



Hardware components | ||||||
 |
| × | 1 | |||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
| × | 1 | ||||
Software apps and online services | ||||||
 |
| |||||
| ||||||
| ||||||
 |
| |||||
 |
| |||||
 |
| |||||
It is a pretty tired thing that young kids should carry heavy backpacks go to school,or we should carry our commodity when we shopping. What if robot can help us do these tiresome jobs? To release our shoulders, this project designed an interesting vehicle named FOLLOWER,which can follow you and carry bags for you.
This project has been named FOLLOWER, its main functions are listed bellow:
- Follow target and keep appropriate distance with target
- Locate ifself in recorded map and realize visualization
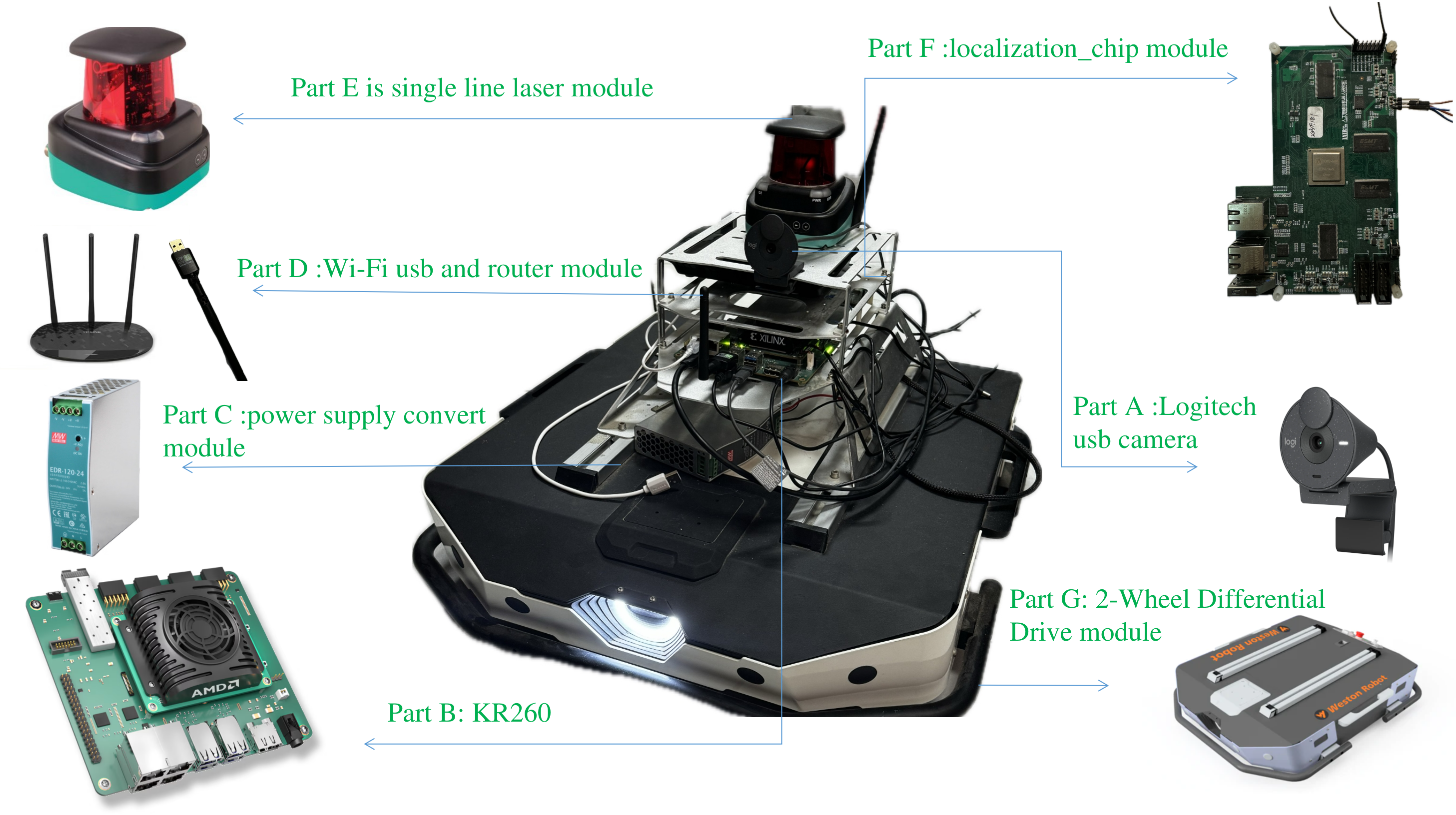
The whole system are designed as bellow:
Part A is a 1080p Logitech usb camera, which be used as vedio image input device, and transport the data to part B.
