







Software apps and online services | ||||||
| ||||||
| ||||||
 |
| |||||
| ||||||
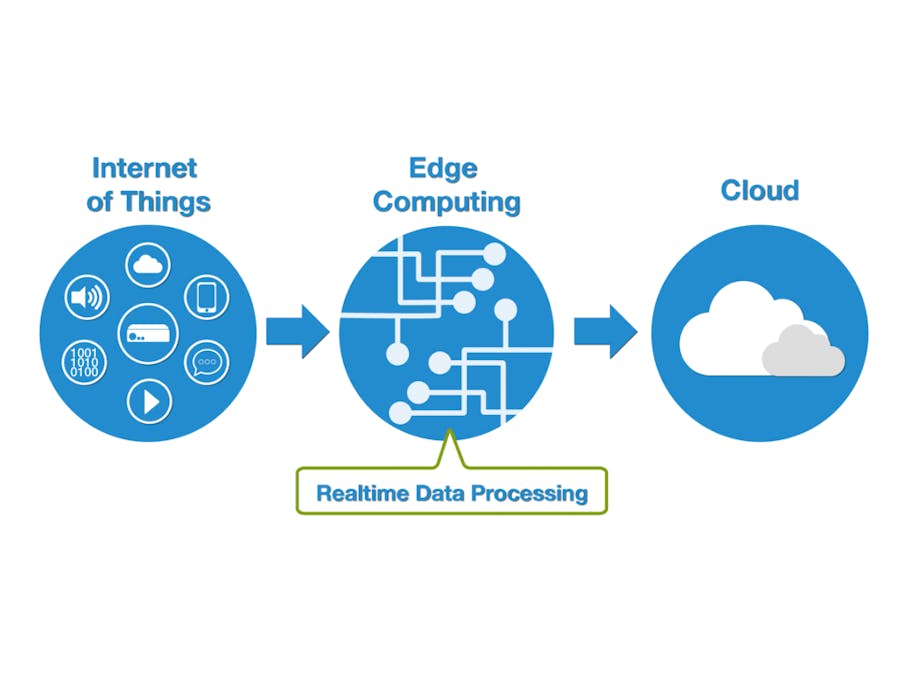
Edge computing refers to any kind of computation, like applications, services, or simpler processing, performed outside of a central unit.
So in particular, in IoT applications, edge computing refers to the part of the computation performed "near" the sensors, allowing calculations before data is even sent to the cloud, which is in most cases the final destination of the information retrieved by IoT sensors.
This approach permits to filter and to perform a first analysis of single values given by the sensor.
Apache EdgentApache Edgent is a programming model useful to implement methods and functions for edge devices such as smartphones, gateways and wearable devices.
Edgent is used to analyze a continuous stream of data coming from, for example, a sensor. It offers a vast library of methods, that permit to retrieve, filter, manage, and send data.
The libraries provided by Apache Edgent are entirely written in Java, in particular using Maven project management, allowing compatibility with lots of devices since the only requisite to use Apache Edgent is the Java Virtual Machine. Edgent support Java 8, and its lambda functions, Java 7 and 6, the last one assures compatibility of Android devices.
Apache Edgent is a powerful tool that helps you to implement edge computing, but it can be challenging to learn how to use it properly.
In my opinion, the documentation is not accurate, and there are lots of enhancements that can improve it. It can be useful to add more complete examples and a detailed description of the particular classes provided by Edgent library.
Cloud ComputingCloud represents a specific network architecture in which several servers are connected to form a cluster. The services offered by the cloud permits to solve computationally expensive tasks. Indeed, the cloud is accessible via an internet connection at every moment.
Due to the high storage and the computational capabilities, it offers an optimal choice for tasks that require to save large quantities of data and to make some complex operations on them.
ElasticSearchElasticSearch is a distributed and RESTful search engine based on Lucene, a Java library. For that reason, it is multi-platform.
It provides a full-text search with an HTTP web interface. ElasticSearch saves data as JSON documents. Documents contain not structured data, so this means that every type of data can be processed and searched with Elastic. One of the main usages of ElasticSearch is the one that exploits it as a non-SQL database.
It is very appreciated because of its speed in searching for data. Indeed, thanks to an accurate internal ordering of the data, it can find the requested documents almost instantly.
Other applications, such as Kibana, Logstash, or Beats, are often flanked with Elastic.
Edge versus CloudAfter this brief introduction of edge and cloud computing with two examples of tool/service, we can enter in the core of this post.
These two methods have lots of discrepancies, but that doesn't mean that they are incompatible. In one hand, edge computing has limited memory and computational power, while, cloud computing has a large memory and computational power. On the other hand, edge computing grants a faster response time because the computation is near the final user or the sensors.
So we can distinguish the goal of these two types of computation.
- The edge is useful to examine a little amount of data, in some cases also a single value, that permits to handle critical situations, where fast response time is needed, to filter useless data when we want to store them, to display in some fancy way this data for our final user.
- The cloud permits a more complex, complete, and computational expensive examination of data. Due to the vast amount of data that a cloud service can store, we can perform, for example, a machine learning algorithm or a long term analysis like the one that Kibana does.
In our opinion, edge and cloud computing are complementary, they can, and they need, to live together to achieve the best results.
We should use both of them in every IoT application when possible, but is using edge computing also cost-effective?
We have had an extensive discussion on this point given from our different points of view.
Some of us think that using edge computing can decrease the cost of an IoT application, for the simple reason that if we send less data, filtering them, to the cloud service, we need fewer storage capabilities, cutting costs on the subscription to the cloud platform.
On the other hand, some of us think that in big IoT application the cost of the edge devices, both in hardware price and software maintainability, can cancel the savings given by the fewer storage capabilities needed.
We didn't reach a final agreement, so let us know your idea in the comments below.
High-level visualizationHigh-level visualization aims to display data for the final users of an IoT application. This approach is useful for the user to have immediate feedback, and to visualize the data of his interest.
A good example of high-level visualization is Mango Mirror, a personal dashboard that provides you with the information you need, when and where you need it, allowing you to take control of your body, life, and day ahead of time. It permits to transform an Android tablet or a Raspberry Pi (with a screen) into a Smart display that presents your data, for example, given by a smartwatch.
KibanaKibana is a powerful tool for visualazing data from Elasticsearch. There are a lot of capabilities from navigate in data and extract every type of information. It's also possibile using a query language to find everything and assemble the searches.
It combines the power of search (and the fantastic Elastic backend to storage them) with a tons of data visualizations tools from histograms, line graphs, pie charts and a lot of others. Time series is also another possibility.In the last years, with the rise of artificial intelligence, there has been the implementation of machine learning tools that have amplified Kibana and Elastic in an incredibile data mining and discovery for a large number of scopes.
High-level visualization versus Kibana
Once you have data, you need to visualize it. There are lots of applications and services that offer you tons of way to present your data. However, we need to choose specific services for different types of users.
High-level visualization is useful for users with no particular abilities and is often used in smart home to display necessary data. It is entirely customizable so, users can choose what to see.
Although if our users are, for example, data analysts, we need a more sophisticated tool that permits to run some calculation on the data we stored.
Who needs a more precise tool to discovery and navigate into data have to use Kibana.Kibana has a lot of power to visualize data with every type of graph.It's a professional tool for data scientists.Software like Kibana are perfect for this type of operations.On the other side, Kibana is a not a simple tool for the common user and has a high learning curve to understand how to use it. It has a some sort of possibility of personalization, but who use kibana needs a scientific enviroment and nothing else.
High-level visualization and Kibana are two completely different types of display data, and they are both useful to achieve their specific goal.









Comments
Please log in or sign up to comment.