
Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
| × | 1 | ||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
| ||||||
| ||||||
| ||||||
| ||||||
Hand tools and fabrication machines | ||||||
| ||||||
| ||||||
| ||||||
Detailed Project Blog here: https://medium.com/@AnandAI/touch-less-display-interfaces-on-edge-be8dc277c5b8
If you have any query or suggestion, you can reach me here
Interactive public kiosks are now so widely used viz. Banking (ATMs), Airport (Check-in), Government (e-Governance), Retail (Product Catalogue), Healthcare (Appointment), Schools (Attendance), Corporate (Registration), Events (Info) and the list goes on. While businesses move towards kiosks to better service delivery, touch-free interaction of all public devices has become an imperative to mitigate the spread of ubiquitous Corona virus.
Gesture or Speech Navigation might seem to address the above, but such devices are resource constrained to analyze such inputs. Have you noticed your mobile voice assistant, be it Siri or GAssist, gives up when mobile goes offline? Your voice-enabled car infotainment system fails to respond, while you drive remote roads. Even a conventional computer won’t be able to run multiple AI models concurrently.
Ain’t it nice to do it all on your device itself? Imagine a bed-side assistant device which can take visual or voice cues from bedridden patients. This is possible with the advent of Intel OpenVINO. It enables and accelerates deep learning inference from the edge, by doing hardware-conscious optimizations. OpenVINO supports CPU, iGPU, VPU, FPGA and GNAs. If you wanna get your hands wet, a Raspberry Pi along with Intel Movidius NCS 2 would be your best bet to toy with.