Part B is KR260, which is used for input video process, ROS communication, and send commands to control the ugv vehicle.
Part C is power supply convert module, which can convert the voltage to which the other module needed.
Part D is Wi-Fi usb and router module. The Wi-Fi usb module is used for testing, and the router is used for send data to the other device under the same LAN, like laptop.
Part E is single line laser module, which is used for scaning enviroment and send data to Part F to compute, so that the robot can locate itself.
Part F is our localization chip, which can do real-time single-line laser mapping and positioning, locate where is the FOLLOWER, and mark itself in the recorded map.
Part G is 2-Wheel Differential Drive module,which receive the command from KR260 and move.
3.1 Introduction to Yolo
You only look once (YOLO) is a Convolutional Neural Network (CNN) for performing object detection in real-time. CNNs are classifier-based systems that can process input images as structured arrays of data and recognize patterns between them. In view of leaving some resources for other design modules, we choose the yolov3 version with smaller parameters, which can still achieve pretty human body recognition. refer to PYNQ_Bootcamp_model_object_detection_section
class RosaiCameraYolov3(Node):
def __init__(self):
super().__init__('rosai_camera_demo')
self.scb = StatusControlBlock()
self.subscriber_ = self.create_subscription(Image, 'image_raw',
self.listener_callback, 10)
self.get_logger().info('[INFO] __init__, Create Subscription ...')
self.subscriber_ # prevent unused variable warning
self.publisher1 = self.create_publisher(Image, 'vision/asl', 10)
self.publisher2 = self.create_publisher(Twist, '/cmd_vel', 10)
anchor_list = [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326]
anchor_float = [float(x) for x in anchor_list]
self.anchors = np.array(anchor_float).reshape(-1, 2)
# Overlay the DPU and Vitis-AI .xmodel file
self.overlay = DpuOverlay("dpu.bit")
self.model_path = '/home/root/jupyter_notebooks/pynq-dpu/tf_yolov3_voc.xmodel'
self.get_logger().info("MODEL=" + self.model_path)
self.overlay.load_model(self.model_path)Create DPU runner
self.dpu = self.overlay.runner
self.get_logger().info('[INFO] __init__ exiting...')This function resizes the image with unchanged aspect ratio using padding.
def get_class(self, classes_path):This function performs pre-processing by helping us in converting the image into an array which can be fed for processing.
def pre_process(self, image, model_image_size):This function gets information on box position, its size along with confidence and box class probabilities
def get_feats(self, feats, anchors, num_classes, input_shape):This function is used to correct the bounding box position by scaling it
def correct_boxes(self, box_xy, box_wh, input_shape, image_shape):This function is used to get information on the valid objects detected and their scores
def boxes_and_scores(self, feats, anchors, classes_num, input_shape, image_shape):This function suppresses non-maximal boxes by eliminating boxes which are lower than the threshold
def nms_boxes(self, boxes, scores):This function gives essential information about the objects detected like bounding box information, score of the object detected and the class associated with it
def evaluate(self, yolo_outputs, image_shape, class_names, anchors):3.2 Using Vitis AI to recompile model
This project uses Vitis AI 3.5 to recomplie the tf2 model in modelzoo, cause the vitis ai config has been changed. refer to PYNQ_Bootcamp_model_recomplied_section
conda activate vitis-ai-tensorflow2
cd /media/LEARN/PYNQ_Bootcamp/models
sh vitisai_compile.sh kr260 quantized.h5 ./complied tf_yolov3_voc3.3 ROS node design
.we use pynq framework to utilize dpu for the cnn module in yolo computing.
We put the yolo processing module in callback function.
refer ro Kria-RoboticsAI/ROSAI
def listener_callback(self, msg):
self.get_logger().info("Starting of listener callback...")
