





Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 2 | ||||
| × | 1 | ||||
| × | 1 | ||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
| ||||||
Hand tools and fabrication machines | ||||||
 |
| |||||
 |
| |||||
 |
| |||||
Elephants are mammals of the family Elephantidae and they are the largest existing land animals. They are also keystone species, playing an important role in maintaining the biodiversity of the ecosystems in which they live.
The elephants use their tusks to dig for water. This not only allows the elephants to survive in dry environments and when droughts strike, but also provides water for other animals that share harsh habitats. When forest elephants eat, they create gaps in the vegetation. These gaps allow new plants to grow and create pathways for other smaller animals to use. They are also one of the major ways in which trees disperse their seeds; some species rely entirely upon elephants for seed dispersal. On the savannahs, elephants feeding on tree sprouts and shrubs help to keep the plains open and able to support the plains game that inhabits these ecosystems. Wherever they live, elephants leave dung that is full of seeds from the many plants they eat. When this dung is deposited the seeds are sown and grow into new grasses, bushes, and trees, boosting the health of the savannah ecosystem.
But threats to the giant of the forest are numerous. According to the WWF, African elephant populations have fallen from an estimated 12 million a century ago to some 400, 000. In recent years, at least 20, 000 elephants have been killed in Africa each year for their tusks. African forest elephants have been the worst hit. Their populations declined by 62% between 2002-2011 and they have lost 30% of their geographical range, with African savanna elephants declining by 30% between 2007-2014. This dramatic decline has continued and even accelerated with cumulative losses of up to 90% in some landscapes between 2011 and 2015. Today, the greatest threat to African elephants is wildlife crime, primarily poaching for the illegal ivory trade, while the greatest threat to Asian elephants is habitat loss, which results in human-elephant conflict.
To avoid confrontations and protect their crops, people in Asia have traditionally used several tricks to scare off elephants, like beating drums, firing gunshots into the air, or bursting firecrackers. They also produce high sounds to scare elephants(like yelling, screaming). All these methods can lead both elephants and humans to danger. Trophy hunting is another major threat to this giant.
For saving these largest mammals, we are creating a collar that is completely based on Artificial Intelligence(AI) and the Internet of Things(IoT) which can almost solve the existing threats of elephants. Meet our newly designed open-source collar, Elefante.
VideoFeatures
- Live tracking of elephants
- Geofenceto determine the natural habitat of elephants
- Predictschances of ivory poaching and trophy hunting
- Detects human conflict
- Instant notifications to forest rangers if any threats are found
- Alerts when elephants enter rural areas
- Rechargeable
- Low cost
- Completely Open-source
Edge Impulse is the leading development platform for machine learning on edge devices, free for developers, and trusted by enterprises. Here we are using machine learning to build a system that can recognize when a particular sound is happening.
In Ivory poaching and trophy hunting, the poachers use high-caliber rifles to get the job done. So any sort of rifle attack on elephants can be spotted by classifying this rifle sound. Also, this machine learning model will detect ordinary gun sounds too. When we consider the case of human-elephant conflict, there are a lot of sounds to identify. Whether it can be a sound from the humans themselves (like yelling) or any other disturbances created by humans like firecrackers, beating drums, etc. By means of this model, we can only classify sound. So we focus on the sound produced during the conflict. Our machine learning model can classify all of these sounds can detect whether there are chances of ivory poaching, trophy hunting, and human-elephant conflict.
For creating the model you need to sign up for the Edge Impulse. Then create a new project by tapping on the '+' icon on the dashboard.
For generating the model we need a lot of datum. The more data you have the more accurate your model will be. Since the goal is to detect the sound of rifles, firecrackers, humans any other sound created during conflicts. We will also need some background noises of the forest to discriminate between these sounds. Any other sounds apart from this will be considered as noises. Most of the forest noises were recorded by our microphone " Rode Video Micro ". To get the perfect background sound of the forest we have used fur along with the mic. Also recorded without fur, to get the mixed sound of wind and background sound.
