

Hardware components | ||||||
 |
| × | 1 | |||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
Note: This is the second version of my lane detection project, if you haven't seen the previous version, make sure to check it out here! It's a great starting point for learning computer vision.
IntroductionIn any driving scenario, lane lines are an essential component of indicating traffic flow and where a vehicle should drive. It's also a good starting point when developing a self-driving car! Building on my previous lane detection project, I've implemented a curved lane detection system that works much better, and is more robust to challenging environments. The lane detection system was written in Python using the OpenCV library. Here's the current image processing pipeline:
- Distortion Correction
- Perspective Warp
- Sobel Filtering
- Histogram Peak Detection
- Sliding Window Search
- Curve Fitting
- Overlay Detected Lane
- Apply to Video
In my previous lane detection project, I'd developed a very simple lane detection system that could detect straight lane lines in an image. It worked decently under perfect conditions, however it would fail to detect curved lanes accurately, and was not robust to obstructions and shadows. This version improves upon both of these limitations.
Distortion CorrectionCamera lenses distort incoming light to focus it on the camera sensor. Although this is very useful in allowing us to capture images of our environment, they often end up distorting light slightly inaccurately. This can result in inaccurate measurements in computer vision applications. However, we can easily correct this distortion.
How would you do this? You can calibrate your image against a known object, and generate a distortion model which accounts for lens distortions. This object is often an asymmetric checkerboard, similar to the one below:
The camera used in the test video was used to take 20 pictures of a checkerboard, which were used to generate the distortion model. We begin by converting the image to grayscale, then applying the cv2.findChessboardCorners() function. We already know that this chessboard is a 2 dimensional object with exclusively straight lines, so we can apply some transformations to the detected corners to align them properly. I used the cv2.CalibrateCamera() to get the distortion coefficients and the camera matrix. The camera has been calibrated!
You can then use cv2.undistort() to correct the rest of your input data. You can see the difference between the original image of the checkerboard and the corrected image below:
Here's the exact code I used for this:
def undistort_img():
# Prepare object points 0,0,0 ... 8,5,0
obj_pts = np.zeros((6*9,3), np.float32)
obj_pts[:,:2] = np.mgrid[0:9, 0:6].T.reshape(-1,2)
# Stores all object points & img points from all images
objpoints = []
imgpoints = []
# Get directory for all calibration images
images = glob.glob('camera_cal/*.jpg')
for indx, fname in enumerate(images):
img = cv2.imread(fname)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, corners = cv2.findChessboardCorners(gray, (9,6), None)
if ret == True:
objpoints.append(obj_pts)
imgpoints.append(corners)
# Test undistortion on img
img_size = (img.shape[1], img.shape[0])
# Calibrate camera
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, img_size, None,None)
dst = cv2.undistort(img, mtx, dist, None, mtx)
# Save camera calibration for later use
dist_pickle = {}
dist_pickle['mtx'] = mtx
dist_pickle['dist'] = dist
pickle.dump( dist_pickle, open('camera_cal/cal_pickle.p', 'wb') )
def undistort(img, cal_dir='camera_cal/cal_pickle.p'):
#cv2.imwrite('camera_cal/test_cal.jpg', dst)
with open(cal_dir, mode='rb') as f:
file = pickle.load(f) mtx = file['mtx']
dist = file['dist']
dst = cv2.undistort(img, mtx, dist, None, mtx)
return dst
undistort_img()
img = cv2.imread('camera_cal/calibration1.jpg')
dst = undistort(img) # Undistorted image
The functions used for these can also be found in the Jupyter Notebook under the Code section.
Here's the distortion correction applied to an image of the road. You might not be able to notice the slight difference, but it can have a huge impact on image processing.
Detecting curved lanes in camera space is not very easy. What if we could get a birds eye view of the lanes? That can be done by applying a perspective transformation on the image. Here's what it looks like:
Notice anything? By assuming that the lane is on a flat 2D surface, we can fit a polynomial that can accurately represent the lane in lane space! Isn't that cool?
You can apply these transformations to any image using the cv2.getPerspectiveTransform() function to get the transformation matrix, and cv2.warpPerspective() to apply it to an image. Here's the code I used for this:
def perspective_warp(img,
dst_size=(1280,720),
src=np.float32([(0.43,0.65),(0.58,0.65),(0.1,1),(1,1)]),
dst=np.float32([(0,0), (1, 0), (0,1), (1,1)])):
img_size = np.float32([(img.shape[1],img.shape[0])])
src = src* img_size
# For destination points, I'm arbitrarily choosing some points to be
# a nice fit for displaying our warped result
# again, not exact, but close enough for our purposes
dst = dst * np.float32(dst_size)
# Given src and dst points, calculate the perspective transform matrix
M = cv2.getPerspectiveTransform(src, dst)
# Warp the image using OpenCV warpPerspective()
warped = cv2.warpPerspective(img, M, dst_size)
return warped
In the previous version, I had filtered out the lane lines using color. However, this isn't always the best option. If the road uses light colored concrete instead of asphalt, the road easily passes through the color filter, and the pipeline will perceive it as a white lane line. Not good.