bridge = CvBridge()
cv2_image_org = bridge.imgmsg_to_cv2(msg, desired_encoding="rgb8")
y1 = (128)
y2 = (128 + 280)
x1 = (208)
x2 = (208 + 280)
roi_img = cv2_image_org[y1:y2, x1:x2, :]
resized_image = cv2.resize(roi_img, (28, 28), interpolation=cv2.INTER_LINEAR)
roi_img_gray = cv2.cvtColor(resized_image, cv2.COLOR_BGR2GRAY)
cv2_image_normal = np.asarray(roi_img_gray / 255, dtype=np.float32)
cv2_image = np.expand_dims(cv2_image_normal, axis=2)
classes_path = "/root/ros2_ws/src/rosai_camera/rosai_camera/configs/voc_classes.txt"
class_names = self.get_class(classes_path)
inputTensors = self.dpu.get_input_tensors()
outputTensors = self.dpu.get_output_tensors()
shapeIn = tuple(inputTensors[0].dims)
shapeOut0 = (tuple(outputTensors[0].dims)) # (1, 13, 13, 75)
shapeOut1 = (tuple(outputTensors[1].dims)) # (1, 26, 26, 75)
shapeOut2 = (tuple(outputTensors[2].dims)) # (1, 52, 52, 75)Setup Buffers
input_data = [np.empty(shapeIn, dtype=np.float32, order="C")]
output_data = [np.empty(shapeOut0, dtype=np.float32, order="C"),
np.empty(shapeOut1, dtype=np.float32, order="C"),
np.empty(shapeOut2, dtype=np.float32, order="C")]
image = input_data[0]
frame = cv2_image_orgPre-processing
image_size = frame.shape[:2]
image_data = np.array(self.pre_process(frame, (416, 416)), dtype=np.float32)Fetch data to DPU and trigger it
image[0, ...] = image_data.reshape(shapeIn[1:])
job_id = self.dpu.execute_async(input_data, output_data)
self.dpu.wait(job_id)Retrieve output data
conv_out0 = np.reshape(output_data[0], shapeOut0)
conv_out1 = np.reshape(output_data[1], shapeOut1)
conv_out2 = np.reshape(output_data[2], shapeOut2)
yolo_outputs = [conv_out0, conv_out1, conv_out2]Decode output from YOLOv3
boxes, scores, classes = self.evaluate(yolo_outputs, image_size, class_names, self.anchors)
# Store information of the detected object which has the highest score. And store the class information of this object
if len(scores) == 0:
pass
else:
self.get_logger().info("scores=" + str(scores))
best_score = np.argmax(scores)
prediction = class_names[classes[best_score]]
if prediction == 'person':
self.get_logger().info("best_score=" + str(best_score))
# Draw bounding box
y_min, x_min, y_max, x_max = map(int, boxes[best_score])
rects = []
p1, p2 = ((int(x_min), int(y_min)), (int(x_max), int(y_max)))
rects.append([p1, p2])Create message to backup
self.scb.follow_target(rects)
msg = Twist()
msg.linear.x = float(self.scb.control_speed)
msg.linear.y = 0.0
msg.linear.z = 0.0
msg.angular.x = 0.0
msg.angular.y = 0.0
msg.angular.z = float(self.scb.control_turn)
self.publisher2.publish(msg)
frame = cv2.rectangle(frame, (x_min, y_min), (x_max, y_max), color=255)Label
text = f"{class_names[classes[best_score]]}: {scores[best_score]:.2f}"
text_size = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2)[0]
frame = cv2.putText(frame, text, (x_min, y_min - text_size[1]), cv2.FONT_HERSHEY_SIMPLEX, 1, 255, 1, cv2.LINE_AA)DISPLAY
cv2_bgr_image = cv2.cvtColor(cv2_image_org, cv2.COLOR_RGB2BGR)
cv2.imshow('rosai_demo', cv2_bgr_image)
cv2.waitKey(1)CONVERT BACK TO ROS & PUBLISH
image_ros = bridge.cv2_to_imgmsg(cv2_image)
self.publisher1.publish(image_ros)3.4 Control Strategy.
We set up logic like these:
- When the tracking target appears in the field of view of the car, if the target distance is outside the tracking range, the car turns and moves in the direction of the target.
- When the target is smaller than the tracking range, the car starts to slowly reverse. When it is within the tracking range.
- When the car follows at a constant speed, keeping the distance from the target and consistent with the target’s movement direction.
refer ro target_follow
3.5 Result
In simulation mode, we can see the frame with bounding box in screen, at the same time, in the rviz window, we can see the diff car moving with people that the system Identify.
In real mode, we can see the ugv vehicle can fellow me slowly, which can ensure that it will not hurt me.
3.6 Extern
We use our own 2-D Localization chip as the slave of KR260, make the FOLLWER can be located, so that in the subsequent versions, the function of automatically reaching the target position from point to point can be realized.
4. SummaryThis project uses KR260 as the core, PYNQ as the framework, ROS2 as the communication and control technology, selected the pre-trained model in Vitis AI's modelzoo, and used the compiler to redefine the architecture and compile it. Based on the typical routines in PYNQ and Kria-Robotics, some open source projects were embedded and absorbed to complete this project. Many problems were continuously solved in the process, such as modifying some bugs in the KRIA-PYNQ installation script and eliminating the original In the rosai-camera routine, the camera will crash when connected to ROS, etc. In general, a relatively complete project has been accomplished, which allows the 2-diff car to automatically follow the target and expand a series of external functional peripherals such as positioning and reaching designated locations. It has great practical value and broad business prospects. Finally, I would like to thank the event organizers for their strong support and the staff for their hard work.







{kind=link}
Comments
Please log in or sign up to comment.