, which prompts the user to say the name of the object they want to detect. Using the speech_recognition library, the function listens to the user's voice, recognizes the spoken words using Google's speech recognition API, and returns the object name in lowercase. If the system fails to understand the user, it provides appropriate feedback and prompts them to try again.
Step 6: Implementing Functions for Direction and Distance Estimation
def get_direction(x, width):
if x < width / 12:
return "1 o'clock"
# (similar checks for other directions)
else:
return "12 o'clock"
def get_distance(y, height):
if y < height / 3:
return "near"
elif y > 2 * height / 3:
return "far"
else:
return "medium"I created two helper functions, get_direction and get_distance, to determine the object's position in the frame. The get_direction function divided the frame horizontally into 12 regions (like the face of a clock) and returned the corresponding direction based on the object's x-coordinate. The get_distance function divided the frame vertically into three regions and returned "near, " "medium, " or "far" based on the object's y-coordinate.
Step 7: Setting Up Voice-Activated Verbosity Level Selection
def get_verbosity_level():
recognizer = sr.Recognizer()
microphone = sr.Microphone()
with microphone as source:
print("Listening for verbosity level...")
mySpeak("Please say the verbosity level. Options are: basic or detailed.")
recognizer.adjust_for_ambient_noise(source)
aud2 = recognizer.listen(source)
try:
verbosity = recognizer.recognize_google(aud2)
print(f"You said: {verbosity}")
mySpeak(f"You said {verbosity}")
if verbosity.lower() in ["basic", "detailed", "detail", "details"]:
return verbosity.lower()
else:
mySpeak("Invalid option. Please say either basic or detailed.")
return get_verbosity_level()
except sr.UnknownValueError:
print("Could not understand audio")
mySpeak("Sorry, I could not understand the audio.")
return get_verbosity_level()
except sr.RequestError as e:
print(f"Could not request results; {e}")
mySpeak(f"Sorry, I could not request results; {e}")
return get_verbosity_level()I created the get_verbosity_level function, which prompts the user to select between "basic" and "detailed" verbosity levels. The function uses speech recognition to capture the user's preference and repeats the process if it doesn't understand the user's response. The selected verbosity level determines the amount of information provided during object detection (e.g., with or without color details).
Step 8: Creating the VideoStream Class
class VideoStream:
def __init__(self, resolution=(640, 480), framerate=30):
self.stream = cv2.VideoCapture(0)
ret = self.stream.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter_fourcc(*'YUYV'))
ret = self.stream.set(3, resolution[0])
ret = self.stream.set(4, resolution[1])
(self.grabbed, self.frame) = self.stream.read()
self.stopped = False
def start(self):
Thread(target=self.update, args=()).start()
return self
def update(self):
while True:
if self.stopped:
self.stream.release()
return
(self.grabbed, self.frame) = self.stream.read()
def read(self):
return self.frame
def stop(self):
self.stopped = TrueI designed a VideoStream class to handle video streaming from the camera. This class allows the camera feed to be read in a separate thread, ensuring that the video stream remains smooth and responsive. The start method initiates the thread, while the read method returns the current frame. The stop method stops the video stream.
Step 9: Initializing Pygame for Audio Feedback
pygame.mixer.init()I initialized pygame.mixer to handle audio feedback for object detection. This initialization allows the program to play sound files like beeps during execution.
Step 10: Parsing Command-Line Arguments
parser = argparse.ArgumentParser()
parser.add_argument('--modeldir', help='Folder the .tflite file is located in', required=True)
parser.add_argument('--graph', help='Name of the .tflite file, if different than detect.tflite', default='detect.tflite')
parser.add_argument('--labels', help='Name of the labelmap file, if different than labelmap.txt', default='labelmap.txt')
parser.add_argument('--threshold', help='Minimum confidence threshold for displaying detected objects', default=0.5)
parser.add_argument('--resolution', help='Desired webcam resolution in WxH. If the webcam does not support the resolution entered, errors may occur.', default='1280x720')
parser.add_argument('--edgetpu', help='Use Coral Edge TPU Accelerator to speed up detection', action='store_true')
args = parser.parse_args()I used argparse to create a command-line interface for the project, allowing users to specify parameters like the model directory, TensorFlow Lite model file, label map file, confidence threshold, and webcam resolution. This flexible setup makes it easy to configure the project for different environments and hardware.
Step 11: Loading the TensorFlow Lite Model and Labels
MODEL_NAME = args.modeldir
GRAPH_NAME = args.graph
LABELMAP_NAME = args.labels
min_conf_threshold = float(args.threshold)
resW, resH = args.resolution.split('x')
imW, imH = int(resW), int(resH)
use_TPU = args.edgetpu
# Load the label map
with open(PATH_TO_LABELS, 'r') as f:
labels = [line.strip() for line in f.readlines()]
if labels[0] == '???':
del (labels[0])
interpreter = Interpreter(model_path=PATH_TO_CKPT)
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
height = input_details[0]['shape'][1]
width = input_details[0]['shape'][2]
floating_model = (input_details[0]['dtype'] == np.float32)
input_mean = 127.5
input_std = 127.5
outname = output_details[0]['name']
if 'StatefulPartitionedCall' in outname:
boxes_idx, classes_idx, scores_idx = 1, 3, 0
else:
boxes_idx, classes_idx, scores_idx = 0, 1, 2I loaded the TensorFlow Lite model and label map specified by the user. The label map contains the class names for object detection, while the TensorFlow Lite interpreter processes the input and output tensors. This setup is essential for performing object detection and classification using the specified model.