In this blog, we will try to build a Human-Computer Interaction (HCI) module which intelligently orchestrates 5 concurrently-run AI models, one feeding onto another. AI models for face detection, head pose estimation, facial landmarks computation and angle of gaze estimation identify gesture control inputs and trigger mapped actions. A child thread is deployed to run offline speech recognition, which communicates with the parent process to give parallel control commands based on user utterance, to assist and augment gesture control.
The solution source code can be found here.
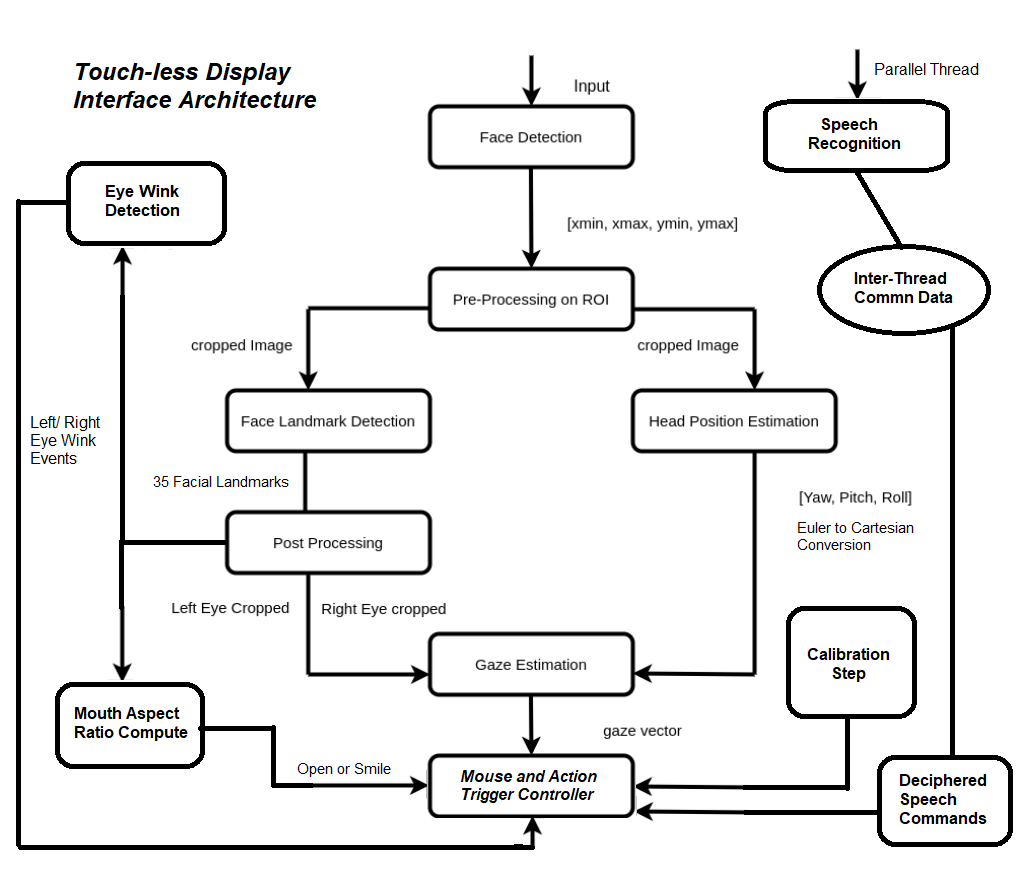
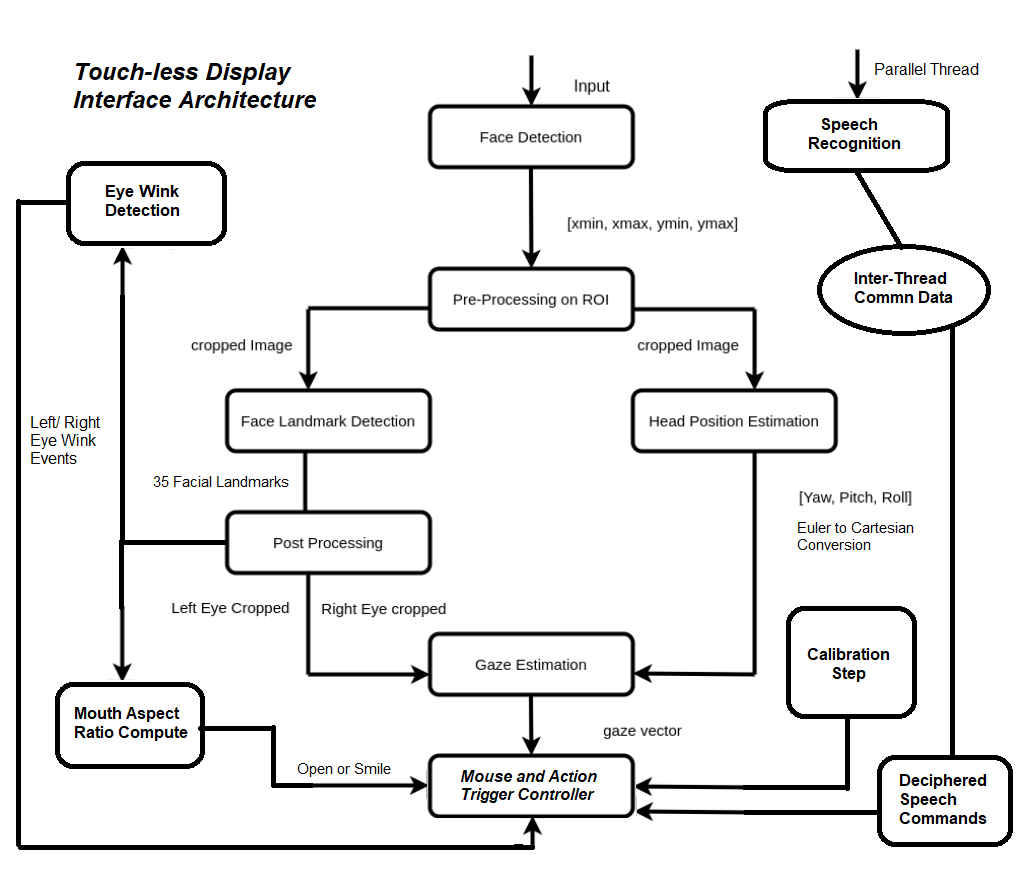
Architecture DiagramEach component in the architecture diagram is explained below.
There are 4 control modes defined in the system, to determine the mode of user input. We can switch between control modes using gestures.
- Control Mode 0: No Control
Gesture and Sound Navigation is turned off
- Control Mode 1: Gaze Angle Control
Mouse moves along with angle of eye gaze (faster)
- Control Mode 2: Head Pose Control
Mouse moves with changing head orientation (slower)
- Control Mode 3: Sound Control
Mouse slides in 4 directions and type based on user utterance
Calibration StepTo translate the 3D gaze orientation angles to 2D screen dimension, the system has to know the yaw and pitch angles corresponding to opposite corners of the screen. Given these 2 angles of opposite corners, we can interpolate the (x, y) location in the screen for intermediate (yaw, pitch) angles.