We also downloaded some forest background sounds from native websites. We have collected around twenty audio samples of forest background noises. Then we have collected the sounds of different rifles. For each rifle, the sound is taken in Different Contexts, which means the sound of a rifle from far and close will be slightly different. The close and far shot of the same rifle is collected to improve the accuracy of the model. Then we collected different human sounds produced during a conflict like yelling, screaming, groaning, etc. We also collected the sounds of firecrackers, drum beats, etc to identify the human-elephant conflict.
So our data collection is over. Then we need to upload it to the Edge Impulse studio. For uploading the data just moves on to the Data acquisition tab and just choose a file. Then label it and upload it to the training section.
The Edge Impulse will only accept a .wav sound file. If you have any other format, just convert it to.wav format with the online converters.
So we uploaded all the data with the four different labels such as Firecrackers, Noise, Human, and Gunfire. We have maintained the same frequency for all audio files(44100 Hz). Try to maintain the same frequency for all files.
You can also collect the data from the specified device by the Edge Impulse studio. When the data has been uploaded, you will see a new line appear under 'Collected data'. You will also see the waveform of the audio in the 'RAW DATA' box. You can use the controls underneath to listen to the audio that was captured.
With the training set in place, we will need to design an Impulse. An impulse takes the raw data, slices it up in smaller windows, uses signal processing blocks to extract features, and then uses a learning block to classify new data. Signal processing blocks always return the same values for the same input and are used to make raw data easier to process, while learning blocks learn from past experiences.
For this project, we'll use the "MFCC" signal processing block. MFCC stands for Mel Frequency Cepstral Coefficient. Basically just a way of turning raw audio which contains a large amount of redundant information into a simplified form. We'll then pass this simplified audio data into a Neural Network block, which will learn to distinguish between the classes.
For creating the Impulse, go to the Create impulse tab. You'll see a Raw data block, like this one.
Edge Impulse slices up the raw samples into windows that are fed into the machine learning model during training. The Window size field controls how long, in milliseconds, each window of data should be. Window increase field controls the offset of each subsequent window from the first. By setting a Window increase that is smaller than the Window size, we can create windows that overlap. Window size and Window increase should be adjusted according to the context.
Next, click Add a processing block and choose the 'MFCC' block. Once you're done with that, click Add a learning block and select 'Neural Network (Keras)'. Finally, click Save impulse. Then impulse will be like this.
Then move on to the MFCC tab.
This page allows you to configure the MFCC block and lets you preview how the data will be transformed. The right of the page shows a visualization of the MFCC's output for a piece of audio, which is known as a spectrogram.
The MFCC block transforms a window of audio into a table of data where each row represents a range of frequencies and each column represents a span of time. The value contained within each cell reflects the amplitude of its associated range of frequencies during that span of time. The spectrogram shows each cell as a colored block, the intensity which varies depends on the amplitude.
You can configure the MFCC block by changing the parameter in the parameters box. Edge Impulse provides sensible defaults that will work well for many use cases, so we can leave these values unchanged.
The spectrograms generated by the MFCC block will be passed into a neural network architecture that is particularly good at learning to recognize patterns in this type of tabular data. Before training our neural network, we'll need to generate MFCC blocks for all of our windows of audio. To do this, click the Generate features button at the top of the page, then click the green Generate features button. Once this process is complete the feature explorer shows a visualization of your dataset. Here dimensionality reduction is used to map your features onto a 3D space, and you can use the feature explorer to see if the different classes separate well, or find mislabeled data (if it shows in a different cluster). This is our generated features.
With all data processed it's time to start training a neural network. Neural networks are algorithms, modeled loosely after the human brain, that can learn to recognize patterns that appear in their training data. The network that we're training here will take the MFCC as an input, and try to map this to one of four classes.
Click on NN Classifier in the left-hand menu. You will see a page like this.
A neural network is composed of layers of virtual "neurons", which you can see represented on the left-hand side of the NN Classifier page. An input—in our case, an MFCC spectrogram—is fed into the first layer of neurons, which filters and transforms it based on each neuron's unique internal state. The first layer's output is then fed into the second layer, and so on, gradually transforming the original input into something radically different. A particular arrangement of layers is referred to as an architecture, and different architectures are useful for different tasks. This is our Neural Network architecture.
