


Hardware components | ||||||
 |
| × | 1 | |||
Software apps and online services | ||||||
 |
| |||||
 |
| |||||
| ||||||
As I've been diving into the world of accelerated applications on AMD-Xilinx FPGAs, I've come to find emulation of my accelerated applications as an invaluable tool.
The only catch is that as far as I've found, for boards that boot from QSPI like the Kria KV260/KR260 and the Zynqberry it's not possible to to emulate Linux applications in Vitis. Boards that don't have QEMU support also cannot have Linux-based applications emulated in Vitis since QEMU is what the emulator is using for Linux in Vitis.
Thus, I've created this project on the ZCU104 (I don't currently own a ZCU104, but I'm emulating so I don't need it!) to be able to emulate some of the elements of my accelerated application that I am developing for my Kria boards. I selected the ZCU104 since it is Zynq UltraScale MPSoC based, has good QEMU support, and doesn't require an additional Vivado license.
Note: I am using version 2021.2 in this project post. So these steps are only directly applicable to 2021.1 and 2021.2 (meaning I can't guarantee the following steps will work in any other versions besides 2021.x). I know that the 2022.1 workflow is a bit different and I will post an updated version of this when I get it figured out.
Hardware Design in VivadoFor the hardware design, I started with the same based I have for my previous accelerated designs on the Kria in terms of clocking resources, interrupt controller, and available AXI interfaces (see exact details here, the setup of the block design is exactly the same between the Kria and the ZCU104 in this case)
A quick rundown of the block design: start by adding Zynq UltraScale+ Processing System IP block and run the corresponding block automation to apply the board presets. Then add a clocking wizard IP with desired number of reference clocks for the accelerated kernel to use, each with their own processor system reset IP.
Add an AXI Interrupt Controller and select the clock you plan to set as the default for the accelerated kernel in the Platform Setup tab to drive it in the connection automation tool.
Since DDS compilers are a common IP of choice for me, I decided that I should test out how driving one from the Vitis accelerated kernel was like. It's also a good bench mark since I've posted two previous projects to highlight the difference between driving one from the programmable logic vs embedded C from a bare metal application running on an ARM-core of the Zynq.
So I added a DDS compiler IP to the block design. Since I plan to have the accelerated kernel driving both the phase input and reading out the data waveform, the only port connected in the block design is the clock port (which again is the clock set as the default for the accelerated kernel in the Platform Setup tab).
For the DDS compiler IP settings itself, I set it to stream the input phase increment value with no offset option. The output is just the data value of a cosine waveform with no pack framing on the AXI Stream interface.
Configure the Platform Setup tab to enable the desire AXI ports, clocks, and interrupt for the accelerated kernel to have access to.
For the AXI Steam Port tab, enable the master and slave ports of the DDS compiler and give them the appropriate SP Tag names. I personally found using the port names of the IP block in the block design the most helpful since the SP Tag is used as a reference designator in Vitis by the kernel.
Enable the desired clocks for the accelerated kernel to use and set the default clock.
Then enable the interrupt from the AXI interrupt controller:
Then give the platform the desired name, board info, etc.:
Validate the block design, save it, and then generate the block design (select Generate Block Design from the Flow Navigator window). Create an HDL wrapper then run synthesis, implementation, and generate a bitstream for the design.
Export PlatformExport the platform by selecting the Export Platform option from the Flow Navigator window. Be sure to select an option to include hardware emulation, I always choose the option that includes hardware and emulation so I don't have to bother with re-exporting if I do decide to implement the design on hardware.
Check the option to include the bitstream in the exported platform.
The Platform Properties can be left as their default values.
The platform can be exported to any desired directory location, but I like to use the default location in the top level of the Vivado project directory. I also am sure to use the platform name for the XSA file name.
The top level of the Vivado project directory is also where I like to keep everything else for the accelerated design in the following steps including the PetaLinux project, Linux components directory, and Vitis workspace.
Create PetaLinux ProjectThe emulation in Vitis I plan to use is emulating a Linux OS for the target device (since the end goal is a Linux application), thus the proper Linux components need to be generated through building a PetaLinux project before getting into Vitis.
Source the PetaLinux tools and create a project targeting the appropriate Zynq platform (the ZynqMP since I'm using the ZCU104) in the desired directory (top level of the Vivado project directory in my case as mentioned previously which is ~/zcu104_prj). Then change directories into the newly created PetaLinux project.
~$ source /tools/Xilinx/PetaLinux/2021.2/settings.sh
~$ cd ./zcu104_prj/
~/zcu104_prj$ petalinux-create --type project --template zynqMP --name linux_os
~/zcu104_prj$ cd ./linux_os/Import the hardware platform exported from Vivado (again, I exported the XSA platform file to the default location in the Vivado project top level directory):
~/zcu104_prj/linux_os$ petalinux-config --get-hw-description ../Leave all of the hardware system settings set to their defaults, but if you're also using the ZCU104, update the machine name under DTG Settings to zcu104-revc.