Therefore, the user will be prompted to look at opposite corners of the screen, when the application is initiated. Such a calibration step is needed to map the variation in gaze angles to the size and shape of the screen, in order for the “gaze mode” to function properly.
Without calibration also the system can function, albeit at the expense of generality. To demonstrate, the relative change in head orientation is taken as the metric to move mouse pointer, when the system is in “head pose” mode.
def moveWithGaze(self, x, y):
# To bound the x, y coordinates within screen.dimensions.
x = max(min(x, self.x_max), self.x_min)
y = max(min(y, self.y_max), self.y_min)
# To compute the x, y coordinates in the screen.
x_cord = self.w * (1 - (x - self.x_min) / (self.x_max - self.x_min))
y_cord = self.h * (y - self.y_min) / (self.y_max - self.y_min)
pyautogui.moveTo(x_cord, y_cord, duration=0.2)
# pyautogui.moveRel(-x*self.precision, y*self.precision, duration=self.speed)
def moveWithHead(self, x, y, headYawPitchBounds):
# Fixing 60x60 box as yaw and pitch boundaries to
# correspond to head turning left and right (yaw)
# and also moving up and down (pitch)
x_min = headYawPitchBounds[0]
x_max = headYawPitchBounds[1]
y_min = headYawPitchBounds[0]
y_max = headYawPitchBounds[1]
# To bound the x, y coordinates within screen.dimensions.
x = max(min(x, x_max), x_min)
y = max(min(y, y_max), y_min)
# To compute the x, y coordinates in the screen.
x_cord = self.w * (1 - (x - x_min) / (x_max - x_min))
y_cord = self.h * (y - y_min) / (y_max - y_min)
pyautogui.moveTo(x_cord, y_cord, duration=0.2)Four Pre-trained OpenVINO models are executed on the input video stream, one feeding onto another, to detect a) Face Location b) Head Pose c) Facial Landmarks and d) Gaze Angles.
a) Face Detection: A pruned MobileNet backbone with efficient depth-wise convolutions is used. The model outputs (x, y) coordinates of the face in the image, which is fed as input to steps (b) and (c)
b) Head Pose Estimation: The model outputs Yaw, Pitch and Roll angles of head, taking face image as input from step (a)
c) Facial Landmarks: a custom CNN used to estimate 35 facial landmarks.
This model takes cropped face image from step (a) as input and computes facial landmarks, as above. Such a detailed map is required to identify facial gestures, though it is double as heavy in compute demand (0.042 vs 0.021 GFlops), compared to the Landmark Regression model, which gives just 5 facial landmarks.
d) Gaze Estimation: custom VGG-like CNN for gaze direction estimation.
The network takes 3 inputs: left eye image, right eye image, and three head pose angles — (yaw, pitch, and roll) — and outputs 3-D gaze vector in Cartesian coordinate system.
To feed one model output to another model as input, the return values of each model need to be decoded and post-processed.
For instance, to determine gaze angle, the head orientation need to be numerically combined with the vector output from gaze model, as below.
def preprocess_output(self, output, head_position):
'''
Before feeding the output of this model to the next model,
you might have to preprocess the output. This function is where you can do that.
'''
roll = head_position[2]
gaze_vector = output / cv2.norm(output)
cosValue = math.cos(roll * math.pi / 180.0)
sinValue = math.sin(roll * math.pi / 180.0)
x = gaze_vector[0] * cosValue + gaze_vector[1] * sinValue
y = gaze_vector[0] * sinValue + gaze_vector[1] * cosValue
return (-x*10, y*10)Similarly, the facial landmarks model returns ratio of input image size. Hence, we need to multiply output by image width and height to compute (x, y) coordinates of 35 landmarks.
def preprocess_output(self, outputs, image):
'''
Before feeding the output of this model to the next model,
you might have to preprocess the output. This function is where you can do that.