This is our training settings.
We set the training cycles to 400. This means the full set of data will be run through the neural network 400 times during training. If too few cycles are run, the network won't have learned everything it can from the training data. However, if too many cycles are run, the network may start to memorize the training data and will no longer perform well on data it has not seen before. This is called overfitting. Next, we set the Minimum confidence rating to 0.75. To begin training, click Start training.
This will take some time. For my data sets, it took around 20 minutes. After training, we can test our model by uploading sample audio. But it's extremely important that we test the model on new, unseen data before deploying it in the real world. This will help us ensure the model has not learned to overfit the training data, which is a common occurrence. Move on to the Data acquisition tab and upload some audio into the testing category. Then move onto the Live classification tab and classify the sound.
Here we uploaded some audio of Gunfire and let's see the result.
So our model is almost accurate. Our neural network model is capable of recognizing particular sounds from the classes.Then we can deploy in a device.
Raspberry Pi 4BThe Raspberry Pi 4B is the powerful development of the extremely successful credit card-sized computer system. The brain of our collar is Raspberry Pi. All major process of the collar is done on this device. Here we use Wifi connectivity to upload the data. Because we don't have any other options. In a future edition, we will use the Lora module to transfer data from the device. We actually planned to use the Arduino nano 33 BLE sense but it is out of stock on both offline and online stores. In the future edition, we will upgrade the collar with that.
If you don't know how to set up the Pi just go here. Here we used Edge Impulse API and Edge Impulse CLI to upload and classify the data.
For installing the Edge Impulse CLI, we just entered the command
npm install -g edge-impulse-cliMake sure if you have Node.jsv10 or higher for installing CLI. If you have any issues just look here. You can upload files via the Edge Impulse CLI by this command to the testing tab.
edge-impulse-uploader --category testing path/to/a/file.wavThe first time you'll be prompted for a server, and your login credentials.
For taking the audio from the real world on Raspberry Pi we have used a USB sound card because Pi has no audio input. So we need to use a USB mic or USB sound card. So I am only having a sound card with me.
We also need to attach a mic to the sound card. I am using the mic in my headset by just cutting out the speakers. Because we can't use Rode mic due to its large size.
For recording the sound we have used arecord utility. Use this command for recording audio from Pi.
arecord -D sysdefault:CARD=1 -d 5 -f cd -t wav sample.wavHere we are recording a 5s audio file and instantly uploading it to the Edge Impulse studio by CLI. Here the raspberry is connected to wifi. If you need to know more about arecord just have a look here.
To classify the audio, we need the sample id. First of all, we listed the sample id's of the file by means of this python code. Here you need to specify the project_id which you can get from your profile.
import requests
url = "https://studio.edgeimpulse.com/v1/api/projectId/raw-data"
querystring = {"category":"testing"}
headers = {"accept": "application/json"}
response = requests.request("GET", url, headers=headers, params=querystring)
print(response.text)We have uploaded the audio to the testing category. So we need to mention in the code. Then we classified the audio by means of this code.
import requests
url = "https://studio.edgeimpulse.com/v1/api/project_id/classify/sample_id"
headers = {
"cookie": "jwt=xxxxxxxxxxxxxxxxx",
"accept": "application/json",
"x-api-key": "xxxxxxxxxxxxxx" }
response = requests.request("POST", url, headers=headers)
print(response.text)here you need to specify your API-key and jwt, which can be found from your profile. Then we will delete that sample after classification by means of this code for saving space in both raspberry and cloud.
import requests
url = "https://studio.edgeimpulse.com/v1/api/project_id/raw-data/sample_id"
headers = {
"cookie": "jwt=xxxxxxxxxxxxxxxxx",
"accept": "application/json",
"x-api-key": "xxxxxxxxxxxxxx"
}
response = requests.request("DELETE", url, headers=headers)
print(response.text)These pieces of code have almost the effect of the live classification of audio samples. The classification results are stored in the variables and passed into the IoTconnect's dashboard as it's attributes by means of python code.
Configuring IoTConnectThen we connected our raspberry pi to the IoTconnect. First, we need to create a template
Login into IoTConnect and Create a template.