DTG Settings --> (zcu104-revc) MACHINE_NAMEExit the system configuration editor and opt to save the changes.
Enable XRT in Root FilesystemA few package dependencies need to be added to the root filesystem to support emulation such as XRT and ZOCL.
Launch the root filesystem configuration editor:
~/zcu104_prj/linux_os$ petalinux-config -c rootfsEnable XRT, ZOCL, and OpenCL headers under filesystem packages as shown below. Also enable the general PetaLinux package group, as well as the networking stack, OpenCV, and Utilities package groups. If there are any other package dependencies relevant to your accelerated application, enable them as well.
Filesystem Packages
--> libs
----> xrt
------ [*] xrt
------ [*] xrt-dev
----> zocl
------ [*] zocl
----> opencl-clhpp
------ [*] opencl-clhpp-dev
----> opencl-headers
------ [*] opencl-headers
Petalinux Package Groups
--> packagegroup-petalinux
---- [*] packagegroup-petalinux
--> packagegroup-petalinux-networking-stack
---- [*] packagegroup-petalinux-networking-stack
--> packagegroup-petalinux-opencv
---- [*] packagegroup-petalinux-opencv
--> packagegroup-petalinux-utils
---- [*] packagegroup-petalinux-utilsThe ZOCL driver node also needs to be added to the device tree, so open system-user.dtsi with your preferred text editor:
~/zcu104_prj/linux_os$ gedit ./project-spec/meta-user/recipes-bsp/device-tree/files/system-user.dtsiAnd add the following node along with any others relevant to your design:
/include/ "system-conf.dtsi"
/{
};
&axi_intc_0 {
xlnx,kind-of-intr = <0x0>;
xlnx,num-intr-inputs = <0x20>;
};
&amba {
zyxclmm_drm {
compatible = "xlnx,zocl";
status = "okay";
interrupt-parent = <&axi_intc_0>;
interrupts = <0 4>, <1 4>, <2 4>, <3 4>,
<4 4>, <5 4>, <6 4>, <7 4>,
<8 4>, <9 4>, <10 4>, <11 4>,
<12 4>, <13 4>, <14 4>, <15 4>,
<16 4>, <17 4>, <18 4>, <19 4>,
<20 4>, <21 4>, <22 4>, <23 4>,
<24 4>, <25 4>, <26 4>, <27 4>,
<28 4>, <29 4>, <30 4>, <31 4>;
};
};Save & close system-user.dtsi.
Build PetaLinux Project with SDKBuild the PetaLinux project to generate the components needed by QEMU in Vitis:
~/zcu104_prj/linux_os$ petalinux-buildAlso build an SDK for the PetaLinux project to get a sysroot for compiling the accelerated application in Vitis:
~/zcu104_prj/linux_os$ petalinux-build --sdkThe last step before jumping into Vitis is to create a directory structure to organize the necessary Linux components into.
Create a new directory in the desired location (top level Vivado project directory again for me), and boot and image directories:
~/zcu104_prj$ mkdir -p linux_components
~/zcu104_prj$ cd ./linux_components
~/zcu104_prj/linux_components$ mkdir -p ./src/boot
~/zcu104_prj/linux_components$ mkdir -p ./src/imageCopy bl31.elf, zynqmp_fsbl.elf, pmufw.elf, u-boot.elf, and system.dtb to the boot directory from the PetaLinux project (./linux_os/images/linux). Then rename zynqmp_fsbl.elf to fsbl.elf:
~/zcu104_prj/linux_components$ cp ../linux_os/images/linux/bl31.elf ./src/boot
~/zcu104_prj/linux_components$ cp ../linux_os/images/linux/zynqmp_fsbl.elf ./src/boot
~/zcu104_prj/linux_components$ cp ../linux_os/images/linux/pmufw.elf ./src/boot
~/zcu104_prj/linux_components$ cp ../linux_os/images/linux/u-boot.elf ./src/boot
~/zcu104_prj/linux_components$ cp ../linux_os/images/linux/system.dtb ./src/boot
~/zcu104_prj/linux_components$ cd ./src/boot
~/zcu104_prj/linux_components/src/boot$ mv zynqmp_fsbl.elf fsbl.elfThen copy boot.scr, image.ub, and rootfs.cpio.gz to the image directory from the PetaLinux project (./linux_os/images/linux).