'''
# https://docs.openvinotoolkit.org/latest/omz_models_intel_facial_landmarks_35_adas_0002_description_facial_landmarks_35_adas_0002.html
h, w = image.shape[0:2]
paddingConstant = 10
landmarks = outputs['align_fc3']
# Computing the left eye box corners
box = (landmarks[0][0], landmarks[0][1], landmarks[0][12*2], landmarks[0][12*2+1])
box_left = box * np.array([w, h, w, h])
box_left = box_left.astype(np.int32) + \
[paddingConstant, paddingConstant, -paddingConstant, -paddingConstant]
left_eye = image[box_left[3]:box_left[1], box_left[2]:box_left[0]]
# Computing the right eye box corners
box = (landmarks[0][2*2], landmarks[0][2*2+1], landmarks[0][2*17], landmarks[0][2*17+1])
box_right = box * np.array([w, h, w, h])
box_right = box_right.astype(np.int32) + \
[-paddingConstant, paddingConstant, paddingConstant, -paddingConstant]
right_eye = image[box_right[3]:box_right[1], box_right[0]:box_right[2]]
# Computing the left eye landmarks
p0 = self.scaleBoxes((landmarks[0][0], landmarks[0][1]), w, h)
p1 = self.scaleBoxes((landmarks[0][1*2], landmarks[0][1*2+1]), w, h)
p12 = self.scaleBoxes((landmarks[0][12*2], landmarks[0][12*2+1]), w, h)
p13 = self.scaleBoxes((landmarks[0][13*2], landmarks[0][13*2+1]), w, h)
p14 = self.scaleBoxes((landmarks[0][14*2], landmarks[0][14*2+1]), w, h)
# Computing the right eye landmarks
p2 = self.scaleBoxes((landmarks[0][2*2], landmarks[0][2*2+1]), w, h)
p3 = self.scaleBoxes((landmarks[0][3*2], landmarks[0][3*2+1]), w, h)
p15 = self.scaleBoxes((landmarks[0][15*2], landmarks[0][15*2+1]), w, h)
p16 = self.scaleBoxes((landmarks[0][16*2], landmarks[0][16*2+1]), w, h)
p17 = self.scaleBoxes((landmarks[0][17*2], landmarks[0][17*2+1]), w, h)
# Computing the mouth landmarks
p8 = self.scaleBoxes((landmarks[0][8*2], landmarks[0][8*2+1]), w, h)
p9 = self.scaleBoxes((landmarks[0][9*2], landmarks[0][9*2+1]), w, h)
p10 = self.scaleBoxes((landmarks[0][10*2], landmarks[0][10*2+1]), w, h)
p11 = self.scaleBoxes((landmarks[0][11*2], landmarks[0][11*2+1]), w, h)
return box_left, box_right, left_eye, right_eye, \
p0, p1, p12, p13, p14, p2, p3, p15, p16, p17, p8, p9, p10, p11While output of facial landmark and gaze estimation models can be easily post-processed as above, the conversion of head pose estimation model output is a bit more involved.
Euler Angles to Rotation MatricesNote the “Head Pose Estimation” model outputs only the attitude, i.e. Yaw, Pitch and Roll angles of the head. To obtain the corresponding direction vector, we need to compute the rotation matrix, using attitude.
i) Yaw is a counterclockwise rotation of α about the z-axis.
ii) Pitch is a counterclockwise rotation of β about the y-axis.
iii) Roll is a counterclockwise rotation of γ about the x-axis.
We can place a 3D body in any orientation, by rotating along 3 axes, one after the other. Hence, to compute the direction vector, you need to multiply the above 3 matrices.
# yaw and pitch are important for mouse control
poseArrowX = orientation[0] #* arrowLength
poseArrowY = orientation[1] #* arrowLength
# Taking 2nd and 3rd row for 2D Projection
############################# LEFT EYE ###################################
cv2.arrowedLine(frame, leftEye_Center,
(int((xCenter_left + arrowLength * (cosR * cosY + sinY * sinP * sinR))),
int((yCenter_left + arrowLength * cosP * sinR))), (255, 0, 0), 4)
# center to top
cv2.arrowedLine(frame, leftEye_Center,
(int(((xCenter_left + arrowLength * (sinY * sinP * cosR - cosY * sinR)))),
int((yCenter_left + arrowLength * cosP * cosR))), (0, 0, 255), 4)
center to forward
cv2.arrowedLine(frame, leftEye_Center, \
(int(((xCenter_left + arrowLength * sinY * cosP))), \
int((yCenter_left - arrowLength * sinP))), (0, 255, 0), 4)
############################# RIGHT EYE ###################################
cv2.arrowedLine(frame, rightEye_Center,
(int((xCenter_right + arrowLength * (cosR * cosY + sinY * sinP * sinR))),
int((yCenter_right + arrowLength * cosP * sinR))), (255, 0, 0), 4)
# center to top
cv2.arrowedLine(frame, rightEye_Center,
(int(((xCenter_right + arrowLength * (sinY * sinP * cosR - cosY * sinR)))),
int((yCenter_right + arrowLength * cosP * cosR))), (0, 0, 255), 4)
center to forward
cv2.arrowedLine(frame, rightEye_Center,
(int(((xCenter_right + arrowLength * sinY * cosP))),
int((yCenter_right - arrowLength * sinP))), (0, 255, 0), 4)So far, we have controlled the mouse pointer using head and gaze. But to use a kiosk, you also need to trigger events, such as ‘Left Click’, ‘Right Click’, ‘Scroll’, ‘Drag’ etc.