Add the following information to create your template
- Template Code in the string to identify your template
- Template name in string
- Hardware firmware (Optional)
- Description (Optional)
- Authentication Type is Key
Press Save to create it. This is our template.
The attribute we are using is
The latitude and longitude of the location fetched by the GPS module. We will discuss that in the later section.
The next attributes are Gunfire, Firecracker. and Human. These data will be fetched from python code.
Click on the left device and press the create device button for assigning raspberry as the device.
Note: Select a template that you created and enter the Unique ID and display name for the device.
Here we are using the Python SDK for communicating with the IotConnect.
Install Python version 2.7, 3.6, and 3.7 with pip is compatible with the python version
- Download SDK from Download section
- Follow the installation steps available on the SDK page.
- Replace connection informationCPIDDeviceID (Unique ID)Environment
Then get a connection string for the device.
CPID – Get your CPID from the company profile page.
DeviceID (Unique ID) – Get your Device ID from the device list.
When you want to see the telemetry data just click on the unique id.
Then we need to add the rules to give notification if any sort of attack towards the elephant happened. These are the rules I have created. If the attributes mentioned in the rules matched, the notification will be enabled.
Then we created our dashboard by adding the Widgets like Device location, Live Line chart, and Notification. For Device location, we added latitude and longitude as the parameters. For the Live LineChart, we have added the Human, Gunfire, and Firecracker attributes.
The final edition of the dashboard.
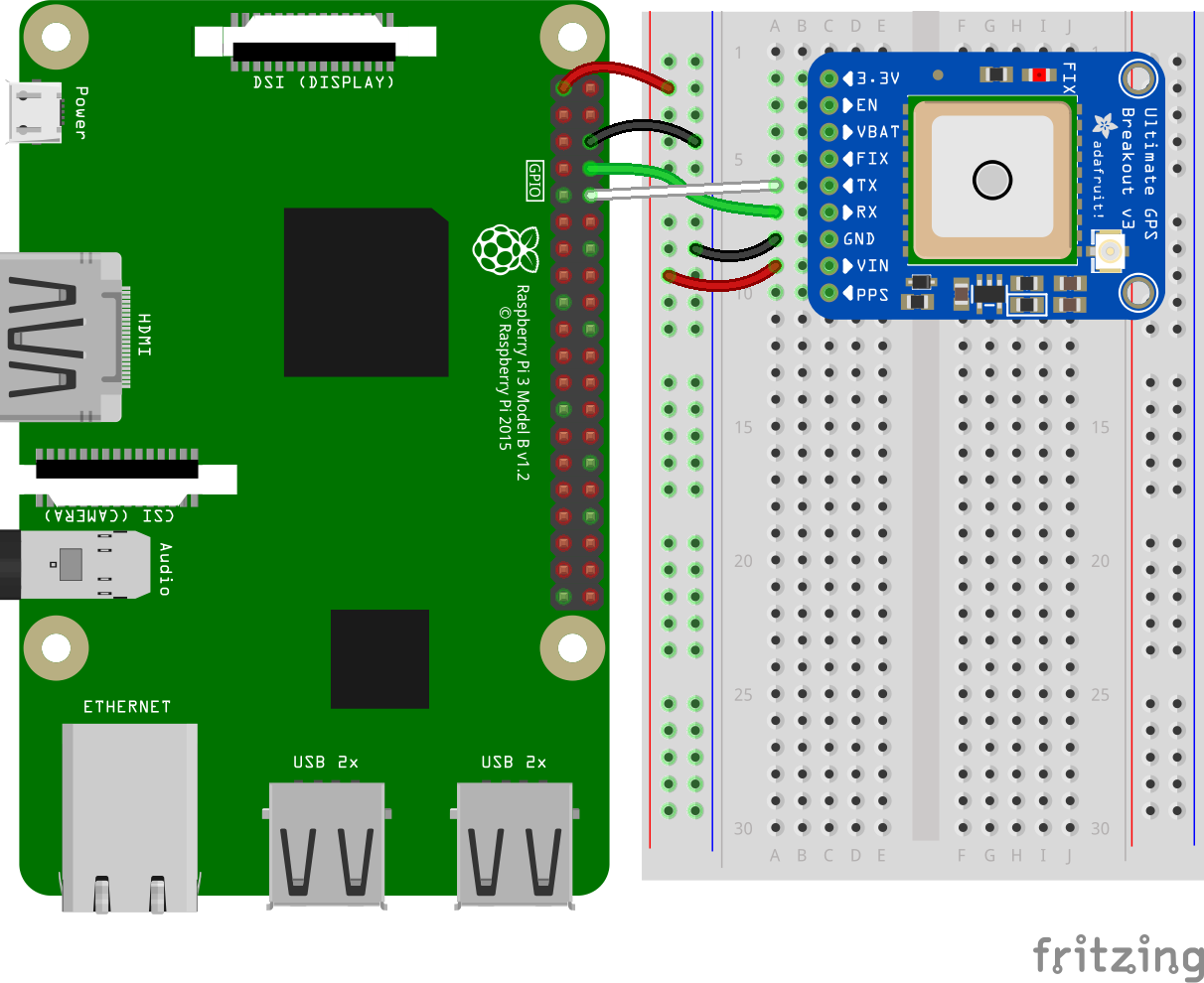
Here we used the Adafruit Ultimate GPS module for fetching the live location of the elephant. Here we interfacing the module with the Pi's built-in UART. You'll need to install the Adafruit_Blinka library that provides the CircuitPython support in Python. This may require verifying you are running Python 3.
Once that's done, from your command line run the following command
sudo pip3 install adafruit-circuitpython-gpsSo the latitude and longitude will be pushed to the IoTConnect. This GPS is somewhat accurate. So anyone who has access to the dashboard can track the elephant.
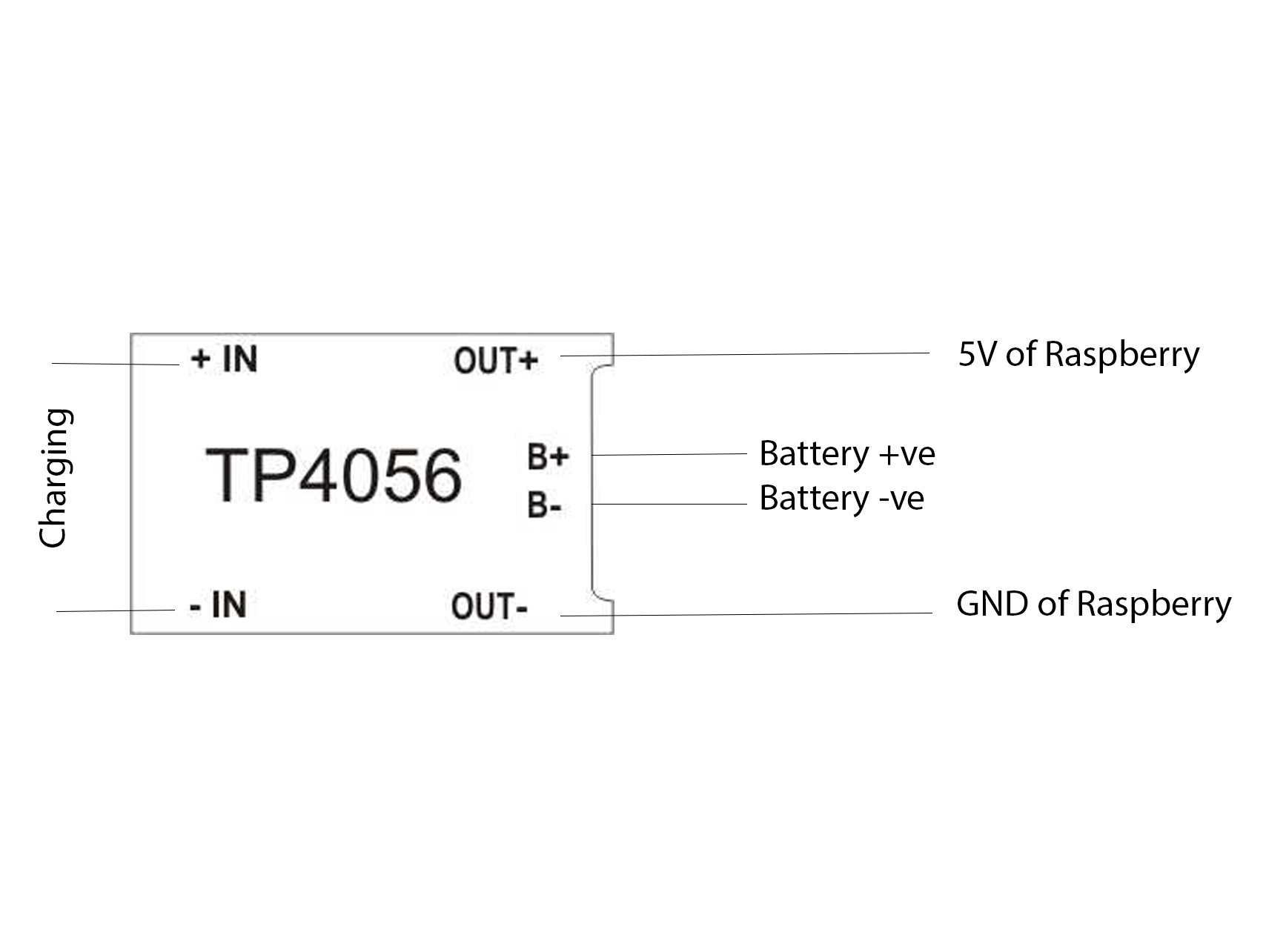
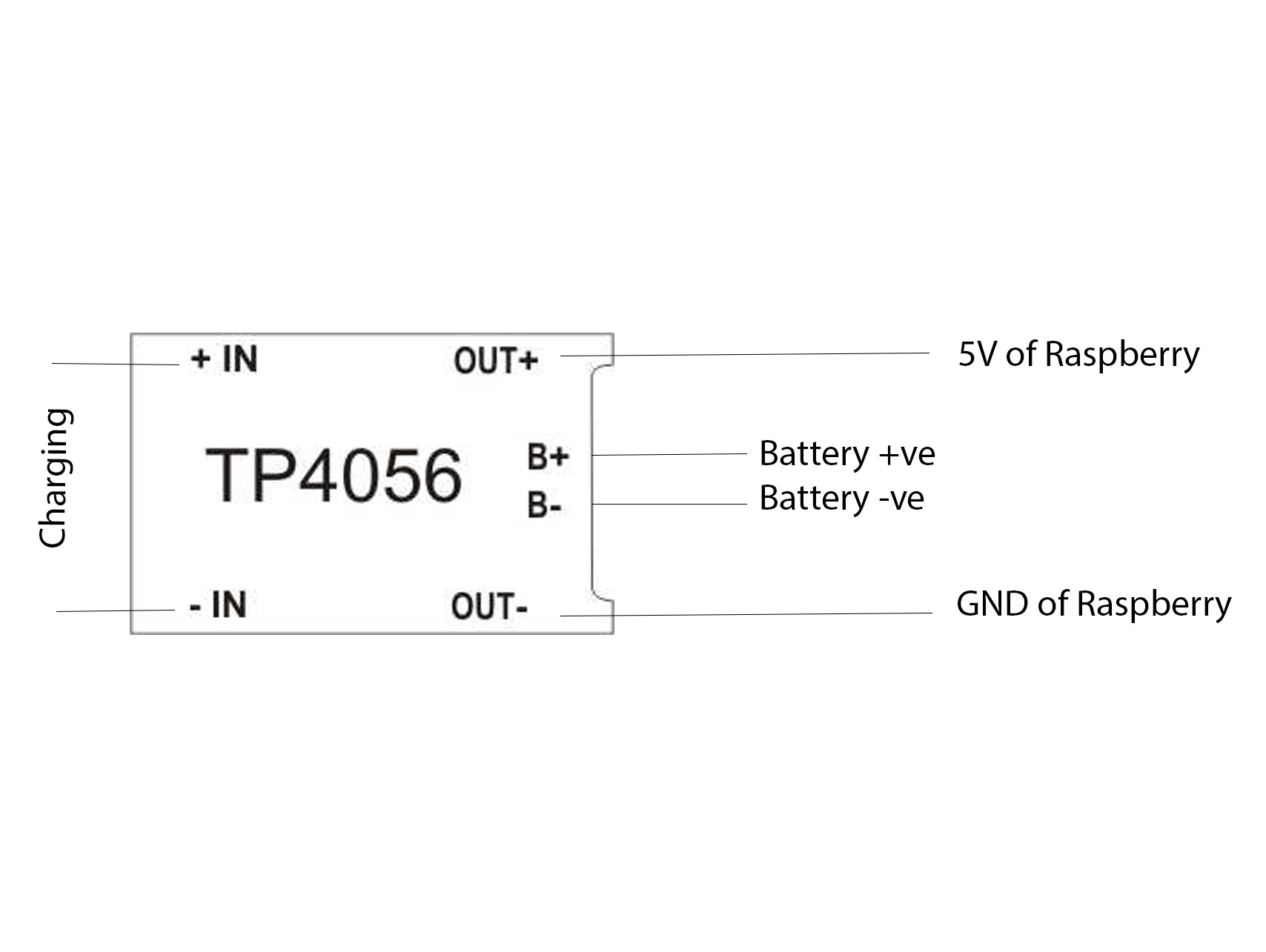
Charging Setup for CollarWe have used two 18650 Li-ion batteries in 2P configuration to charging up the Raspberry pi. For this configuration, it can provide up to 5V and 2.5A. That is enough for running the raspberry pi. This type of powering is not actually recommended.
