


Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
| ||||||
| ||||||
Hand tools and fabrication machines | ||||||
 |
| |||||
Every great artifact was made by an even greater civilization, and after some searching we found this Moai statue model made by Julien_DaCosta, the perfect start!
First, we 3D printed the model, after which we started sanding. With a couple of new found arm muscles, we applied the primer and final colour. To achieve the right look and feel we used the colour 'Bronze Antique Gold', how classy!
Our print had a little mishap, a hole in the head, so we hid it by gluing some fake leaves to the inside. The result is a good looking antique, with an imposing leaf crown.
BoxOur relic needs a fitting throne. To build it, we used a pile of bamboo left over from some yard work.
The first step is to determine the size, after which we can saw the bamboo to the desired lengths and glue it all together.
With the four walls and bottom firmly attached, the last part is cutting some more bamboo and laying it on top, we now have a box and lid!
To be honest, this was a lot of trial and error, combined with a small mountain of glue. Any box will do as long as the electronics fit.
ElectronicsAs for the electronics, we used a Raspberry Pi and a Google AIY kit.
To not reinvent the wheel, here is a tutorial for the Raspberry Pi and this will help with the AIY kit.
A short and snazzy step, just how we like it.
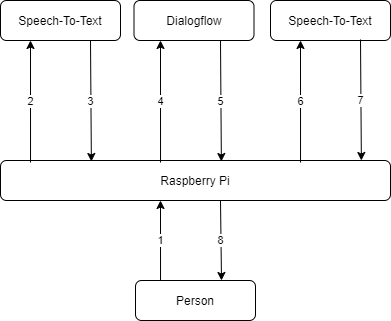
DataflowLast but not least, we need to write some code. No worries, it's added the this tutorial.Here is an overview of how the full project works:
1The microphone picks up someone speaking and records the audio.
2-3Using some Google magic (Speech-To-Text) we extract the text from the audio.
4-5This text is sent to our chatbot (Dialogflow) and is matched with an intent, after which one of the possible answers is sent back to the Raspberry Pi.
6-7Using Text-To-Speech, the text is converted to audio.
8This audio is played back to the person via the speaker.
Result!With all the hard work done, we can look back and question our life choices.We did however succeed in building a neat looking artifact, that is about as useful as a glass hammer.
To give some context to the pictures, the conversation with the artifact went something like this:
Question: "What is the meaning of life?"
Answer: "Please specify 'meaning' and 'life'."
Question:"Am I a good person?"
Answer:"Depends on your definition of 'good'."
Question: "You are useless, aren't you?!"
Answer: "I'm as useful as you are, so you decide."
Question: "Can you make a cheesy movie reference?
Answer: "42"
What a time to be alive...
{kind=link}
Comments
Please log in or sign up to comment.