In order to do so, a set of pre-defined gestures need to be mapped to each event, and be recognized from the visual input. Two events can be mapped to ‘wink’ event of left and right eye, but they need to be identified as ‘wink’.
You can easily notice that the number of white pixels will suddenly increase when the eyes are open, and decrease when closed. We can just count the white pixels to differentiate open vs closed eye.
But in real world, above logic is not reliable because white pixel value itself can range. We can always use Deep Learning or ML techniques to classify but its advisable to use a numerical solution, in the interest of efficiency, especially when you code for edge devices.
Lets see how to numerically detect winks using signals in 4 steps!
- Calculate frequency of pixels in range 0–255 (histogram)
2. Compute spread of non-zero pixels in the histogram. When an eye is closed, the spread will take a sudden dip and vice-versa.
3. Try to fit a inverse sigmoid curve at the tail-end of the above signal.
4. If successful fit is found, then confirm the ‘step down’ shape of fitted curve and declare it as ‘wink’ event. (no curve fit = eye is not winking)
Algorithm Explanation:
If above steps are not clear, then see how the histogram spread graph falls, when an open eye is closed.
Given the above signal, you can imagine that the curve would take shape of ‘S’ when the eye is opened for a few seconds. This can be mathematically parameterized using a sigmoid function.
But since we need to detect ‘wink’ event shown above, the shape of the curve will take the form of an inverse sigmoid function. To flip the sigmoid function about the x-axis, find f(-x)
Take any online function visualizer to plot the above function and change parameters to see how reverse ‘S’ shape is changing (to fit the above Fig. Histogram Spread)
Thus, if any similar shape is found by parametric curve fit algorithm, at the tail end of the histogram spread curve, then we can call it a ‘wink’. The curve fit algo tries to solve a nonlinear least-squares problem.
# Code to fit the inverse sigmoid curve to tail end of signal
def sigmoid(x, L ,x0, k, b):
y = L / (1 + np.exp(k*(x-x0)))+b
return (y)
def isCurveSigmoid(pixelCounts, count):
try:
xIndex = len(pixelCounts)
p0 = [max(pixelCounts), np.median(xIndex),1,min(pixelCounts)] # this is an mandatory initial guess
popt, pcov = curve_fit(sigmoid, list(range(xIndex)), pixelCounts, p0, method='lm', maxfev=5000)
yVals = sigmoid(list(range(xIndex)), *popt)
# May have to check for a value much less than Median to avoid false positives.
if np.median(yVals[:10]) - np.median(yVals[-10:]) > 15:
print('Triggered Event')
return True
except Exception as err:
print(traceback.format_exc())
return False
def findCurveFit(eye, image, pixelCount, frame_count, numFrames = 50):
triggerEvent = False
if (len(image) == 0):
return pixelCount, False
# Convert to gray scale as histogram works well on 256 values.
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# calculate frequency of pixels in range 0-255
histg = cv2.calcHist([gray],[0],None,[256],[0,256])
# hack to know whether eye is closed or not.
# more spread of pixels in a histogram signifies an opened eye
activePixels = np.count_nonzero(histg)
pixelCount.append(activePixels)
if len(pixelCount) > numFrames and frame_count % 15 == 0:
if isCurveSigmoid(pixelCount[-numFrames+10:], len(pixelCount)):
print('Event Triggered...')
pixelCount.clear()
plt.clf()
triggerEvent = True
return pixelCount, triggerEventNote: An efficient way to compute the above can be,
- Consider strip of ’n’ recent values in non-zero Histogram Spread.