~/zcu104_prj/linux_components/src/boot$ cd ../../
~/zcu104_prj/linux_components$ cp ../linux_os/images/linux/boot.scr ./src/image
~/zcu104_prj/linux_components$ cp ../linux_os/images/linux/image.ub ./src/image
~/zcu104_prj/linux_components$ cp ../linux_os/images/linux/rootfs.cpio.gz ./src/image
~/zcu104_prj/linux_components$ cd ./src/imageNext, an initialization script needs to be created for the system to tell it what hardware platform to load at boot up (the Linux system being emulated. Create an init.sh script in the image directory using your text editor of choice:
~/zcu104_prj/linux_components/src/image$ gedit init.shAnd copy the following into it:
cp ./platform_desc.txt /etc/xocl.txt
export XILINX_XRT=/usrThen create the platform_desc.txt file in the image directory using your text editor of choice:
~/zcu104_prj/linux_components/src/image$ gedit platform_desc.txtAnd add the name of the exported hardware platform from Vivado to it (without the.xsa file extension though):
zcu104_baseFinally, install the SDK generated from the PetaLinux into the linux_components directory:
~/zcu104_prj/linux_components/src/image$ cd ../../../linux_os/images/linux
~/zcu104_prj/linux_os/images/linux$ ./sdk.sh -d ../../../linux_components (make sure PetaLinux tools are still sourced)Create a Vitis workspace directory in ~/zcu104_prj/ then launch Vitis and select that directory was the new workspace.
~/zcu104_prj$ mkdir -p vitis_workspace
~/zcu104_prj$ source /tools/Xilinx/Vitis/2021.2/settings64.sh
~/zcu104_prj$ vitisCreate a new Platform Project targeting the exported hardware platform from Vivado. Open the platform.spr file from the Platform Project and navigate to zcu104_base > psu_cortexa53 > linux on psu_cortexa53. Set the paths as to point to the Linux components directory as outlined below (expect for the QEMU Arguments and PMU QEMU Arguments, leave them set to the default).
Use the drop down next to the Bif File line to generate a bif file then copy it to the ./linux_components/src/boot/ directory before setting it's path manually.
--> Bif File = ~/zcu104_prj/linux_components/src/boot/linux.bif
--> Boot Components Directory = ~/zcu104_prj/linux_components/src/boot
--> Linux Rootfs = ~/zcu104_prj/linux_components/src/image/rootfs.cpio.gz
--> Bootmode = SD
--> FAT32 Partition Directory = ~/zcu104_prj/linux_components/src/image
--> (Linux Image Directory)
--> Sysroot Directory = ~/zcu104_prj/linux_components/sysroots/cortexa72-cortexa53-xilinx-linux
--> QEMU Data = ~/zcu104_prj/linux_components/src/boot
--> QEMU Arguments = /tools/Xilinx/Vitis/2021.2/data/emulation/platforms/zynqmp/sw/a53_linux/qemu/qemu_args.txt
--> PMU QEMU Arguments = /tools/Xilinx/Vitis/2021.2/data/emulation/platforms/zynqmp/sw/a53_linux/qemu/pmu_args.txtI'm not sure why I had to copy the generated linux.bif from the default location to the ./linux_components/src/boot/ directory, but the Linux boot in the emulator would hang indefinitely otherwise. It seems like QEMU is looking for all of the boot components in one place.
Once the platform paths have been set, build the platform project using crtl+B or the build icon from the toolbar.
Vitis Application ProjectWith the platform project created and built, create a new application project based on the platform project just created in the previous step.
The application settings paths will auto-populate since the paths were already specified in the platform project before building it:
I'm using the vadd accelerated application template and simply modifying it with my own code to save myself a bit of time.
Open the vadd_dds.prj file and select either Emulation-SW or Emulation-HW for the active configuration build. I recommend using HW Emulation for accelerated applications because SW Emulation will emulate the entire system, it doesn't fully test the hardware design that's living in the programmable logic of the device.
Since I added a DDS compiler and gave its AXI Stream ports custom names by specifying an SP_tag for them, a system.cfg file needs to be created for the Vitis linker to map those connections out properly in the accelerated kernel:
~/zcu104_prj/vitis_workspace/vadd_dds_system_hw_link$ gedit system.cfgThen add the following:
[connectivity]
stream_connect = M_AXIS_DATA:krnl_vadd_1.dds_in
stream_connect = krnl_vadd_1.phase_out:S_AXIS_PHASEIn Binary Container Settings set V++ command line options to: --config ../system.cfg so that the Vitis linker knows where to find the system.cfg file when building/compiling the accelerated application. To access the Binary Container Settings, navigate to the Assistant window then under the drop down of vadd_dds_system > vadd_dds_system_hw_link > Emulation-HW, right-click on binary_container_1:
As you can probably tell, it is possible to place the system.cfg file wherever you'd prefer. You'll just have to specify it in the V++ command line options argument. The base directory it starts looking in is /<vitis workspace>/<application project name>_system_hw_link/Emulation-HW (since I have the active build set to HW emulation).