Instead, we can use a method similar to our edge detector, this time to filter out the road. Lane lines typically have a high contrast to the road, so we can use this to our advantage. The Canny edge detector previously used in version 1 makes use of Sobel Operator to get the gradient of an image function. The OpenCV documentation has a fantastic explanation on how it works. We'll be using this to detect areas of high contrast to filter lane markings and ignore the road.
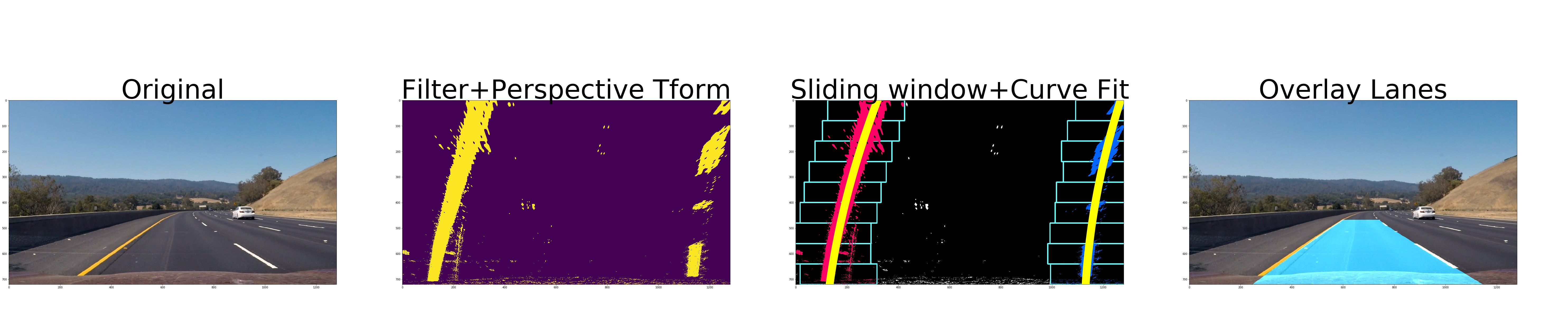
We'll still be using the HLS Colorspace again, this time to detect changes in Saturation and Lightness. The sobel operators are applied to these two channels, and we extract the gradient with respect to the x axis, and add the pixels which pass our gradient threshold to a binary matrix representing the pixels in our image. Here's what it looks like in camera space and lane space:
Note that the parts of the image that were further away from the camera don't retain their quality very well. Due to the resolution limitations of the camera, data from objects further away are heavily blurred and noisy. We don't need to focus on the entire image, so we can just use a portion of it. Here's what the image we'll use will look like:
We'll be applying a special algorithm called the Sliding Window Algorithm to detect our lane lines. However, before we can apply it, we need to determine a good starting point for the algorithm. It works well if it starts out in a spot where there are lane pixels present, but how can we detect the location of these lane pixels in the first place? It's actually really simple!
We'll be getting a histogram of the image with respect to the X axis. Each portion of the histogram below displays how many white pixels are in each column of the image. We then take the highest peaks of each side of the image, one for each lane line. Here's what the histogram looks like, next to the binary image:
The sliding window algorithm will be used to differentiate between the left and right lane boundaries so that we can fit two different curves representing the lane boundaries.
The algorithm itself is very simple. Starting from the initial position, the first window measures how many pixels are located inside the window. If the amount of pixels reaches a certain threshold, it shifts the next window to the average lateral position of the detected pixels. If not enough pixels are detected, the next window starts in the same lateral position. This continues until the windows reach the other edge of the image.
The pixels that fall within the windows are given a marker. In the images below, the blue marked pixels represent the right lane, and the red ones represent the left:
The rest of the project is really easy. We apply polynomial regression to the red and blue pixels individually using np.polyfit(), and then the detector is mostly done!
Here's what the curves look like:
Here's the final part of the detection system, the user interface! We simply create an overlay which fills in the detected portion of the lane, and then we can finally apply it to video. Once put through the video pipeline, you should see the following output:
ConclusionAnd that's it, a basic curved lane detector! It works much better than the previous version, and it even handles curved lanes! However, it still does get affected by shadows and drastic changes in road texture to some extent. In my next lane detection project, we'll use some machine learning techniques to develop an incredibly robust lane and vehicle detection system. In the meantime, feel free to follow me on hackster.io and provide feedback on my projects!









{kind=link}
Comments