- Compute the median & std of ‘k’ values in the front and tail end of strip.
- If difference in median > threshold and both std < threshold, then detect eye wink event, as it’s most likely an inverse sigmoid shape.
Alternatively, we can also use the below algorithm to find eye winks.
- Take the first differential of Histogram Spread values
- Find the peak in the first differential values to find sudden spike
- Find reflection of the signal and find peak to find sudden dip
- If peak is found in both the above steps, then its just a blink
- If peak is found only in reflection, then its a wink event.
The above method is more efficient than curve fitting, but can lead to many false positives, as peak detection is not always reliable, especially at low light. Middle of the road approach would be to use median and standard deviation to estimate the shape of the curve.
# To detect wink from stream of eye images and print the sequence of Event trigger
while(runLoop):
for i in range (1000):
# read the image
image = cv2.imread("eyeImages_day/eye"+str(i) + ".jpg", 1)
# Convert to gray scale as histogram works well on 256 values.
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# calculate frequency of pixels in range 0-255
histg = cv2.calcHist([gray],[0],None,[256],[0,256])
# hack to know whether eye is closed or not.
# more spread of pixels in a histogram signifies an opened eye
activePixels = np.count_nonzero(histg)
pixelCount.append(activePixels)
# check for peak only if at least 50 frames are processed.
if len(pixelCount) > 50:
diff = np.diff(pixelCount[-50:])
peaks = peakutils.peak.indexes(np.array(diff), thres=0.8, min_dist=2)
x = np.array([i * -1 for i in diff])
peaksReflected = peakutils.peak.indexes(np.array(x), thres=0.8, min_dist=2)
# if peak is there on upright and reflected signal then the closed eyes are open soon
# i.e. it denotes a blink and not a gesture. But if peak is found only on the reflected
# signal then eyes are closed for long time to indicate gesture.
if (peaksReflected.size > 0 and x[peaksReflected[0]] > 0 and peaks.size == 0):
print('Event triggered at ' + str(i) + '...')
pixelCount.clear()
# Display the resulting frame
cv2.imshow('frame',image)
if cv2.waitKey(10) & 0xFF == ord('q'):
runLoop = False
exit()Eye Aspect Ratio (EAR) is computed in this classic facial landmark paper to determine eye blinks.
We cannot use above formula to determine eye gesture, as our model does not estimate such a dense landmark map. However, inspired by EAR, we can compute MAR based on the available 4 landmarks obtained from OpenVINO model, as below.
Two gesture events can be identified using MAR:
- if MAR > threshold, then person is smiling
- if MAR < threshold, then person is yawning
We have liberty to attach 2 commands corresponding to these two gestures.
Threading and Process-Thread CommunicationTo enhance control, we can enable sound based navigation also, along with gesture control. However, system then needs to continuously monitor user utterances to identify commands while it is analyzes image frames from input video stream.
Naturally therefore, it is prudent to run the speech recognition model in a different thread and let the child-thread communicate with the parent process. The child thread will recognize vocal commands to move the mouse or to write on the screen and pass it on to the parent using shared Queue data structure in Python (as shown below).
The parent process will run all the above AI models and the computation required for gesture recognition, to enable head and gaze control modes. Thus, it is possible to take gesture and sound control commands in parallel, but for the sake of usability, in this project we chose to take sound commands separately in Control Mode 3.
Speech RecognitionTo decode sound waves, we use OpenVINO Feature Extraction & Decoder Library which takes in and transcribe the audio coming from the microphone. We have used the speech library as mentioned here to run speech recognition on the edge, without going online.
As the recognition model is optimized at the expense the accuracy, some tweaks are required to identify spoken command. Firstly, we limit the command vocabulary to say, ‘up’, ‘down’, ‘left’ & ‘right’ only. Secondly, similar sounding synonyms of command words are stored in a dictionary to find the best match. For instance, ‘right’ command could be recognized as ‘write’.
The function is so written that commands and also synonyms can easily be extended. To enable user entry, speech to write function is also enabled. This has enabled to user to type in alphabets and numbers. Eg: PNR number.