I find the most optimal directory is one folder up in /<vitis workspace>/<application project name>_system_hw_link/ so both HW and SW emulator can use it.
After setting the V++ command line options to point to the system.cfg file, click Apply and Close.
Since this post has gotten much longer than I originally anticipated, I'm going to save the explanation of my custom C++ code for controlling the DDS compiler for my next project post. For now, find the main application code attached below in vadd.cpp and the kernel HLS C++ code attached below in krnl_vadd.cpp. You can also skip adding the custom code and just run the Vadd accelerated application as is if you're just wanting to get familiar with running the emulator.
Once the custom C++ code has been added to the application and kernel, build the project by right-clicking on vadd_dds_system in the Explorer window and selecting Build Project. This will take a bit since HLS has to also run to generate the accelerated kernel.
Note: since HLS is being called under the hood here, be sure you've applied the Y2K22 patch if you haven't already.
Launch Debugger on EmulatorOnce the project has been successfully built, we can start the emulator. Select Xilinx > Start/Stop Emulator. Then click Start for the active build configuration:
The emulator always takes several minutes to boot up the QEMU Linux image for me, so I recommend a bit of patience here.
You'll see the boot progress in the Emulation console window, and once fully booted, you'll see the Linux command line prompt:
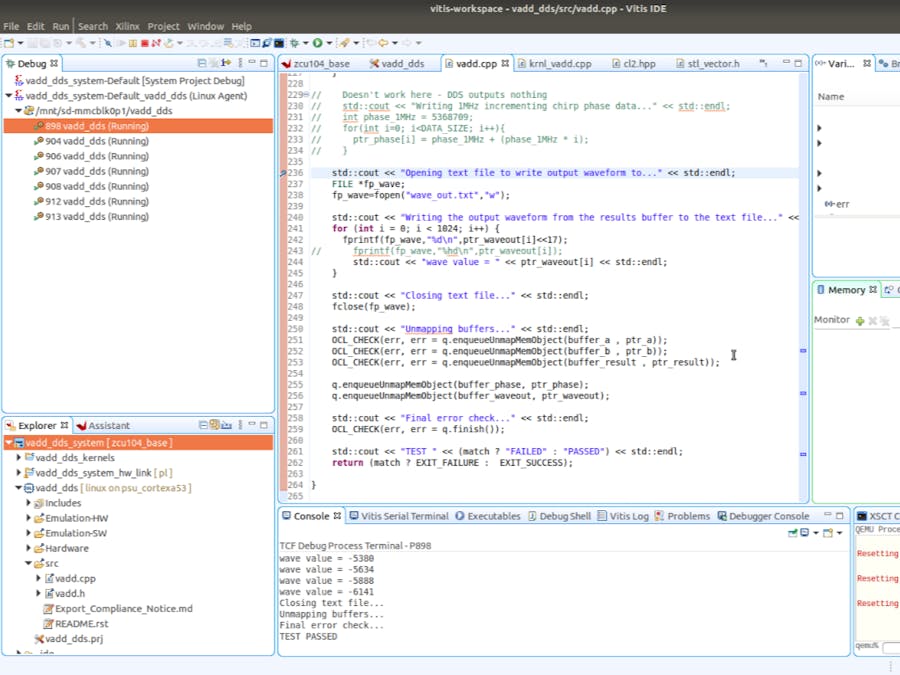
With the emulator started, we can now launch a debug session of the application on it. Right-click on vadd_dds_system in the Explorer window and select Debug As > Launch HW Emulator.
Just like with any other debug session, it will launch the application and stop at a breakpoint set right at the beginning of the main function:
You can step through your accelerated application and utilize tools such as the variables and memory monitors. Once the accelerated application has been ran, and affects it might have had such as created files will be reflected in the emulated Linux image in the Emulation Console.
Terminate the debug run and disconnect using the red square icon and red N icon in the toolbar:
Since I had the output from my DDS compiler written to a text file, I was able to transfer it to my host machine from the emulation console using a file transfer command such as scp. Run ifconfig on the host PC after the emulator is already running to see its local IP:
scp /mnt/sd-mmcblk0p1/wave_out.txt <host user>@10.xxx.xx.x:/<desired host location>I then simply used LibreOffice Calc (Excel) on my host machine to plot the output data from the DDS compiler to verify it:
You can make any changes you would like and rebuild and relaunch a debug run of the accelerated application with the emulator still running. Once done however, you can stop the emulator the same way it was started: Select Xilinx > Start/Stop Emulator. Then click Stop.
And that's it. I do plan to use this project as a reference for most of my emulations, if I don't use this exact workspace itself before transferring the code to my Kria projects. I've gotten questions of how to run emulation for Kria applications and this is the best solution that I've found so far.
Stay tuned for my detailed explanation of what all is happening with the DDS code here.




Comments
Please log in or sign up to comment.