The batteries are interfaced via the TP4056 Li-ion charger module. So we can easily charge the Collar by means of the micro USB cable.
For placing the components we have used an old plastic case.
Then we can assemble the parts. First of all, we connected the GPS module to the Raspberry pi and then plugged the USB sound card.
Then we soldered the TP4056 charger module to the battery and made connections with TP4056 with the Raspberry.
Let's start placing the components. First, we are placing the battery and the charger module. I just made a hole for TP4056 module for charging.
Then we can attach the remaining components.
We have made some small holes near the mic to grasp the audio clearly. All the components are well placed. Then we can close the collar with a back lid. So our collar is ready to use. The entire code is given in the Github repository.
What in the Future?This is just a beta version of our collar. We want a lot of modifications to bring up the existing collar to the next level.
- In the future, we will replace the Raspberry with the Arduino Nano 33 BLE sense.
The Nano 33 BLE Sense (without headers) is Arduino’s 3.3V AI-enabled board in the smallest available form factor: 45x18mm!
The Arduino Nano 33 BLE Sense is a completely new board on a well-known form factor. It comes with a series of embedded sensors.
*) 9 axes inertial sensor: what makes this board ideal for wearable devices
*) humidity, and temperature sensor: to get highly accurate measurements of the environmental conditions
*) barometric sensor: you could make a simple weather station
*) microphone: to capture and analyze sound in real-time
*) gesture, proximity, light color, and light intensity sensor: estimate the room’s luminosity, but also whether someone is moving close to the board
So we can easily identify Ivory poaching, Trophy Hunting, and Human elephant conflict with the onboard sensors of Nano 33 BLE sense. Apart from this project, we will use inertial and gesture sensor data, to increase the accuracy in finding Poaching, hunting, and conflict. The major advantage of using the device is that we can deploy the AI model in it. So we can do live classification without any network. We need to only upload the data if there are any attacks. It also requires only low power hence the collar can run for a long time.
- In the future edition, we will use Lora modules instead of Wi-Fi with Nano 33 BLE sense to transfer the data to the cloud.
- Even though, Arduino Nano 33 BLE sense requires only low power. We will also use small solar panels to charge the batteries of the collar. So we get a very long lifetime for the collars.
- In future edition. we will collect more & more data to increase the accuracy of the model.


















{kind=link}
{kind=link}
Comments
Please log in or sign up to comment.