# Speech Recognition Thread identifies the command from defined synonyms and inserting to stt Queue
def stopStream(stream_reader):
if stream_reader:
stream_reader.stop_stream()
stream_reader = None
def received_frames(frames, speech, stt):
speech.push_data(frames, finish_processing=False)
utt_text, is_stable = speech.get_result()
rh_result = utt_text.decode("utf-8").strip().lower()
if (len(rh_result) > 0):
stt.put(rh_result)
def load_device():
"""Reload audio device list"""
device_list, default_input_index, loopback_index = \
audio_helper.get_input_device_list()
if not device_list:
print("No audio devices available")
return device_list
# Function to search for match with any defined synonyms of each command
def detectSoundEvent(utterance, controls, control_syn):
utters = utterance.split(' ')[-3:]
utters.reverse()
print(utters)
for utter in utters:
for control in controls:
synonyms = control_syn.get(control)
for synonym in synonyms:
if synonym in utter:
print('Event Trigger: ' + control)
return control, utters[-1]
return None, utters[0] #last word will return as reversed
#####################################################################
# Initializing the Speech Recognition Thread
#####################################################################
# You can add more controls as you deem fit.
numbers = ['zero', 'one', 'two', 'three', 'four', \
'five', 'six', 'seven', 'eight', 'nine']
controls = ['left', 'right', 'up', 'down']
control_syn = {}
for control in controls:
control_syn.setdefault(control, [])
# Need to account for similar sounding words as speech recog is on the edge!
control_syn['left'].extend(['let', 'left', 'light', 'live', 'laugh'])
control_syn['right'].extend(['right', 'write', 'great', 'fight', 'might', 'ride'])
control_syn['up'].extend(['up', 'hop', 'hope', 'out'])
control_syn['down'].extend(['down', 'doubt', 'though'])
device_list = load_device()
stream_reader = audio_helper.StreamReader(
device_list[1][0], received_frames)
if not stream_reader.initialize():
print("Failed to initialize Stream Reader")
speech.close()
speech = None
return
speech = SpeechManager()
print('speech config = ' + str(SPEECH_CONFIG))
if not speech.initialize(SPEECH_CONFIG,
infer_device='CPU',
batch_size=8):
print("Failed to initialize ASR recognizer")
speech.close()
speech = None
return
stt = Queue()
prevUtterance = ''
reading_thread = Thread(target=stream_reader.read_stream, \
args=(speech, stt), daemon=True)
reading_thread.start()The gesture control commands are configured as below. However, you can easily change the gesture-command mapping.
Mouse pointer is controlled using pyautogui library. Functions such as move(), moveTo(), click(), drag(), scroll(), write() etc are used to trigger events corresponding to the above gestures.
Stickiness Feature and OptimizationThe gaze of an eye or pose of a head will continuously change at least a bit, even if unintended. Such natural motions should not be considered as a command, otherwise the mouse pointer will become jittery. Hence, we introduced a ‘stickiness’ parameter within which the motion is ignored. This has greatly increased the stability and usability of gesture control.
Finally, Intel VTune profiler is used to find hotspots and optimize the application code. A shell script vtune_script.sh is fed into the VTune GUI which initiates the project with suitable arguments.
ConclusionThe project demonstrates the capability of Intel OpenVINO to handle multiple Edge AI models in sequence and in parallel. Many control inputs are also sourced to demonstrate the flexibility. But to deploy a custom solution you can choose controls, as you deem fit.
For instance, Gaze control may be ideal for big screen while head pose control for laptop screen. Either way, Sound Control can help to accept custom form entries or vocal commands. Gesture-action mapping can also be modified. Yet the point you can drive home is the possibility to chain multiple hardware optimized AI models on the Edge, coupled with efficient numerical computing to solve interesting problems.
The solution source code can be found here.
If you have any query or suggestion, you can reach me here
References[1] Intel OpenVINO Official Docs:https://docs.openvinotoolkit.org
[2] Intel® Edge AI for IoT Nanodegree by Udacity. Idea inspired from Final Course Project.https://classroom.udacity.com/nanodegrees/nd131
[3] Real-Time Eye Blink Detection using Facial Landmarks by Tereza Soukupova and Jan Cech, Faculty of E.E., Czech Technical University in Prague.
Architecture Diagram







{kind=link}
{kind=link}
Comments
Please log in or sign up to comment.