Step 12: Starting the Video Stream and Processing Frames
videostream = VideoStream(resolution=(imW, imH), framerate=30).start()
time.sleep(1)
while True:
frame1 = videostream.read()
frame = frame1.copy()
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame_resized = cv2.resize(frame_rgb, (width, height))
input_data = np.expand_dims(frame_resized, axis=0)
if floating_model:
input_data = (np.float32(input_data) - input_mean) / input_std
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
boxes = interpreter.get_tensor(output_details[boxes_idx]['index'])[0]
classes = interpreter.get_tensor(output_details[classes_idx]['index'])[0]
scores = interpreter.get_tensor(output_details[scores_idx]['index'])[0]
for i in range(len(scores)):
if (scores[i] > min_conf_threshold) and (scores[i] <= 1.0):
ymin = int(max(1, (boxes[i][0] * imH)))
xmin = int(max(1, (boxes[i][1] * imW)))
ymax = int(min(imH, (boxes[i][2] * imH)))
xmax = int(min(imW, (boxes[i][3] * imW)))
object_name = labels[int(classes[i])]
object_color = get_color_name(frame[ymin:ymax, xmin:xmax].mean(axis=0).mean(axis=0))
cx = int((xmin + xmax) / 2)
cy = int((ymin + ymax) / 2)
direction = get_direction(cx, imW)
distance = get_distance(cy, imH)I started the live video feed and begun on the processing of frames on a real time basis. Each frame was then reduced from 4 D to 3 D, that is converted to RGB, resized to the expected input size by the model and then again converted to a 4-D tensor.
TensorFlow Lite interpreter was then used to perform object detection and this would give the interpreter bounding boxes, class indices and confidence scores. Specifically, for each of the detected object whose confidence score is above the threshold, its bounding box coordinates, color, estimated direction and distance were calculated.
Step 13: Providing Audio Feedback
if object_name == target_object:
if verbosity == "detailed":
mySpeak(f"{object_name} at {direction}, {distance}, color {object_color}")
else:
mySpeak(f"{object_name} at {direction}, {distance}")
if distance == "near":
mixer.music.load(BEEP_FAST)
elif distance == "medium":
mixer.music.load(BEEP_MEDIUM)
else:
mixer.music.load(BEEP_SLOW)
mixer.music.play()
cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), (10, 255, 0), 2)
cv2.putText(frame, object_name, (xmin + 10, ymin + 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2, cv2.LINE_AA)
cv2.putText(frame, f"Color: {object_color}", (xmin + 10, ymin + 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2, cv2.LINE_AA)
cv2.imshow('Object detector', frame)
if cv2.waitKey(1) == ord('q'):
break
cv2.destroyAllWindows()
videostream.stop()To end the loop, I used an ‘if’ statement to compare the detected object to the target object that the user has inputted. Depending on the selected level of verbosity, the system reported in detail or just the basics about the position of the object, the direction it was moving in and color.
Depending on the distance of the object a beep sound which corresponded to the object was played. I also translated the bounding box, name of the object and the color right on the video stream for the confirmation purpose. This loop stopped when the user pressed ‘q’ key which closed the window and halted the stream of the video.
Prototype TestingAs part of the evaluation procedure, E-Guide was tested in a number of settings to provide an understanding of its efficiency. Testing involved:
- Indoor Environments: Here, the testing was done in a normal set-up which was a typical house, and the objects used were easily found in any home.
- Low-Light Conditions: Even further, night vision camera for identification of objects and targets in the night environment.
- Multiple Object Detection: Evaluating the system’s capacity on recognizing particular objects particularly when there are other objects around them.
To use the E-Guide:
- Wear the Cap: Wear the cap in such a way that the camera is focused on what you see.
- Power On: Power on Raspberry Pi to start the system and let it boot up completely.
- Voice Command: To play a specific object speak out its name with fluency.
- Receive Feedback: For direction, distance and color information listen to the audio feedback.
- Repeat: If the object does not appear, do so again or look for another object.
Future enhancements for the E-Guide project include:
- Enhanced Object Recognition: Increasing the number of items in the object database and enhancing the recognition accuracy.
- Integration with Smart Home Devices: Enabling the E-Guide to have some level of integration such that it can communicate with other smart devices.
- Real-Time Navigation Assistance: Extend the functionality towards allowing the users to move from one environment to another with ease.
- Customizable Voice Commands: The possibility to assign one’s own words for controlling the object with voice commands.









{kind=link}
Comments